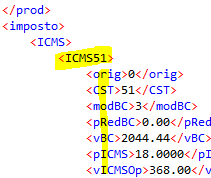
Hi there, Im facing an issue reading XML, where the files have different tags, for example there is a Tag Named ICMS but then they add a number at the end, ICMS10, ICMS51, etc, and as far as I know that end number its really variable, but the content fields for those tags are standard for any ICMS “type” see the image below; is there a way of hadling this? like an option of “read all” or similar?
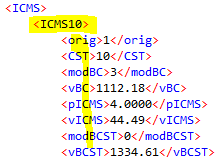
as an example these two XML’s. The problem Im facing is that certain TAGs such as ICMSXXX can vary and this doesn’t depend on me, but I need to extract what’s inside that tag, and those never change…
Im trying to XML to JSON and work from there but glad to have any other perspectives
Im thinking that maybe I can use something like adding asterisks or specific expression in the ICMS part, for example, This is one of the Tags I require, but in the section dns:ICMSSN102 the last part of the tag is variable SN102, here there are “n” cominiations
Original tag
/dns:nfeProc/dns:NFe/dns:infNFe/dns:det/dns:imposto/dns:ICMS/dns:ICMSSN102/dns:orig
Example
/dns:nfeProc/dns:NFe/dns:infNFe/dns:det/dns:imposto/dns:ICMS/dns:ICMS**/dns:orig
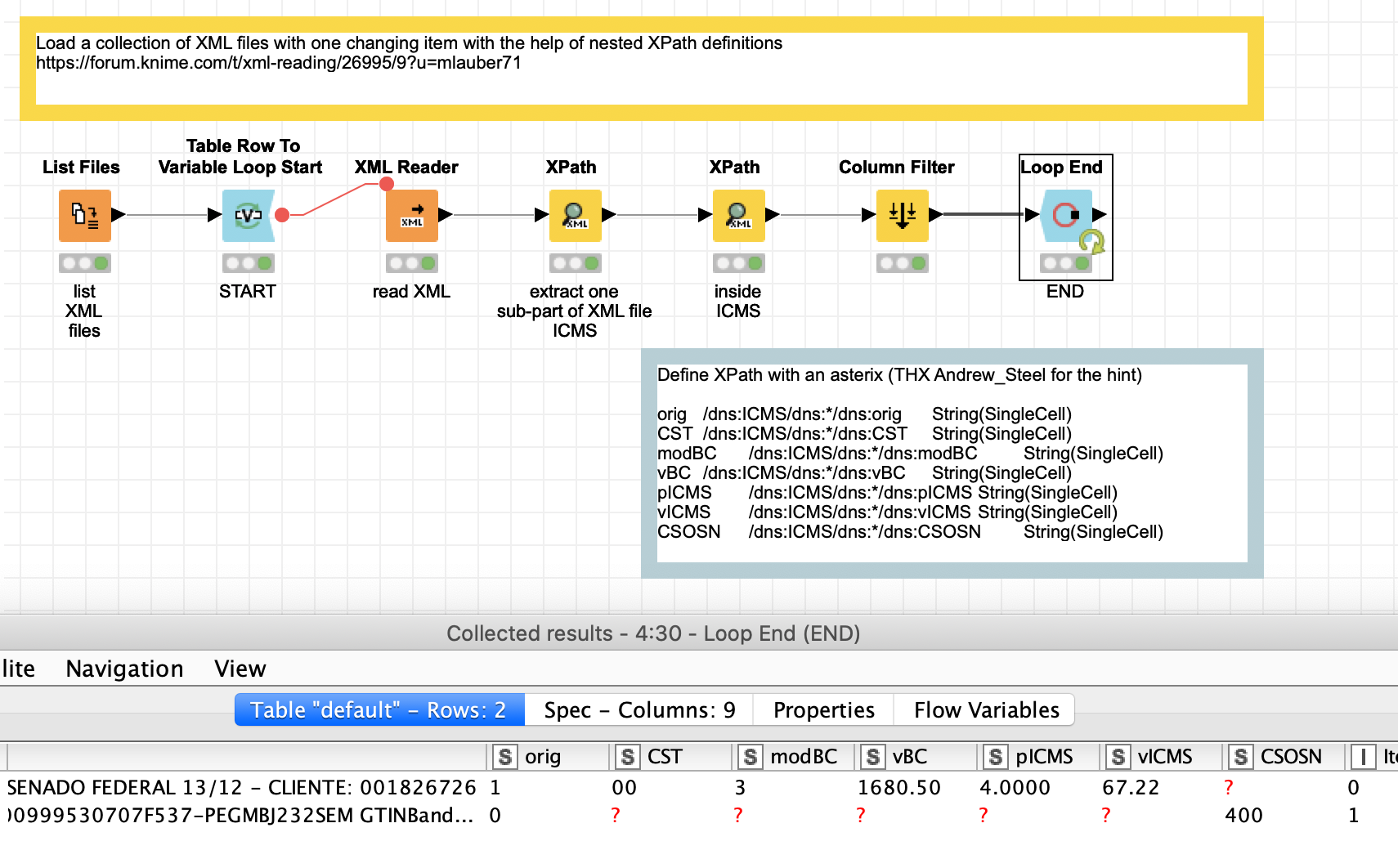
That is great @Andrew_Steel. XPath with an asterisk. I built a small workflow around the two sample files. It uses two steps of XPath - first to locate the overall ICMS part and then the sub-part with the single cells. Although I noticed changing cells so with more examples it might be necessary to extend that.
@GQRanalytics could you check if this suits your needs?