This problem seems generic so I thought I’d start a new thread.
Here’s the workflow: Simple Web Scraper.knwf (147.3 KB)
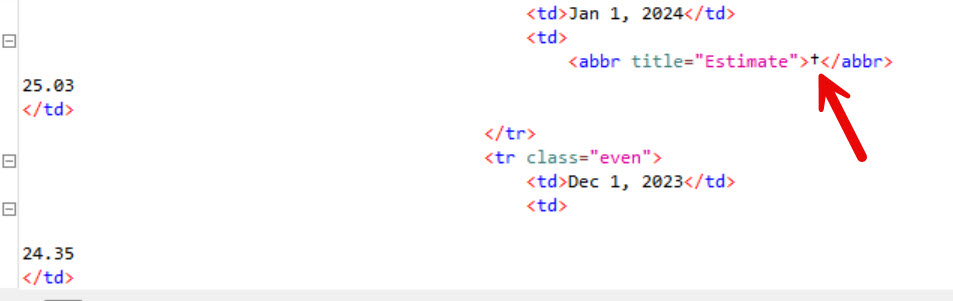
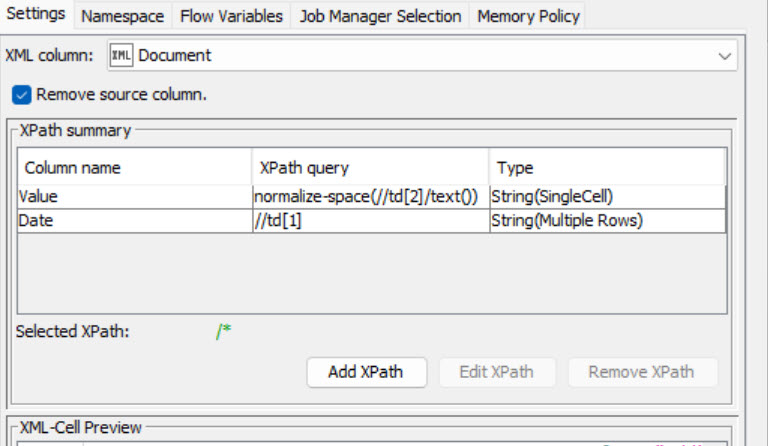
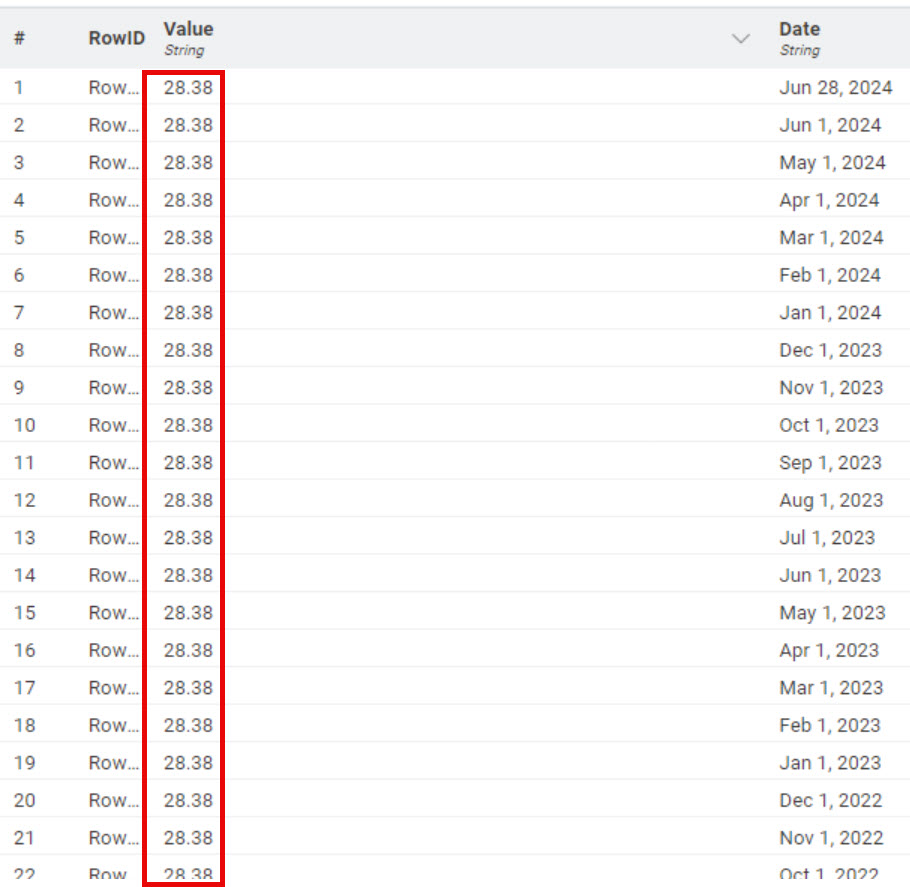
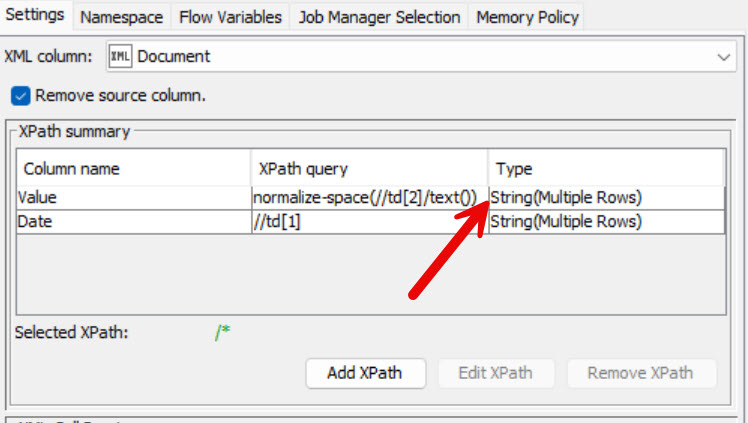
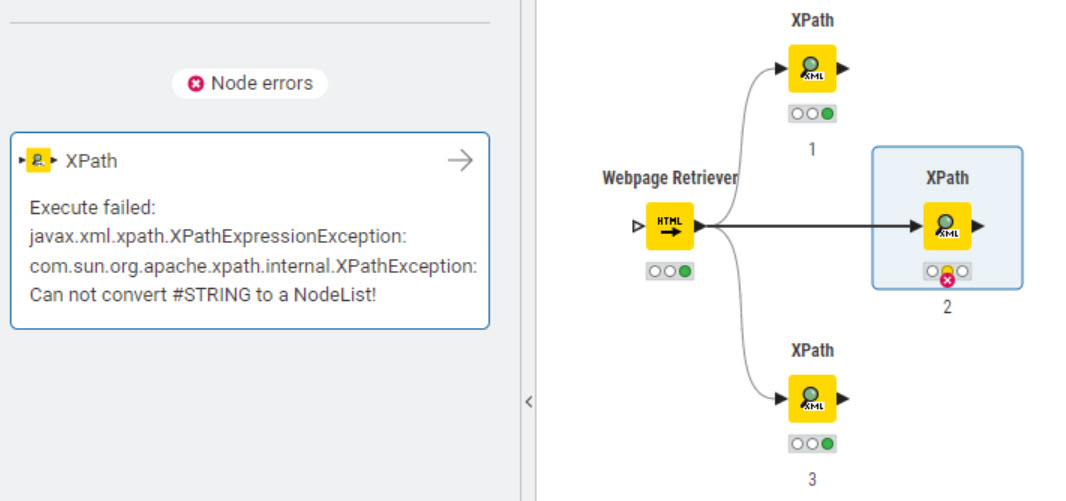
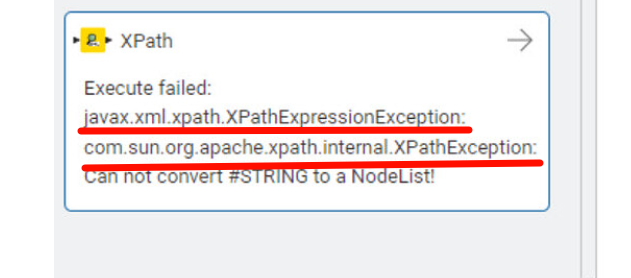
The xml is not very well formed. It consists of monthly data with an extra flag for the current year. There is a lot of extra white space in the value field. If I try to remove the white space the Xpath query won’t allow a list, only a single entry which gets stuck on the first data field. Here are a series of screenshots which hopefully will clarify the problem. I’ve done quite a bit of searching and haven’t found any help.
