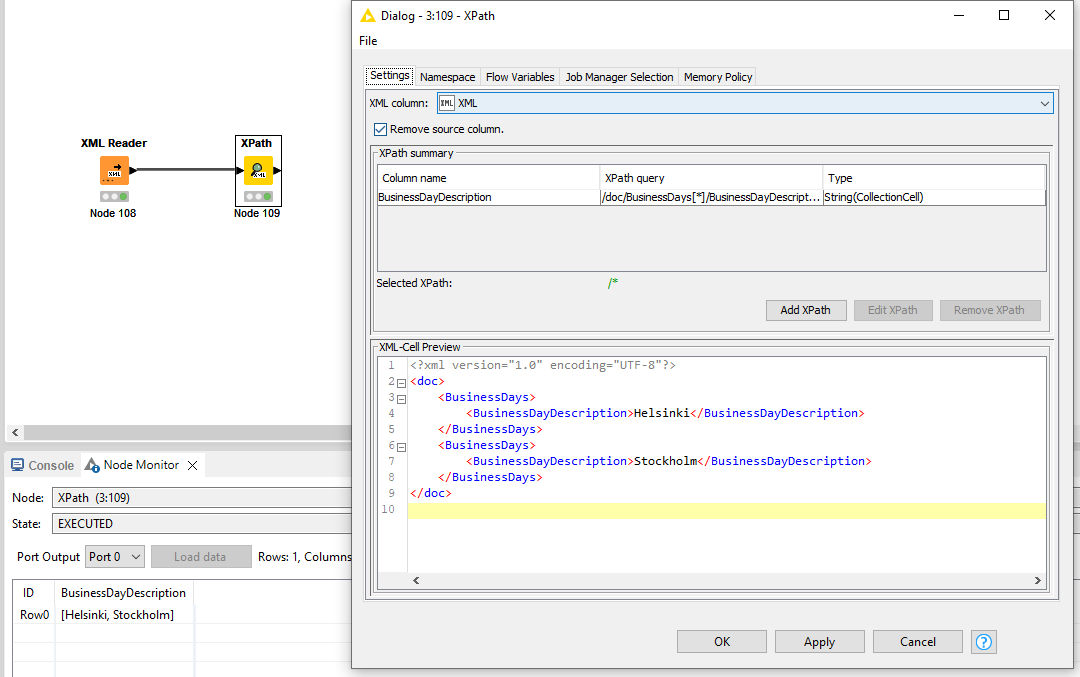
I have a big XML file with multiple branches. One of these branches has the tag BusinessDayDescription 2 times, and the rest has it only once. When I do a parse with xpath, and add the tag as multiple columns, it creates 2 rows on the table, mixing up the rest of the data. on the other rows.
How could I parse the data so, that if it has multiple tags with the same name, that it would create 2 separate columns of them and not add 2 rows?
This is the part of the XML that is giving me the headache. xpath extracts both, and adds the stockholm to second row, and shifting the next ones one row down…
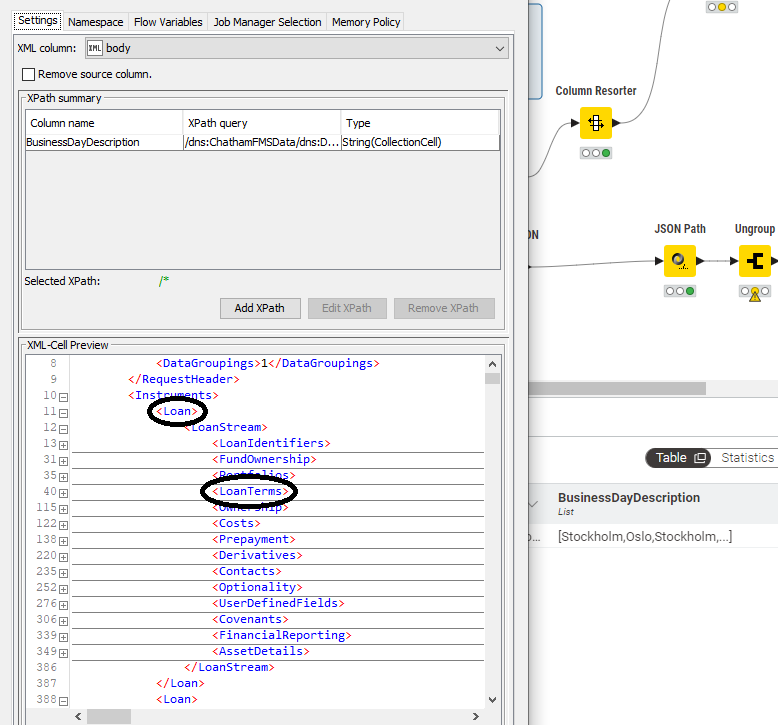
@ArjenEX Tested it, and it is working but its making a collection of all of the loan branches Each loan branch should be an own row in the table and the underlaying Businessdaydescription an own collection in that row.
It’s a bit hard to judge without seeing the full structure but in that case I would output each <Loan> as NodeCell first and afterwards query for the BusinessDayDescription. That should help keeping the correct relationship between the two.
HI @ArjenEX Thanks! decided to split the loans into own node collections, so I would get the loan specific data out. So got it to work
But than ran into second use case where this does not work, when the tag has subtags with identical names. Im suprised there is no automatic node for translating XML to table, as the structure is there, it should be an easy task to just convert the whole XML into a table format
XML example.txt (30.8 KB)
Hi @ArjenEX. Here is an example of one full loan branch. Is there any way to get this into a table format, so all the tags presented would be as an own column? We can do the cleaning later from the table format.
@ArjenEX I was able to get it working Splitted the the loan sections in the XML to individual XML, then looped the XML s with string(multiple columns) xpath. This gave the desired outcome.
Thanks for the help, I would not have been able to figure it out without your hints!!