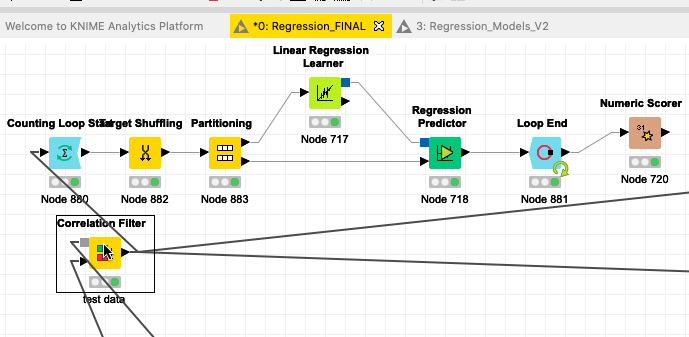
I need to make a y-randomised model for my QSAR models. I was wondering if I use both the training and test data to do that ? or use only the test data? I am a little confused as I’ve seen people using just the test data for a y-randomised model using the target shuffling node.
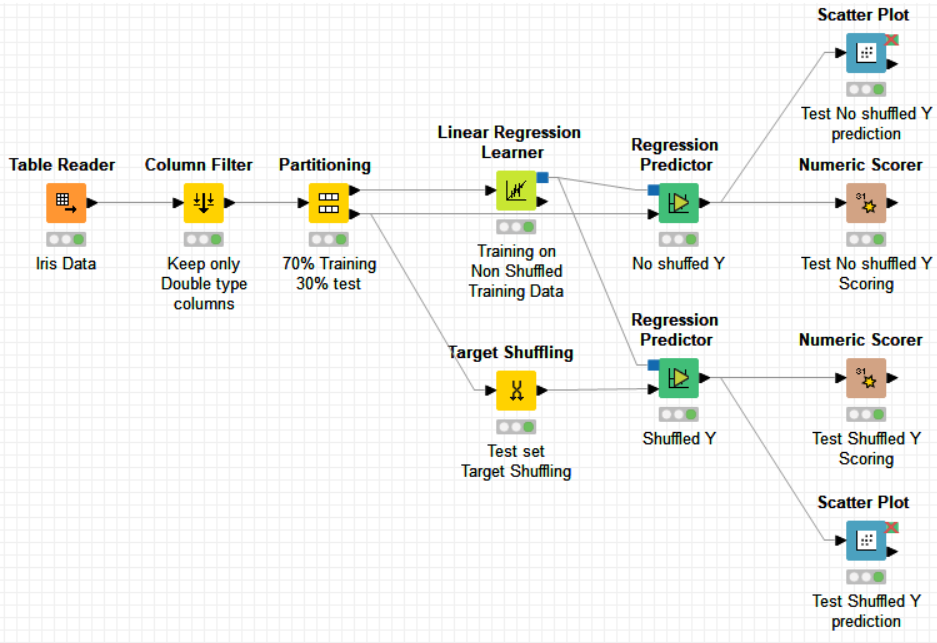
If your aim is to know whether your QSAR model (without y-randomization) is performing better than random, it is only the test set y values that you need to randomize (shuffle).
You are welcome. I’m afraid to say it doesn’t seem correct to me. I wonder whether I was clear enough because you are shuffling before partition and hence the training set too. Would it be possible for you to upload here and share your workflow ? Thanks in advance.
If your Numeric Scorer results on non Y-Shuffled Test data are close to those obtained by the Numeric Scorer results on your Y-Shuffled Test data, then your learning regression model is not doing better than random.
I was just trying to upload my workflow but it is quite big. Yes this helps a lot thank you!
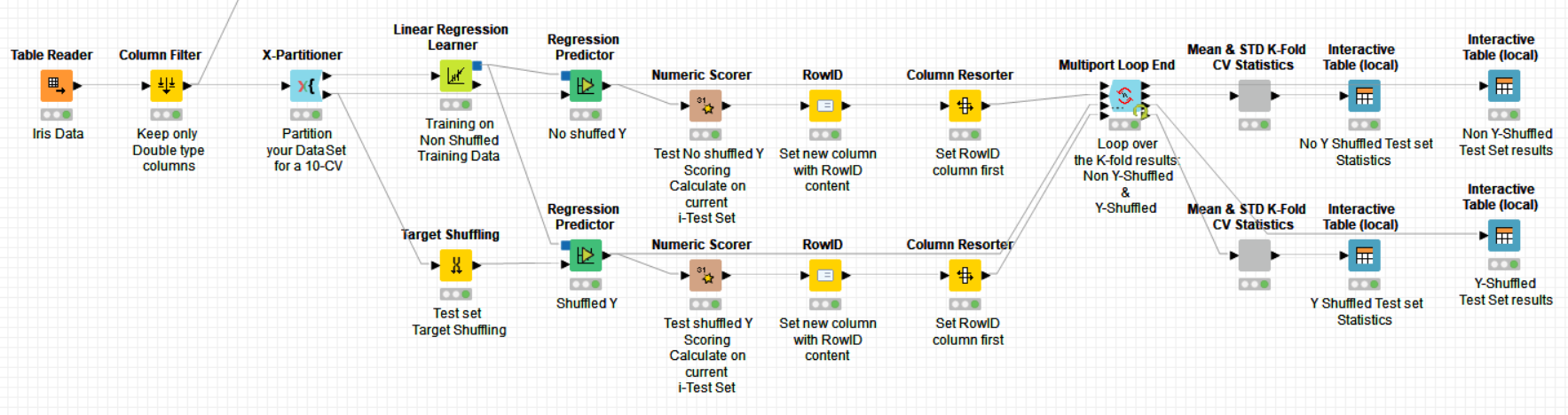
Will I need to run many iterations for this or is running this once enough?
Don’t worry. The important thing is that you got the idea.
If your data is big enough, you are not obliged in a first instance to do a K-fold cross validation to know whether your model is performing well, just a simple CV test, as shown in my straightforward example, would be good enough. However, it is always more rigorous and informative to do a K-fold CV because you can then calculate Mean & STD on prediction results.