Hello,
I need to extract the row string references (to extract the exls cell color data) from this XLM file (XLS file with XLM format). I’m a beginner on the topic but, with teachings, I can succeed. What is the “xpat value query command” to extract all “” present in the XLM file?
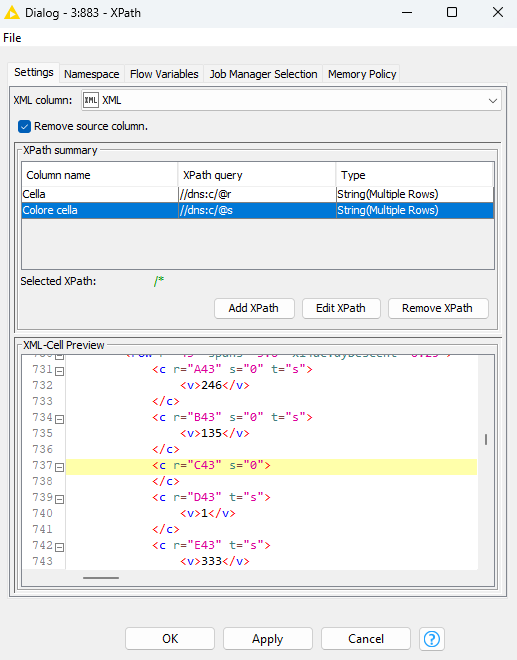
I’m not quite sure where the cell color is in your data… in general if you want to capture a value that is nested somewhere - let’s say you want to grab what is between and :
thankx @MartinDDDD your feedback, now i try it!
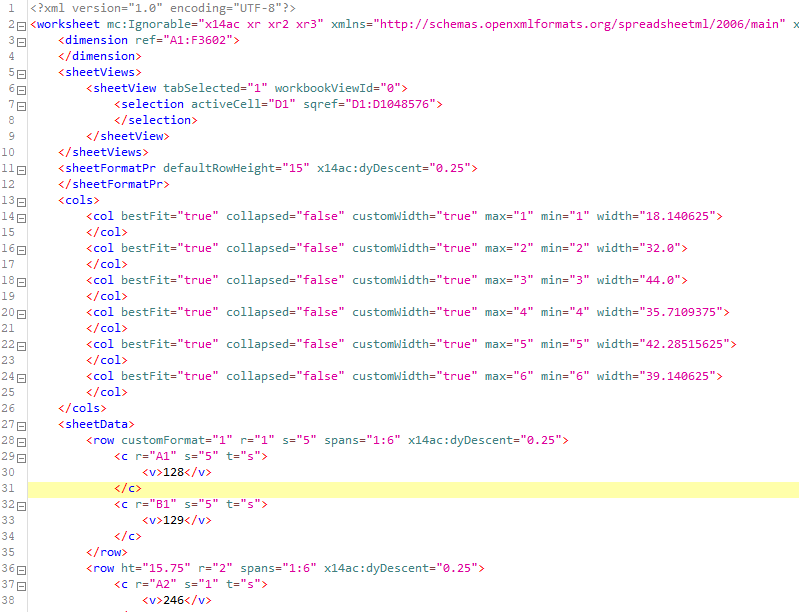
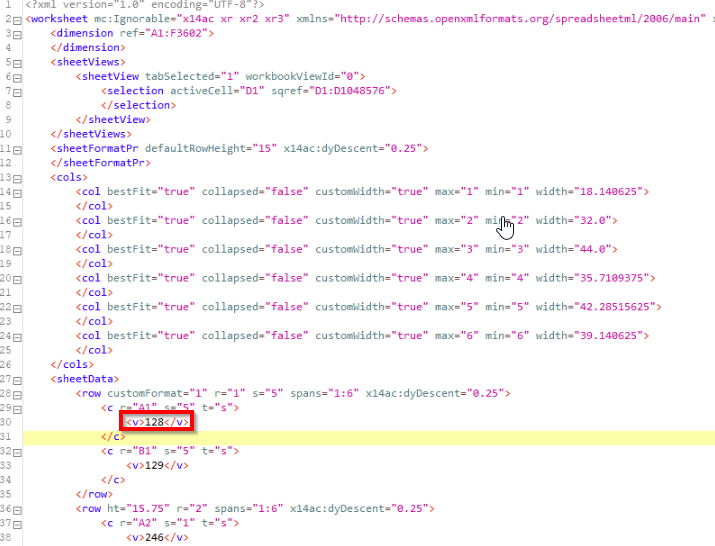
Do u know why i think there is a value color in string? Becasue i can do the chack with file xlsx master and i know, for exeple, the cells C5 and C9 are RED. Infact, the “s” value “=6”, in XML-cell same, are different rispect athers. Are u sure is not color referce?
