Hi
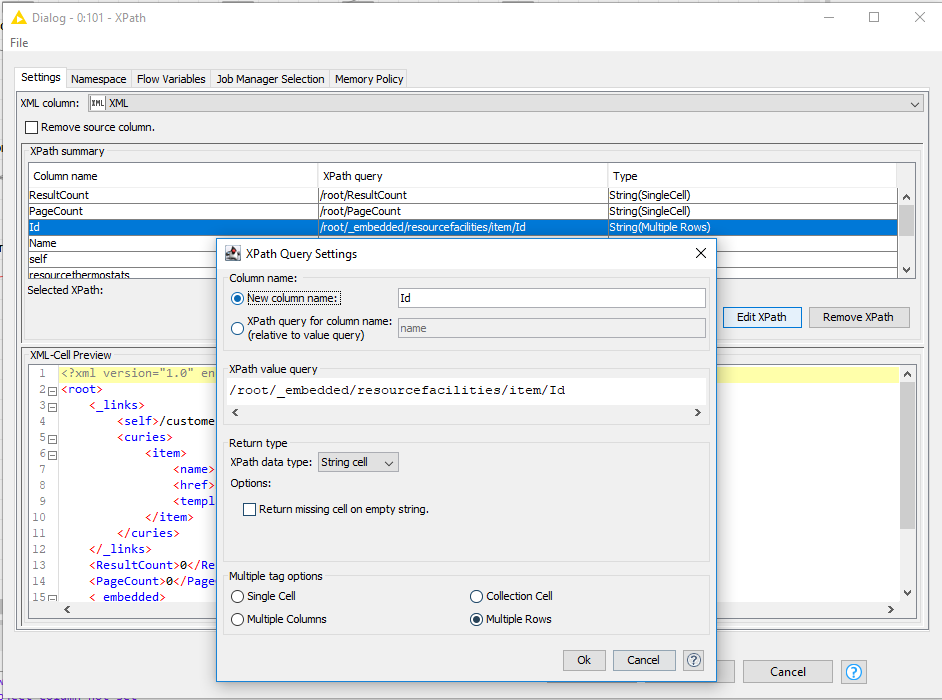
Trying to parse an XML to get the information from multiple rows, however when running the XPath on the XML it only brings back the first 100. There should more than 400 rows - so I know something it is cutting it off. Any way to bring through all the rows? MY XPath settings are below (node, the result count here shows 0 but this was part of a loop - the other one showed 400 resultcount)
Thanks!
Hi @supersharp,
Actually, I think it is not that easy to find out what the problem is, regarding the provided information.
Here I just try to answer regarding what I sense, if I’m getting it wrong, please provide more info or an example.
If it is a web page content in which it is said 400 items has been found, maybe the reason for getting only 100 items is that the other results in the page are not available on page load. For example they appear by scrolling down or clicking some “show more” link.
If this is the case, let me know and I will provide you with the solution.

3 Likes
Good catch, it appears to span multiple pages!
![]()
2 Likes
So you need to get each page separately. Try it and feel free to come back with any other questions.
Hi eveyone,
I actually have a similar issue. For me there is a button that says “show more” and if clicked adds more entries to the page and increases the URL by 1 “https://jobs.philips.com/jobs/#1”. So when I originally got info from the page without the increasing URL ID, I would always get the first 30 entries. I then changed it so that I provide the URLs with IDs from 1 to 10, just to check if that works. However, still each URL gets the first 30 results.Web_Extraction_Test.knwf (17.9 KB)
Is there a way I can fix that?
The workflow is attached.
Thank you!
Hi @Siemru and welcome to the KNIME forum,
In your case, pagination is event based so you cannot catch all results using HTTP or Webpage Retriever nodes (or the Get Request node).
You can get 60 results at most. First 30 results appear as “direct” class and the next 30 results exist as “hidden” class but you can catch them (as shown in the example workflow).
To be able to get all results (1044), you need Selenium nodes (as demonstrated in the workflow).
Web_Extraction_Test.knwf (2.6 MB)

5 Likes
Thanks for the quick reply @armingrudd!
Works fine 
2 Likes
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.