I’m relatively new to KNIME and the first thing I want to say is: “It’s so awesome!”. After a few workflows it appears as if there’re no limitations. Except there’s one thing I couldn’t figure out so far: Is it possible to validate xmls against a schema?
I have this growing pile of xml files (~1000/day) which I’ll use for … big data stuff Reading broken xmls interrupts the workflow, and of course it’s better to fix those files in the first place. But first I need to identify them, so they can be dealt with accordingly.
I want to validate the xmls (either in a separate workflow or to branch them off to deal with them and continue with the other files).
Welcome to the KNIME community. We are glad you like KNIME. We like it as well
Are you looking for something like XMLValidator node?
What is also worth exploring in your case are nodes in Error Handling category. Using Try/Catch nodes from it will avoid interrupting the workflow in case of a broken xml file
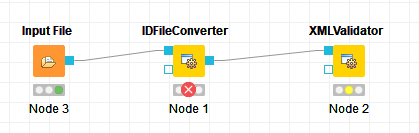
Judging from the name and it’s description, the XMLValidator is exactly what I’m looking for. Unfortunately I couldn’t get it to work. The list file node (or other nodes I’ve worked with so far) has output ports that are incompatible with the XMLValidator. In the OpenMS Extension I couldn’t find any equivalent nodes.
This forum question:
already covers Try/Catch nodes as workaround to workflow interruptions, which is useful information, but not what I want. (a xml being non-broken doesn’t necessarily mean it’s valid, right?)
From a NodePit link of XMLValidator node there is paragraph Best Friends (Incoming). There you can see that IDFileConverter node precedes XMLValidator node. Try to get it working with it and if you do not succeed I can give it a try although to not have much experience with XML files.
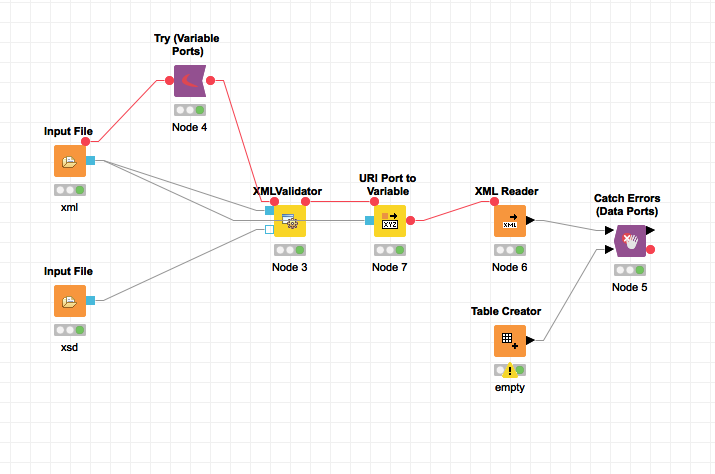
I was able to read a single xml and pass it to the XMLvalidator node. There are some things that still won’t work:
I wasn’t able to pass my Schema, yet it still validates?!
any modification to the xml breaks the IDFileConverter, even tho the xml structure is intact (the file reader doesn’t know which tags are required and which tags are optional). Opening those modified files with the XML-Notepad works fine.
the XMLValidator has no output connections (only the “Std Output”), so I’m not sure if/how I can access the success status of the validation
the Web Documentation linked in NodePit doesn’t load. That’s no issue, but doesn’t help either.
Maybe you can get it to work, but I can’t give you my xml files or Schema though.
AFAIK the nodes were never tested outside of the OpenMS file formats, though they should be general enough to also work for you.
Why can’t you pass the schema? It also has to be loaded with an Input File node and then passed
as secondary optional input (unfilled rectangle) to XMLValidator.
You do not need IDFileConverter, since this will only work on our file formats (this is what the message probably tells you when you hover over the red cross).
If you do not pass a schema it tries to choose from a set of included schemata (should only work for our file formats). Maybe it just checks a general XML structure if a foreign file format is passed without schema.