C5
C9
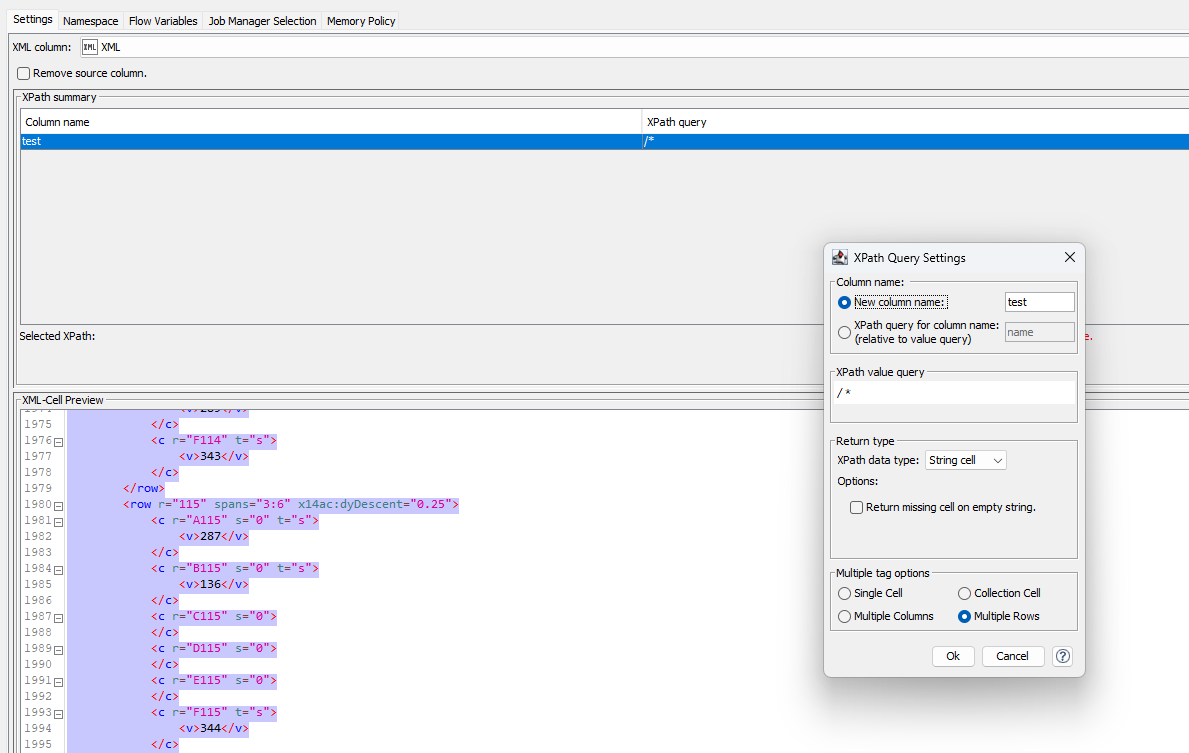
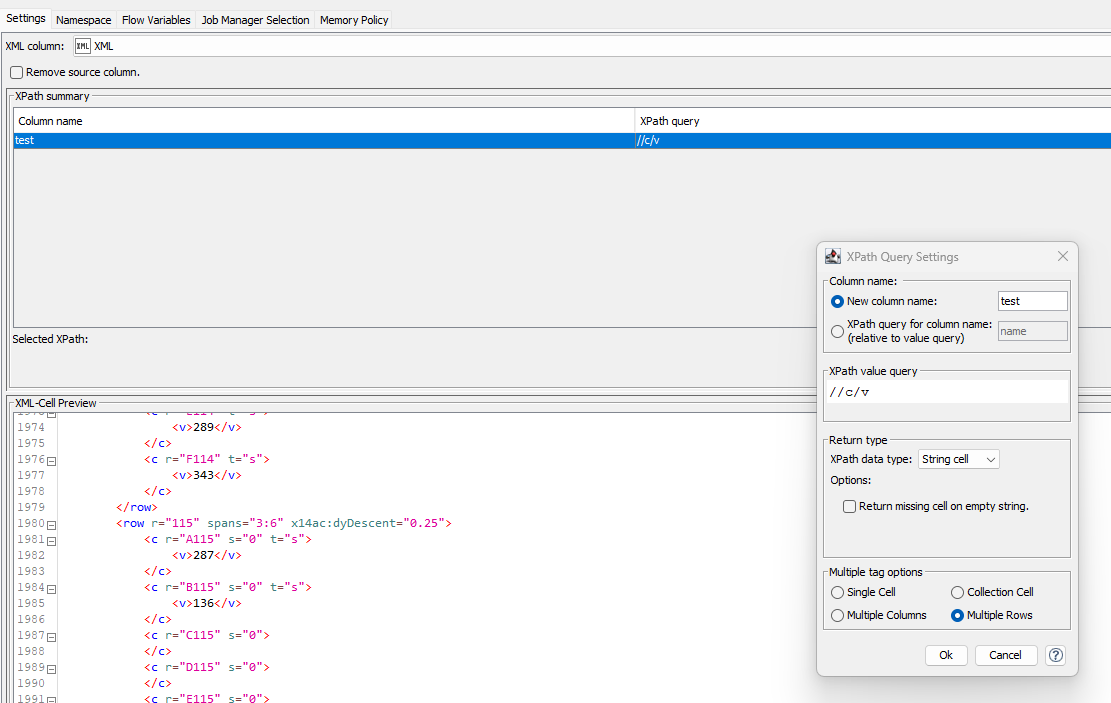
I use this suggest string " //c/v" but i haven’t all output row, only one!
