HI. No the workflow is to get you started, I suggest that you check the parametrization you have in Python and check the parametrization in KNIME’s node, then make the adjustments you need.
The numeric socreer gives multiple numeric criteria that you may use to optmize you hyperpartameters, you have to be able to pass the parameter to the loop end, you’d need to tweak the last two nodes to get what you need. Hope I’m clear
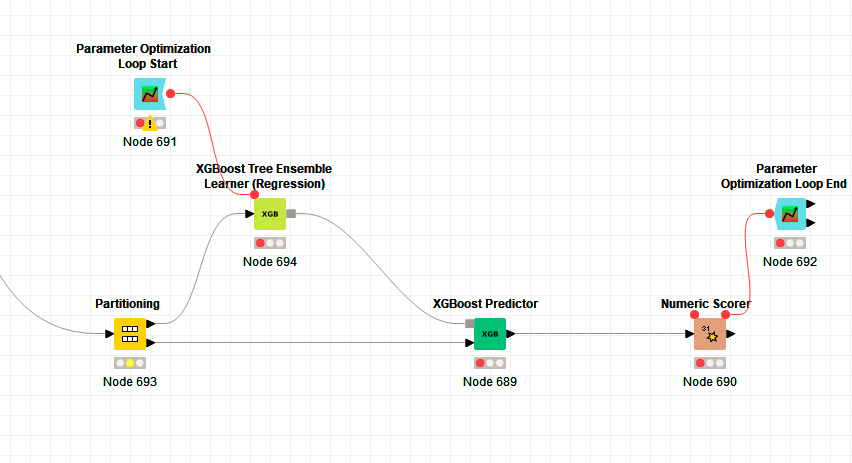
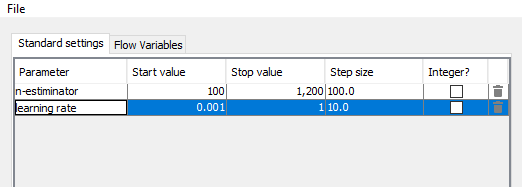
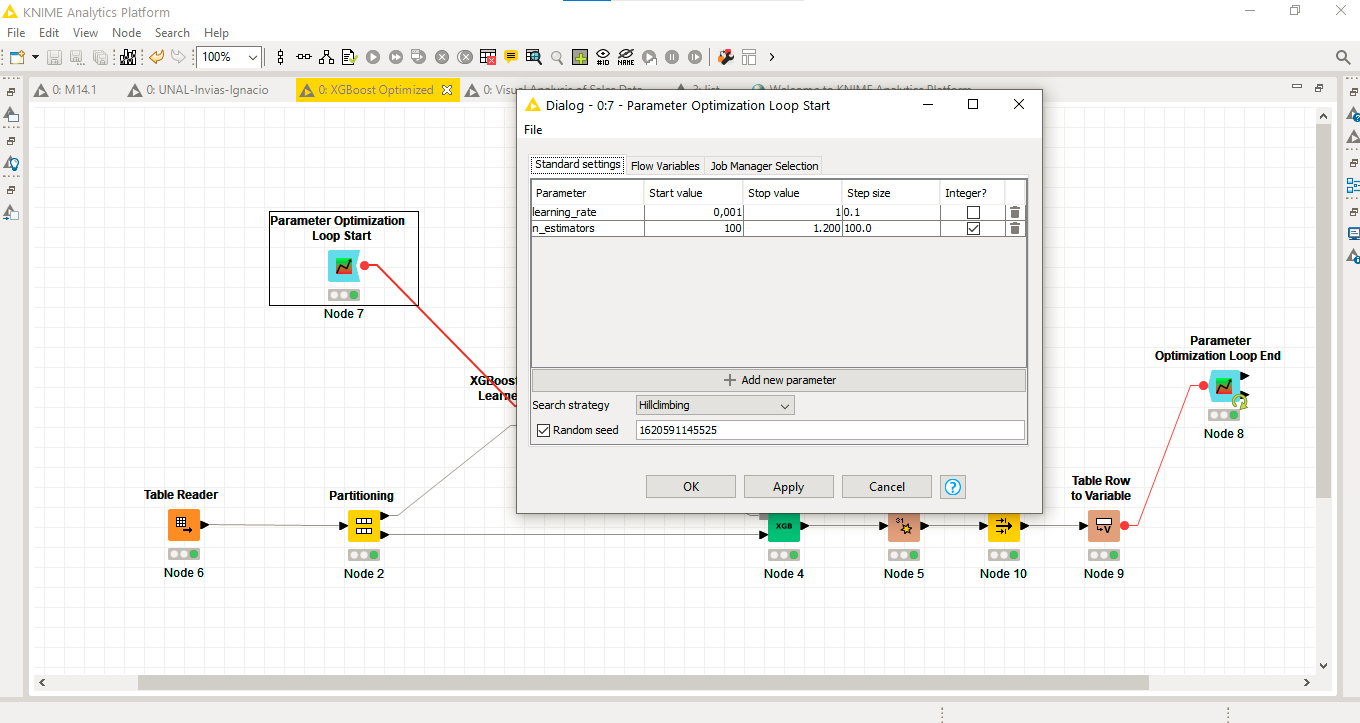
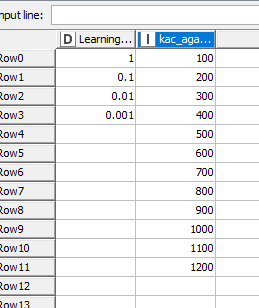
The learning rate in Knime is the eta parameter, I guess that you want tho check learning rates between 0.001 and 1 with a step increment of 0.1. What are the n-estimators?
The optimization loop minimizes the root mean square edrror by trying different learning rates between 0.001 and 1 with a 0.1 step and varying the number of trees between 100 and 1200 with a 100 step.
Please do not use the workflow “as-is”. Any type of parameter optimization like this will lead to a completely overfit model because you are optimizing for one single train/test split. . The model needs to be evaluated by cross-validation for example by taking the median of your target metric over all cross-validation loops. So inside the parameter optimization loop you need a CV-loop.
