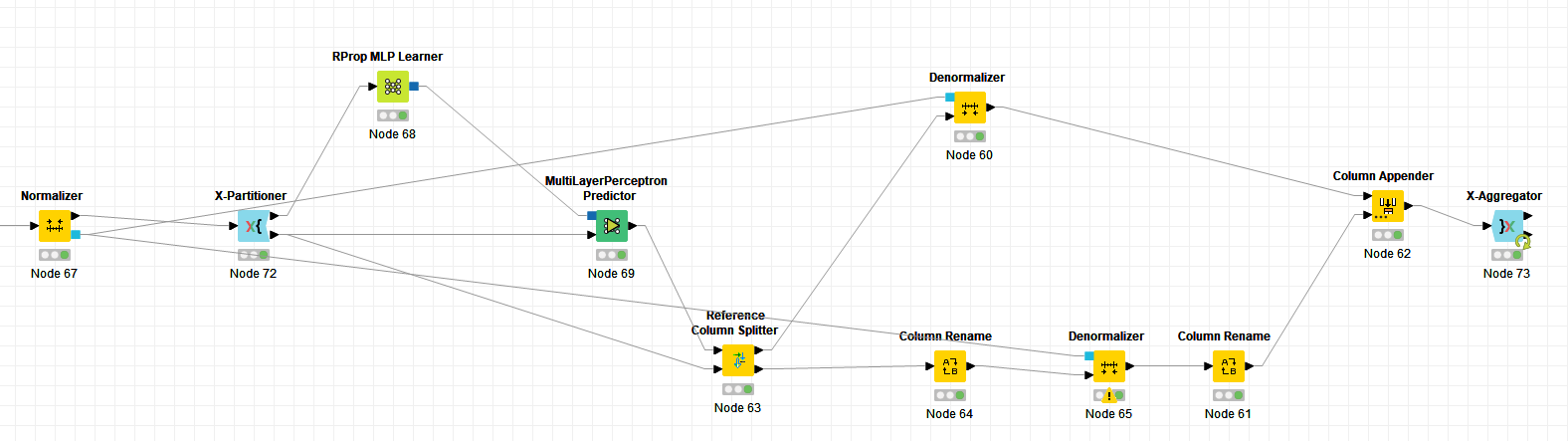
Please find attached my version. Could someone please tell me if the two nodes are in the correct position?
In my opinion it is - because I want to denormalize the results of each iteration.
In addtion, is the result of the X-aggregator the average of all iterations?
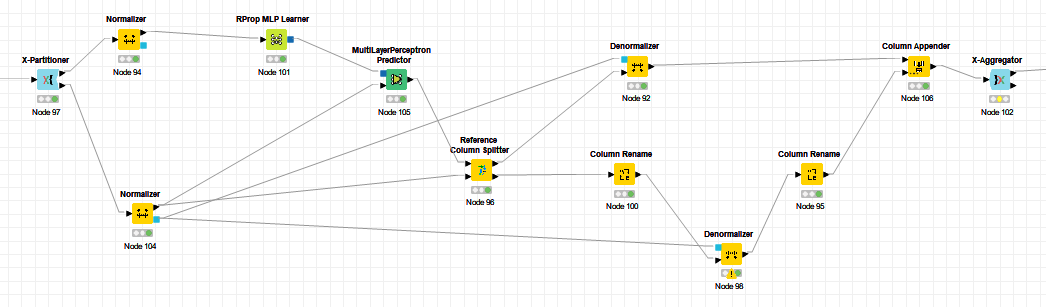
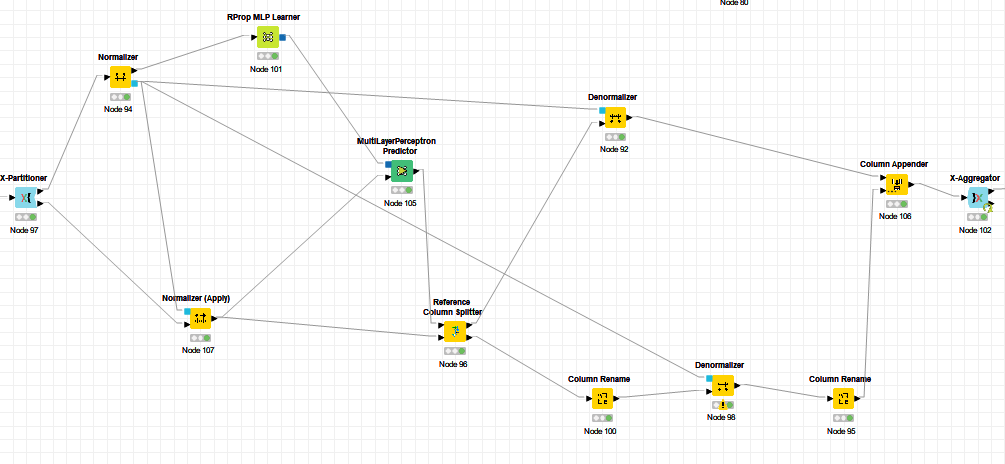
Strictly speaking, one should not normalize the data before splitting it into training and testing sets but after splitting, because it introduces a bias towards better results, specially when working with small datasets. Thus normalization is calculated on the training dataset and applied on the testing set at every data partitioning.