I’m afraid I am not familiar with Excel XML structure to confirm (or deny) that the “c” tag does include color information…
I asked ChatGPT to create example data based on your image and with that I managed to do the following:
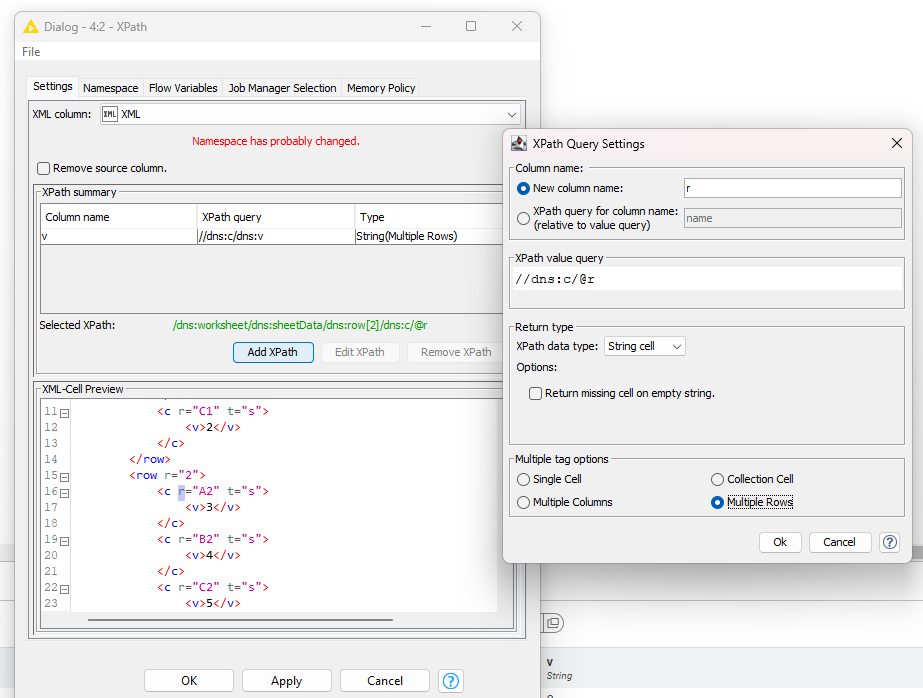
extract all the values between v tags
extract all the r attributes from the c tags:
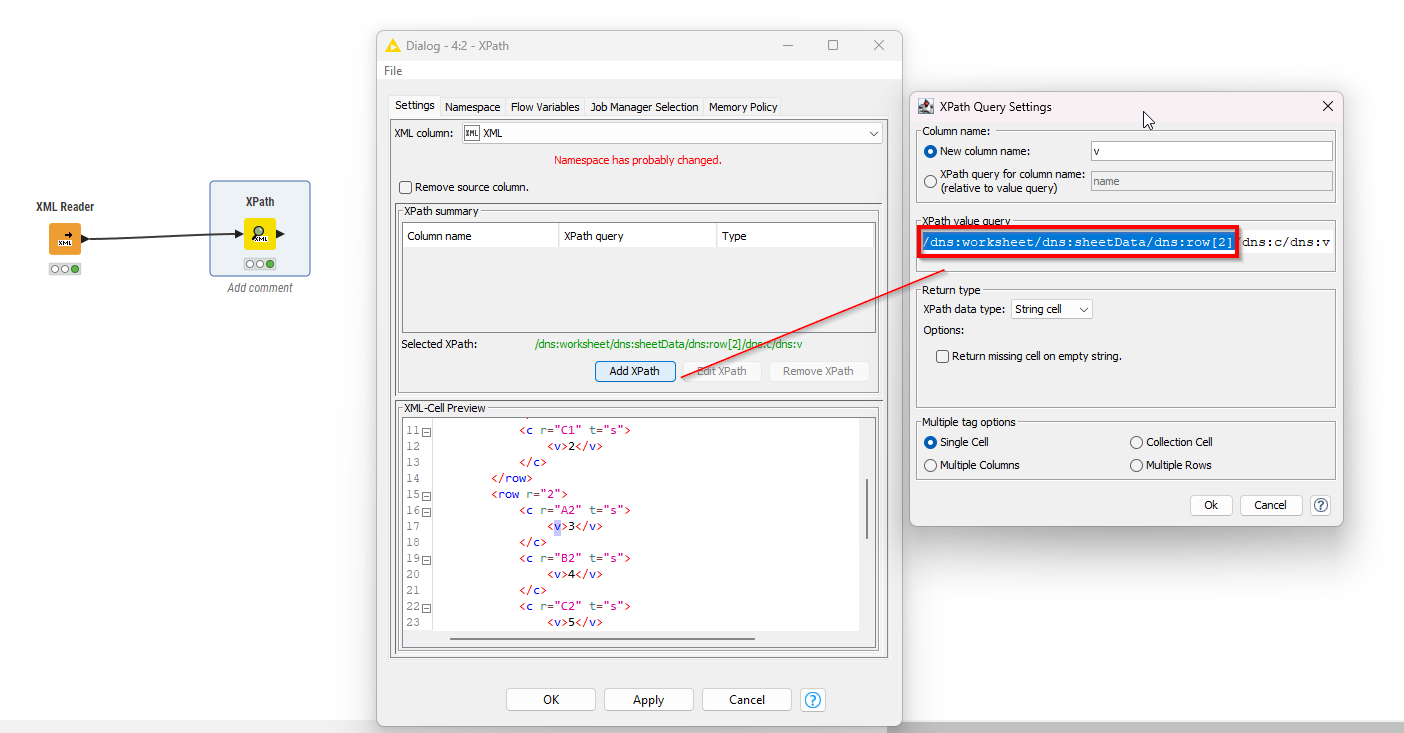
Get the v tag values: Select a v-tag so that it shows in green the Xpath. Then click the Add Xpath button so the window appears. Delete what I have highlighted in red box - so that only the part with /v/c (in my example with the weird dns in front of it…) stays. Finally make sure that there is a double-forward slash at the beginning. Also select to output into multiple rows as string cell:
You can try it with this example workflow. Note: By “selecting” the parts you want to extract you make sure you take care of this weird namespace thing (sorry have to admit I dont fully get why it’s dns:c/… for me…
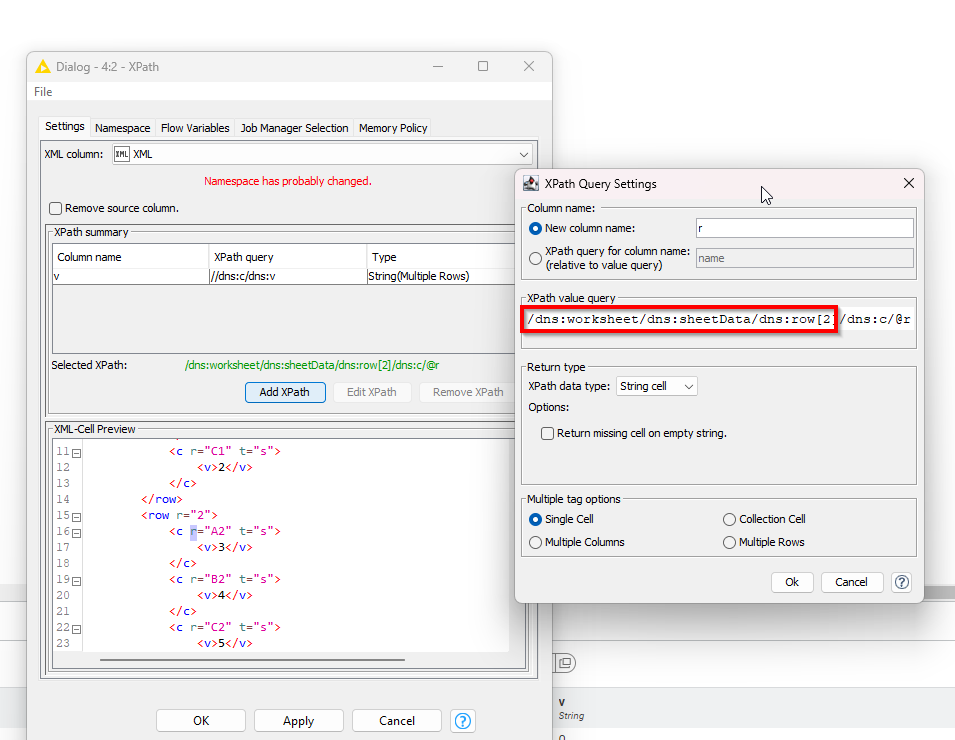
Not sure how to help you - the table does not show any missing values for the second Xpath query so it seems to return a value that is set for that attribute.
