I have encountered a problem, i’m trying to extrapolate text from a PDF but when trying to append it in a xlsx file i get the following error message:
“Execute failed: The maximum length of cell contents (text) is 32,767 characters”
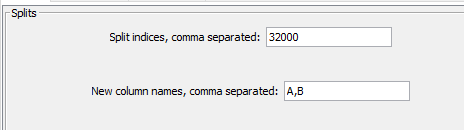
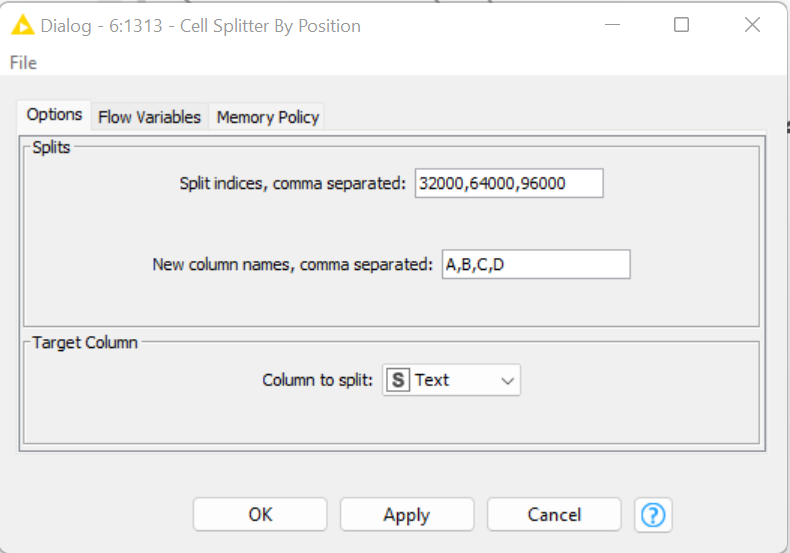
I tried with the cell splitter by position but without success, browsing the forum i saw there is a possibility to stop a column at 32000 char and then make a new column, but where do I have to configure it? because the cell splitter options just ask me for a split indices not a char count.
Thank you in advance
Hi @gabriele,
Maybe you can provide an example?
Hard to say without seeing the data.
But from the error message you have to split it further (just add additional points in thr cell. splitter e.g. 32000,64000,96000
The input data is a raw text (27 pages) extracted from 152 pdf.
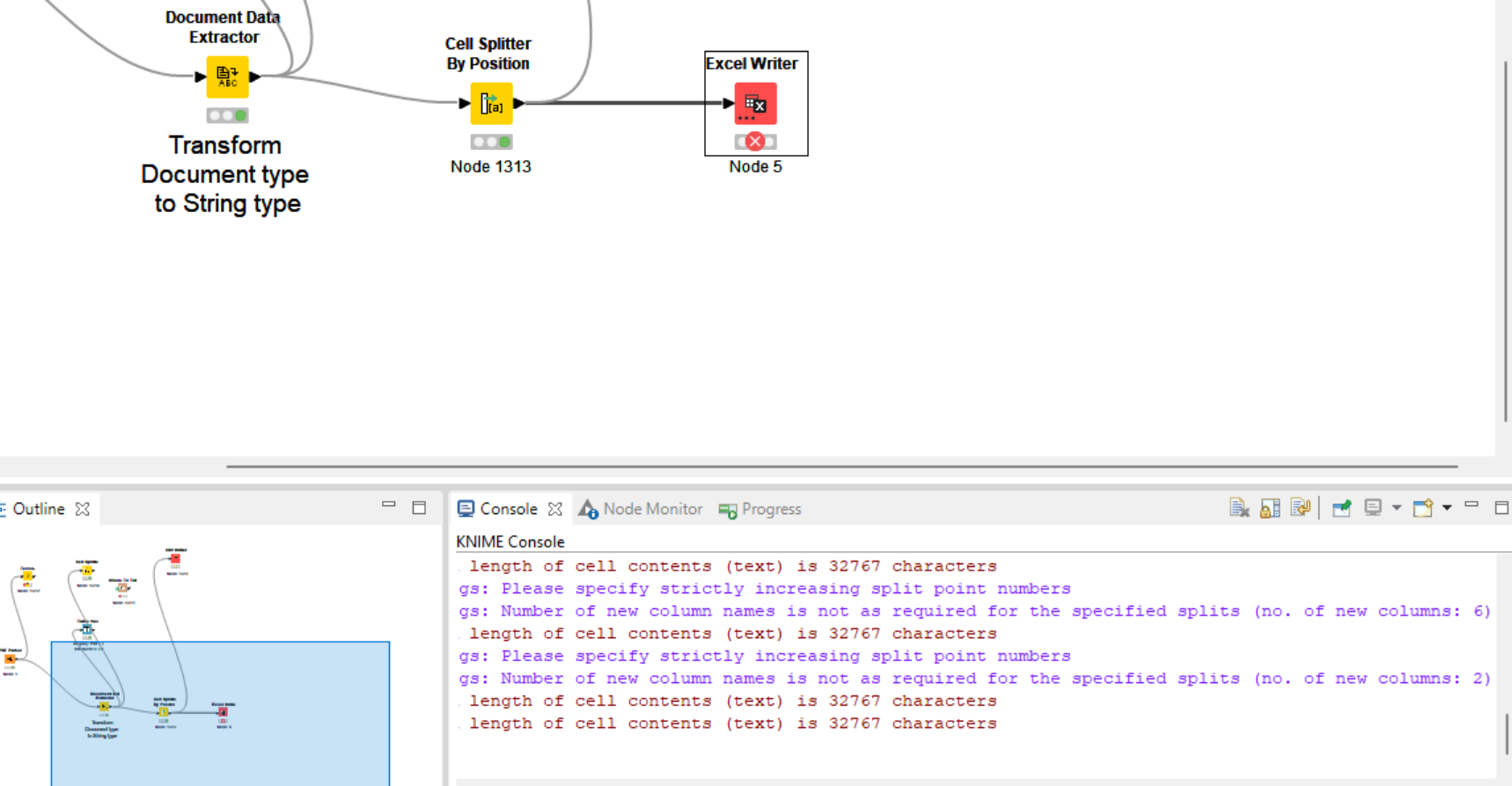
So i have 152 row with a Text column made by XX Char.
I use the split text to write an xlsx with less than 32.767 char in this way
I believe this is a problem that some of us have already experienced and perhaps deserves its own component to be addressed. So please find below a link to the component that I implemented to generically solve your problem. The component has a menu to select the column to split cell strings and choose the maximum number of characters desired per new substring. The component generates from there as many columns as needed to contain all the substrings of the initial string:
The following workflow illustrates the use of the above component:
This component has the advantage of preserving word integrity so that words are not split during the string splitting process.
I hope this component solves your sentence splitting problem. If not, please contact us again to help you further, perhaps with your own data if you can upload it here.