Dear Community,
My aim is to retrieve search results from the guardian API, with the following workflow being an example (retrieving RSS feeds from NYT):
Extraction and Tag Cloud Visualization of Named Entities from New York Times News Feeds – KNIME Hub
I am using this Guardian API request generator:
Guardian API scraper - KNIME Analytics Platform - KNIME Community Forum
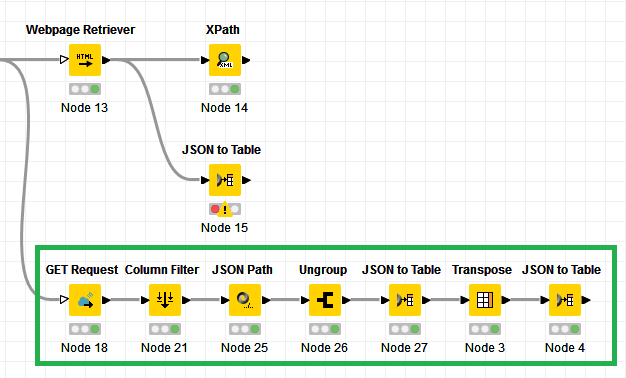
Then, I use the ‘Webpage retriever node’ to translate the results into XML format. And would like to use the Xpath node, just as in the example of the NYT, to create seperate rows for each search result.
However, now my problem is that the Xpath does not recognize the attributes since the generated XML looks like this:
{“response” : {
"status" : "ok",
"userTier" : "developer",
"total" : 117,
"startIndex" : 1,
"pageSize" : 10,
"currentPage" : 1,
"pages" : 12,
"orderBy" : "newest",
"results" : [ {
"id" : "books/1920/dec/29/fromthearchives.poetry",
"type" : "article",
"sectionId" : "books",
"sectionName" : "Books",
"webPublicationDate" : "1920-12-29T23:46:12Z",
"webTitle" : "Archive review: Poems by Wilfred Owen",
"webUrl" : "https://www.theguardian.com/books/1920/dec/29/fromthearchives.poetry",
"apiUrl" : "https://content.guardianapis.com/books/1920/dec/29/fromthearchives.poetry",
"isHosted" : false,
"pillarId" : "pillar/arts",
"pillarName" : "Arts"
}, {
"id" : "news/1920/dec/29/leadersandreply.mainsection",
"type" : "article",
"sectionId" : "theguardian",
"sectionName" : "From the Guardian",
"webPublicationDate" : "1920-12-29T00:04:38Z",
"webTitle" : "From the archive: A revelation of the pity of war",
"webUrl" : "https://www.theguardian.com/news/1920/dec/29/leadersandreply.mainsection",
"apiUrl" : "https://content.guardianapis.com/news/1920/dec/29/leadersandreply.mainsection",
"isHosted" : false,
"pillarId" : "pillar/news",
"pillarName" : "News"
}]
}
}
I believe the problem are the double quotation marks. But I just cannot figure out how to handle this (absolute newbe).
Your help is very much appreciated!