Yes, checking failure should be able to be catched by the try-catch nodes, that were already mentioned (you will have to show and use the hidden variable ports probably).
sorry for not responding, I was sick for a few days.
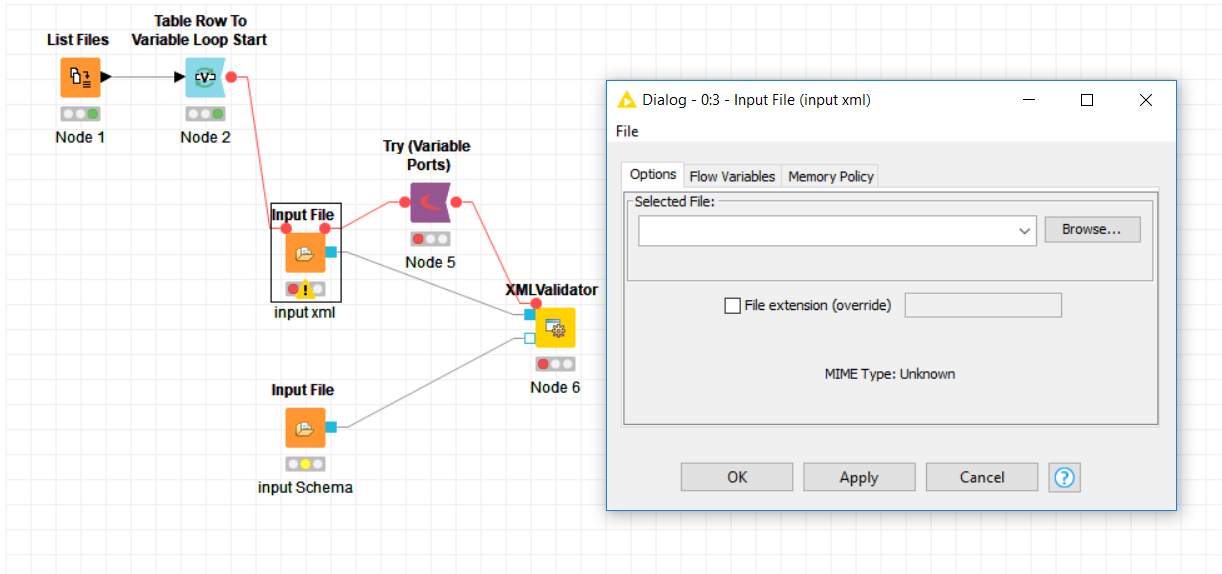
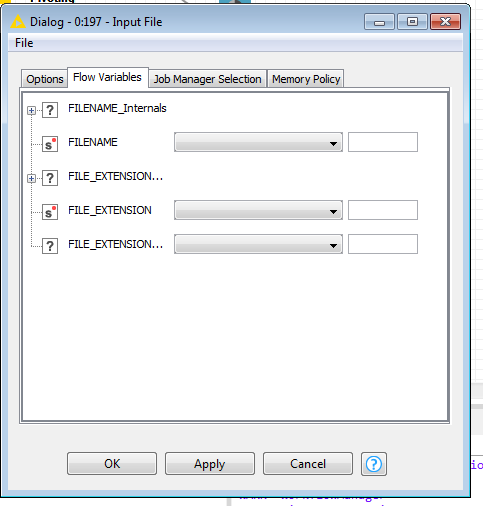
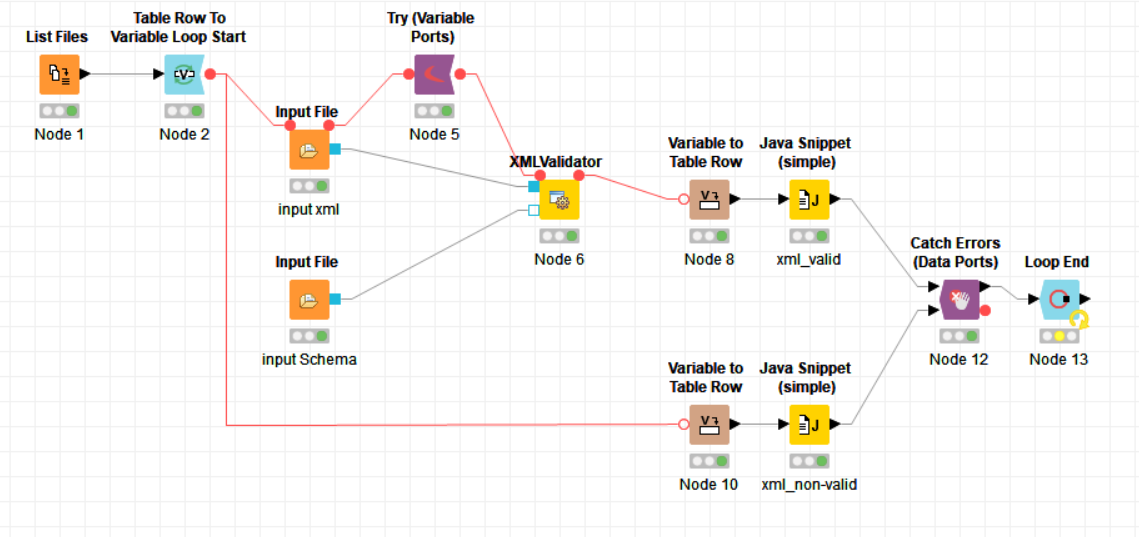
With your screenshot I was able to build a workflow that validates single xml files against the Schema. Then I proceeded to wrap it into a loop so I can validate an entire directory with the press of a button, but unfortunately the file box of the Input File Node cannot be controlled by Flow Variables.
Almost there! Do you know how I can get this last step done?
The loop output is the same as the loop input, except there’s an extra column from the Java Snippets that holds the information whether or not the xml is valid (1 = yes, 0 = no). Zeros will be put on the naughty list. Now that I’m writing this, I had the idea of using an Constant Value Column Node instead, but I’m not retaking the screenshot
The XMLvalidator is super slow (can’t expect it to be fast tbh) so I’ll put filter mechanisms in front of it to prevent xmls getting validated multiple times. If there’re other performance tweaks, let me know.
concerning speed, all you can do in KNIME is probably using a parallel loop instead
of a sequential one.
In the tool itself, one could allow multiple input files to be validated with the same schema,
so the schema has to be loaded only once. Although I don’t think this speed-up is worth the effort.
I wrapped the above workflow in a parallel chunk loop start and tested it on 900 xmls. It took 960s to complete. sequentially is ~1500s.