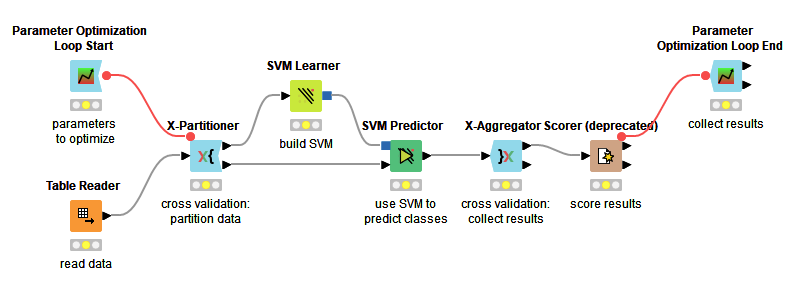
Absolutely!!. It was meant as a starting point. Regarding @kienerj suggestion you can check the EXAMPLES Server 04_Analytics>11_Optimization>07_Cross_Validation_with_SVM_and_Parameter_Optimization
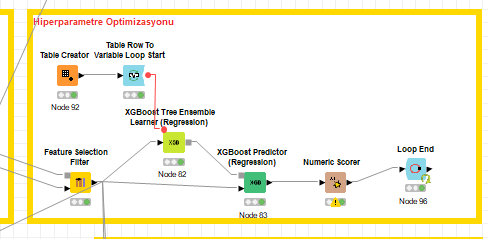
beacuise parameter optimization loop method is too long for best parameters so ı want to use this method and ı want to use cross validation in front of learner and predictor nodes is it posibble ? becauise i couldn’t it
This of course needs to be further extend as all feature selections steps must also happen only on the training set.
Advanced topic:
I must also add that in case of parameter optimization I generate the cross-validation splits just once and apply them via reference row filtering and group start. The reason for that is that the X-Partitioner is very slow as in that it repeats the row splitting for every iteration which significantly impacts runtime.
You probably do not use the same seeds (random states). Also there might be a slight difference on how default parameters are set in scikit vs knime.
If a loop takes to long use random search and not grid search.
br
 square is 0.35
square is 0.35