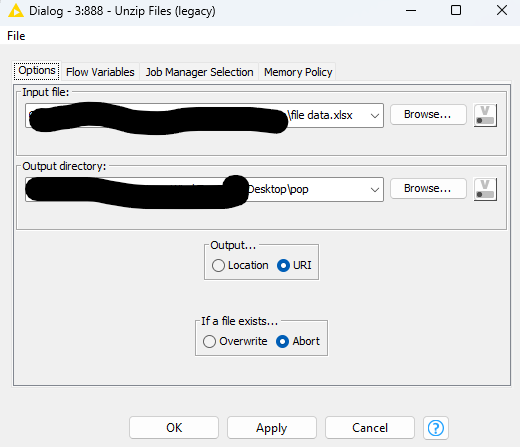
1-Create a new folder
2- you can use the node “UNZIP FILES (Legacy)”
3- configure unzip files ( legacy ) : set the file .xlsx and choose the output-folder
4- after esecute the node and look inside the folder all folders
5- look the root folder //xl/worksheet/sheet1.xml
6- the propriety set file .xlsx are in sheet1.xml
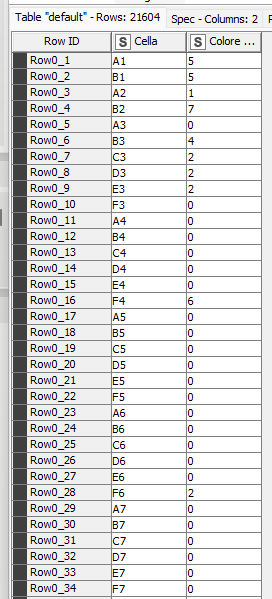
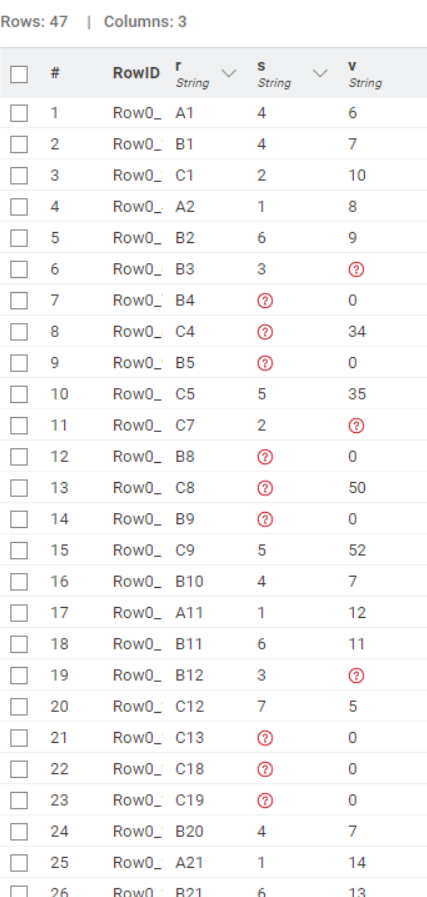
Red - 35 matches between cell value and what is in the XML
Yellow - XML says 1, Excel cell is empty
Orange - XML says value should be 544 whereas text in the cell says “Horror”
Right @MartinDDDD !
I use ugual DNS linguage, for the frist cell it’ s play!
U can show, for check ugual to my file extract, in the cell C22 and C23 show empty!
Why?
You should first extract the “c” element as a node cell and then extract the insider attributes or elements. The reason is that there are elements without “r” attribute or without “v” child element. When you parse them all at once, it lists all existing values so missing ones cannot be determined.
So, first a XPath with this path: /dns:worksheet/dns:sheetData/dns:row/dns:c
and “Return type” = “Node cell” in multiple rows.
Then another XPath to parse inside the “c”.