Hi @rfeigel ,
The situation you mentioned also exists in 5.2.5. The error prompt is that the underlying Java package reports an error. Here, it is not known whether it is caused by incorrect invocation of the package or there is a problem with the underlying package.
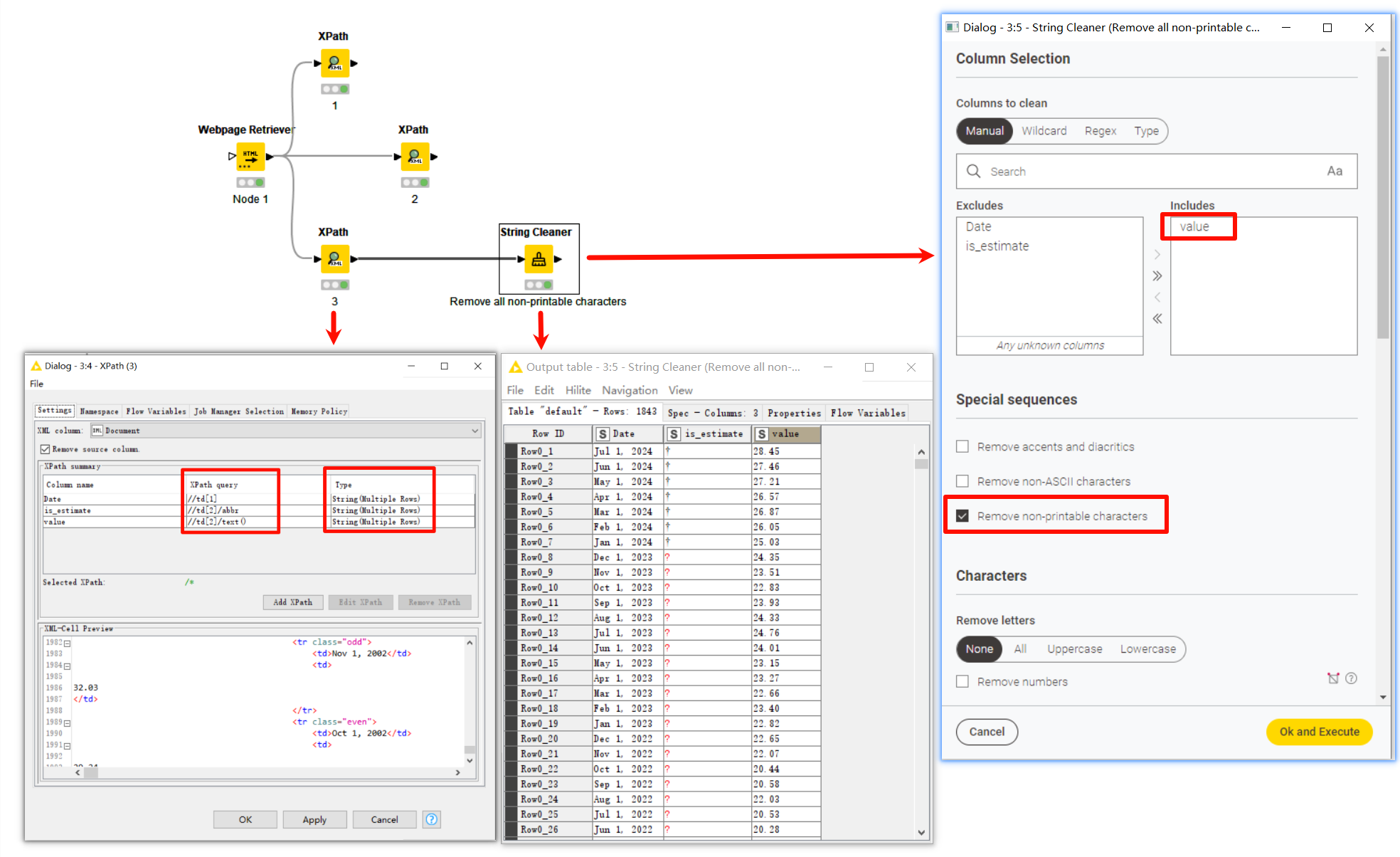
I found a way with less resistance. The processing of the string is not handled in “xpath”, but is processed externally using the “String Clean” node.
@rfeigel is an enthusiastic and perfection-pursuing person. Thank you for participating in the discussion. Under normal circumstances, I have never thought that an HTML page could be parsed as an XML document. I have also gained a lot.