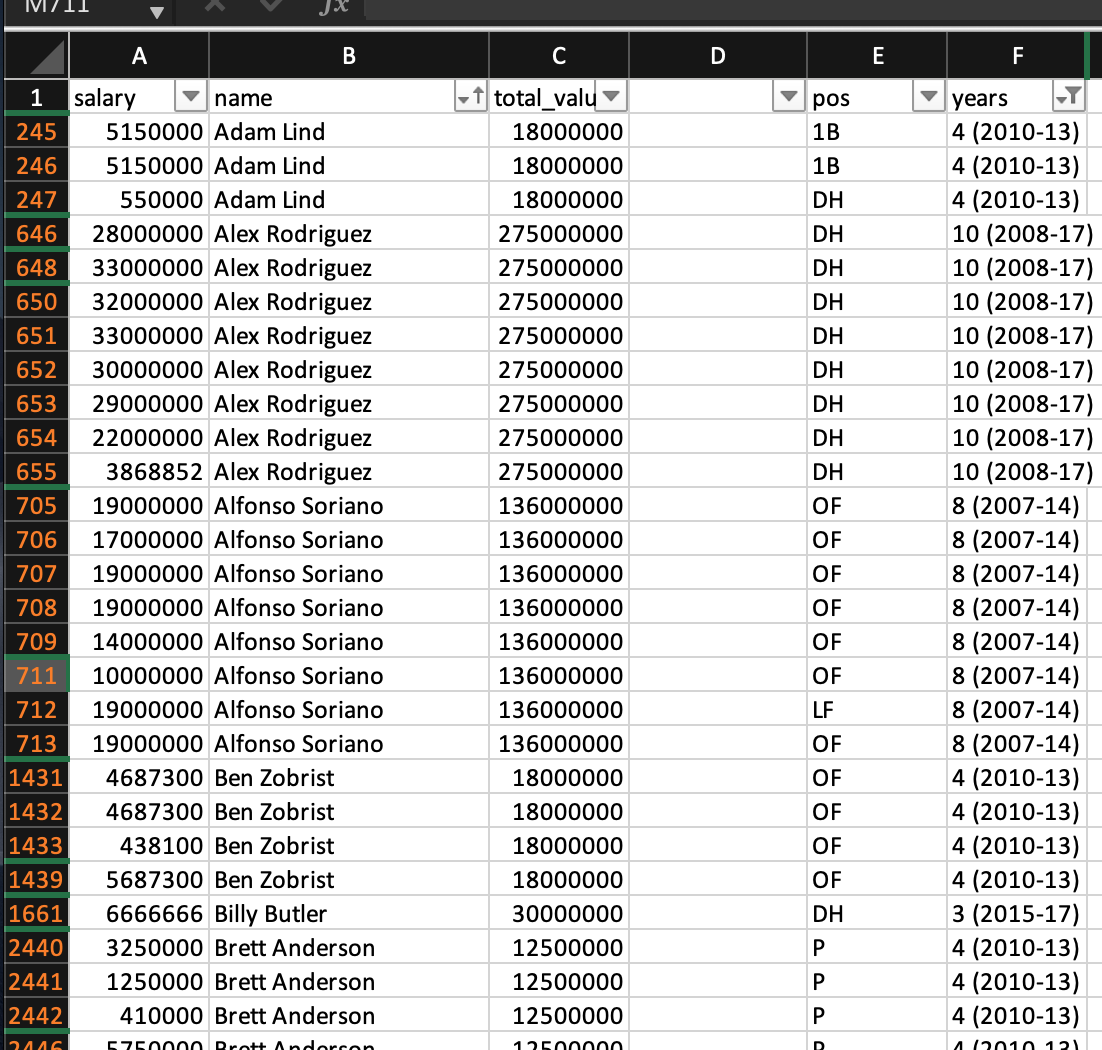
I am completely new to KNIME. Can you please help on how to convert the year range(everything in () in year column) to individual years in that range. For Adam Lind to have 2011, 2012, 2013.
If you could also help me on how to convert to ranges but for one-year periods. For Adam Lind to be (2010-2011, 2011-2012, 2012-2013)
Can you attached the csv file itself so we can have some data to work with?
Also, can you explain how the expected results should look like? Let’s say for all of the Adam Lind records, how would be the expected results for these 3 Adam Lind input records?
Adam Lind is one of the simplest case to look at, in that the years values are the same.
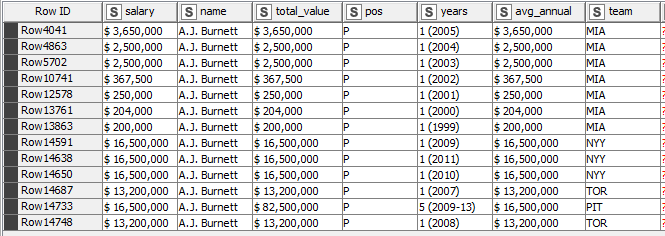
What would the expected results be for A.J. Burnett? This is the data that we have on A.J. Burnett:
Also, the data is provided in this order, but if we look at the values of the years column, it’s not exactly in the right order. Does this mean that we have to sort the data by years?