The workflow needs hence to be rearranged so that a separate normalization is done for every step of the X-partitioning loop. Tha aim of X-partitioning or Leaving-K-Out (LKO) is to evaluate the quality of your machine learning approach as if K different tests were achieved independently. The aim is not to generate a final model. It doesn’t matter hence if normalisations are achieved separately on data partitions within the loop and hence differently.
If your model turns out to be performant based on the LKO test, then you could use the whole dataset with the same normalization in this case, to train your final model to share or put it in production, but this is done only as the final step.
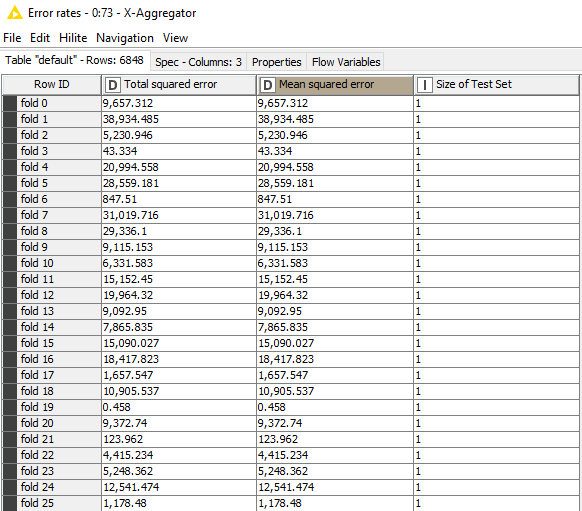
Concerning your second question, how did you set your X-partitioning ? If you are doing just a Leaving One Out partitioning (as it seems to be from column “Size of test set”), the total and the average Square Errors are the same. I guess this is why.
Normalization is calculated on “only” the training set and any normalization or denormalization should be based on “just” this training normalization model.
It is normal to get a warning saying that “Normalized value is out of bounds” if some of your test set descriptors had values beyond min or max values in the training set. Normalization should be achieved in before training a NN to avoid biasing the training towards descriptors with highest scales, given that this affect the estimations of the chosen Error Function, for instance in this case MSE. Better than normalizing using the min-max choice, please chose the z-score, which is not much less affected by possible outlier min max values either in the training set. Imagine that you have in one of your imput descriptors a value that is extremily high or low, compared to the underlying distribution of you descriptor. The min-max normalization would get completely wrong regardles of the amount of data you have, whereas the z-score normalisation (also called Gaussian) would be much less affected.
I hence recommend to use a z-score normalization. Thus you should not get this “Normalized value is out of bounds” warning.
Thank you very much for your quick reply.
When using the z-score, I can not execute the following MLP Learner.
Error: Domain range for regression in column goal not in range [0,1]
Do you have any idea how to solve this?
But you are right, I do not get the error “Normalized value is out of bounds"
I do not use RProp MLP learner & Predictor nodes. These two nodes are to me too simplistic to implement a NN model. I normally use tensorflow and Keras. Is there a reason why you are using these two nodes ? I would strongly recommend to move to Tensorflow or Keras.
I’m really sorry I cannot be of more help with the RProp MLP learner & Predictor nodes.
Thank you anyways.
You mean using the Keras and TF nodes extension of KNIME?
I never worked with it and so is there any documentation how to build a simple NN with these nodes?
I just need to replace to Learning and Predicting node by several nodes of Keras and TF - right?
What I meant is that you could switch to Tensorflow or Keras within KNIME
Please have a look at this previous recent post where I explained how to implement a normalization using Keras within KNIME. It is not exactly the same problem as yours but you could easily adapt it to do the same as what you want to achieve:
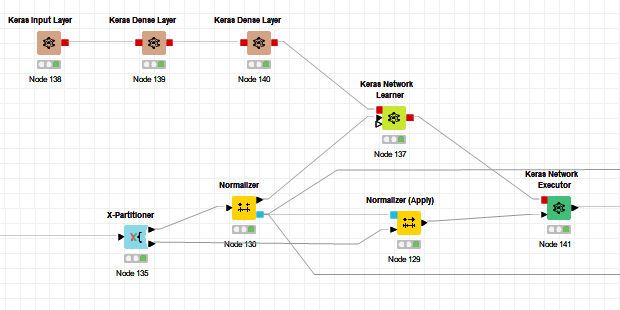
I really enjoy KNIME I managed it to get things running:
Now I try to figure out how to set up the different nodes properly.
I have 11 input parameters (columns) and an additional target value (numeric).
So I have chosen:
Keras Input Layer:
Shape 11
Kerase Dense Layer:
Input tensor: input_1_0:0 [11] float
Units 12
Activition function Sigmoid
Kerase Dense Layer:
Input tensor: dense_1_0:0 [12] float
Units 1
activition function Linear
Something must be terribly wrong as I receive totally wrong predictions.
All inputs are numeric values the target value can’t be negative. But my predictions are




 !
!