A coworker of mine uses the precompiled binaries of the libxml2 library and a .bat file for manual Schema validation, so I tested it on the same sample. It took 35s to complete.
The workflow we built is apparently only suitable for small samples. The best solution would likely be a program that validates the xmls (and moves + reports the non-valid ones) so that I can rely on the xmls being valid to use in KNIME.
Option 1: Move files out of staging folder after testing
XML validation should process all files in STAGING (folder only, not recursive) and based on xml assessment, move files to appropriate subfolder to prevent multiple assessments. Could write flags and read flags to avoid same but it seems you need the files sorted for further processing tbd. Your downstream processes could call the parent to process anything new in STAGING then handle the good/bad subfolder contents as desired.
Option 2: Integrate the use of libxml2 within your STAGING process. Call a shell script or python script or R script from within knime to use that library and return list with flags, then take action based on flags (set destination folder based on flag, execute move to designated destination subfolder, etc).
Option 2b: develop an optimized xml comparator node using that library and contribute it back to the community…
 Reading broken xmls interrupts the workflow, and of course it’s better to fix those files in the first place. But first I need to identify them, so they can be dealt with accordingly.
Reading broken xmls interrupts the workflow, and of course it’s better to fix those files in the first place. But first I need to identify them, so they can be dealt with accordingly.