For reasons of data protection, I cannot use original data and will therefore create an example with the same problem.
Let’s imagine that the contents of a DJ’s suitcase are delivered in an XML file. At song level. It would look something like this:
<box>
<box_number>1</box_number>
<album>
<album_title>The Dark Side of the Moon</album_title>
<album_artist>Pink Floyd</album_artist>
<label>Capitol Records</label>
<music_genre>Progressive Rock</music_genre>
<song>
<song_number>1</song_number>
<song_title>Speak to Me</song_title>
<duration>3:57</duration>
<song_composer>Nick Mason</song_composer>
<song_texter></song_texter>
</song>
<song>
<song_number>2</song_number>
<song_title>Breathe</song_title>
<duration>3:57</duration>
<song_composer>Roger Waters, David Gilmour, Richard Wright</song_composer>
<song_texter>Roger Waters</song_texter>
</song>
<song>
...
</song>
</album>
</box>
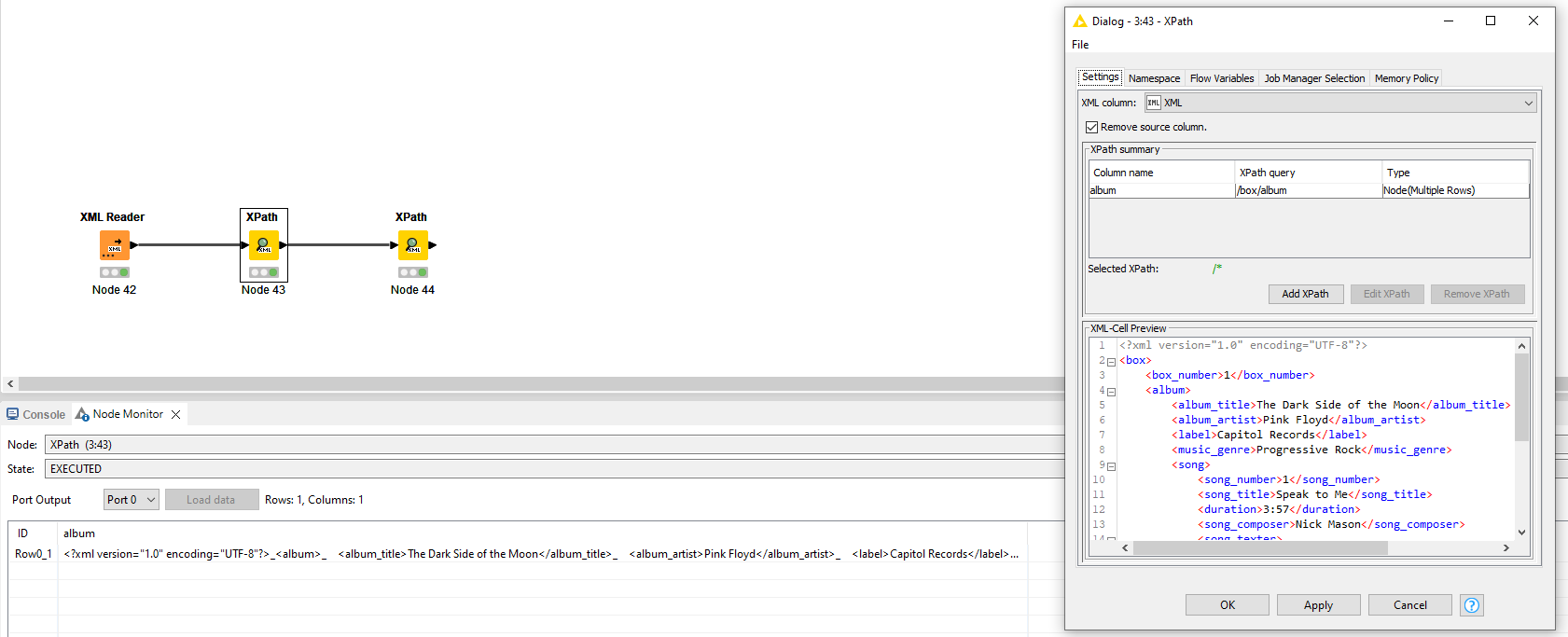
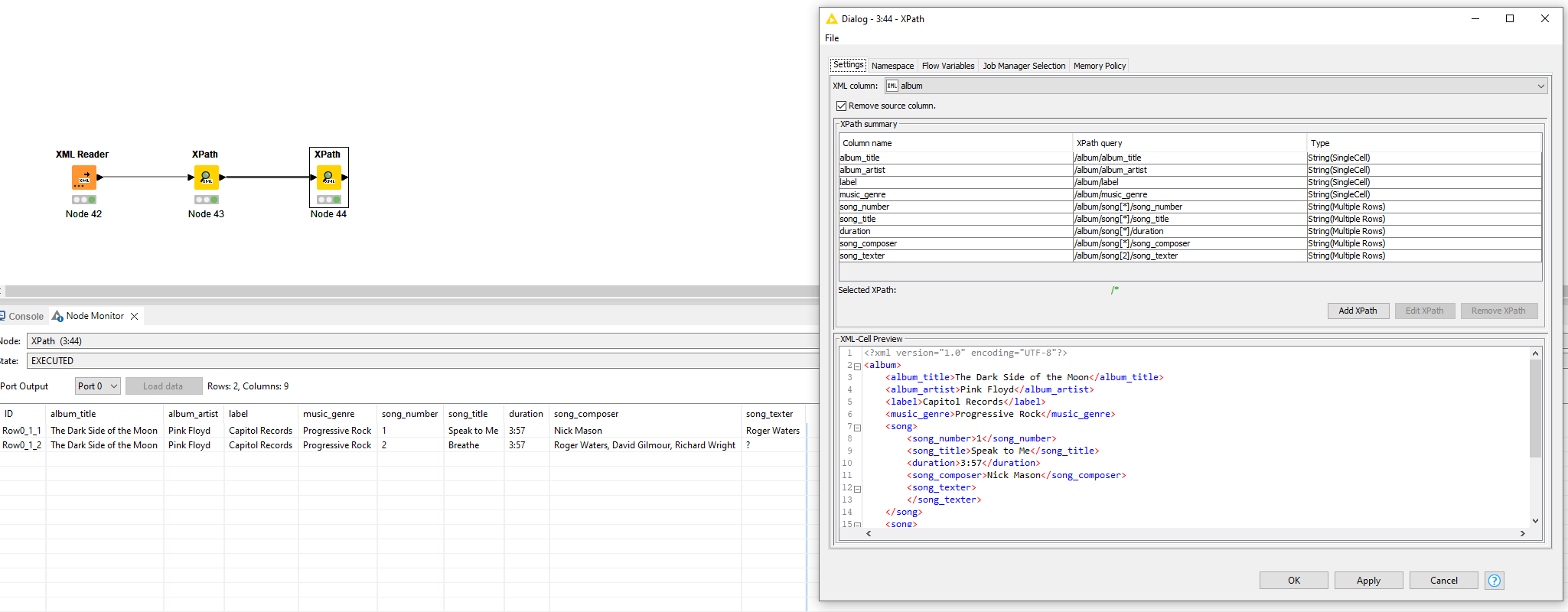
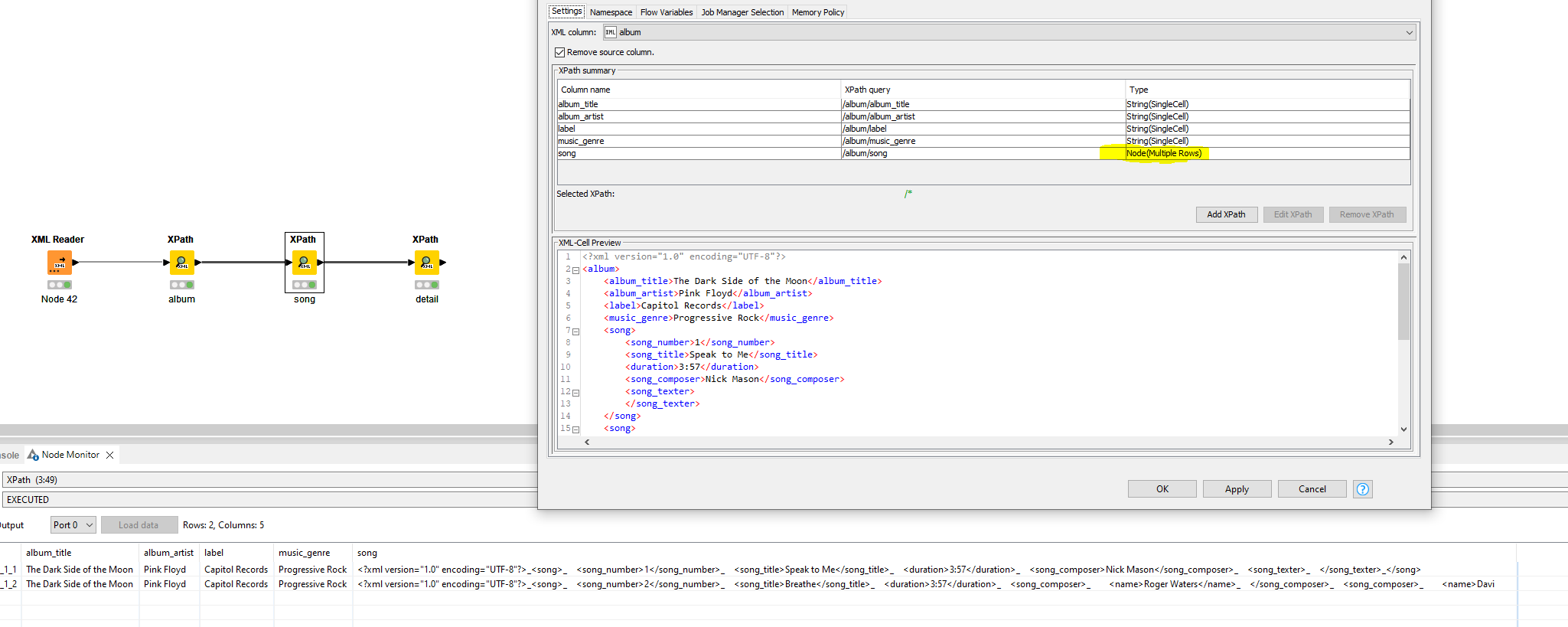
Now I would like to transfer this structure into an Excel file using the XPath node. To do this, I read out the album data and sort it as a String cell and in the tag options as Multiple Rows in columns. I will leave the songs as a Node cell for now, because I will read them out in a second step. I think this is how the KNIME developers have planned the work process.
But here is my question:
If I then display the songs, they would fill 10 lines. This means that only the line with the first song contains the complete data set. The other 9 rows would have missing values in the album columns. As the photo from my real use case shows:
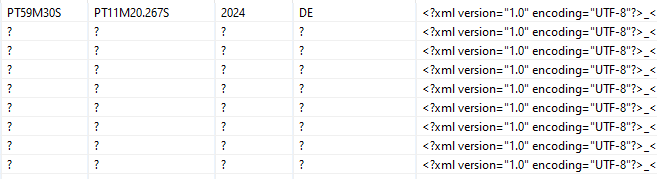
If a second album were to be added now, this data would be displayed in the second row, even though the song columns there contain the second song from the first album. This is then in fact an incorrect data set.
So how can I repeat the album data in the rows until all the songs have been written to the Excel table? So that each song also contains the data of the corresponding album? And only then can the data from the second album be written. How does that work?