@duristef , I took a quick look at your workflow. I have a few comments:
You should not sort on the Row ID column as it’s not numerical, therefore it will sort alphabetically, meaning if your sort ascending order for example, Row 11 will sort before Row 2, since alphabetically 11 goes before 2. 11 would go after 02. It’s better to generate an incremental numeric field in this case, like the Counter Generation node and then sort on this column instead. Of course, if you only have 10 rows (Row 0 to Row 9), then you can sort as you are doing. Beyond that, it will not sort as you expected.
In this case, if you are using the Group Loop, you don’t really have to sort are you are trying to do. Knime actually group in that order already.
This one is more of an alternative option: Your Column Expressions inside your loop has the operation column("start")+column("Counter"). You can actually set your min value of your Counter Generation to that value via a variable.
My potential solution would involve group loop as well as I was not able to restart the count for each bulk so I hope one comes up without the need of a loop
Thanks for your reply, sorting is not necessary yet. But now I can see that there are inconsistencies in the data, for some players such as Adam Lind, the season range is provided as 3 entries for others it might be one entry. I will need to go back to the data source.
1 - You’re right, I forgot that ROWKEY is not the same as rowIndex(). I’ve fixed that in the edited version
2 - No, Group Loop would sort on the name, probably (I guess) keeping the row order, but I prefer to sort explicitly on name+row number and to prevent Group Loop to do any sort.
3 - Yes, you could use a variable
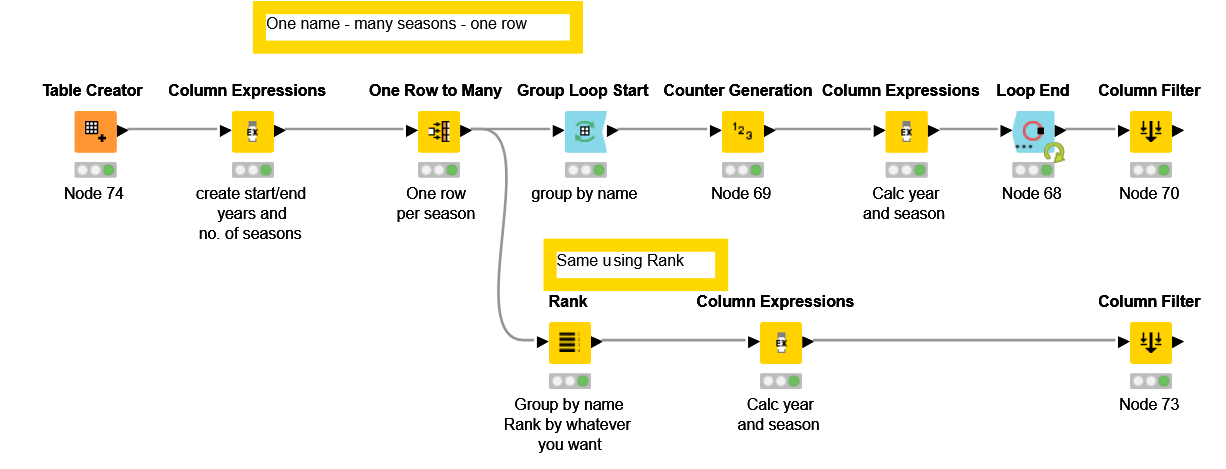
The loop works well with players with a single season and with players (like Adam Lind) with multiple seasons and one row for each season, but should be modified to cope with players with many seasons and a single row, so I’ve added a new “sub-workflow” for that case. It remains to be explained how the case of a player with only one year (e.g. “1 (2008)”) should be treated, since he appears not to play for even an entire season
The attached workflow is an alternative to performing a loop. It does makes for a more involved workflow (extra nodes and some “fun and games”), but it will pay off if speed is important.
I know you said you needed to go back to the source data to check some things, so this may not be quite what is ultimately needed, but it gives an idea for a way to create additional rows without a loop, by using the “One Row to Many” node.
I have included your demo excel (as an xlsx file) within the workflow’s data folder, and made all the 16000+ rows visible in excel.
With a loop, I think this could take a significant time to process, but without the loop, you will see that the entire job will be achieved in just a few seconds.
By the way, I didn’t see any data which crossed the “century boundary” (e.g. something like “1998-03” which would need to be interpreted as 1998-2003). I believe this workflow will cater for that situation, but I would recommend some extra testing in that area just in case
Hi @takbb
I’ve added a new “alternative” in my workflow following your interesting suggestions both about Rank and about the calculation of end year (assuming there’s just one row per player-year range).
This is my comparison of the “loop” method vs the “rank” one
I just ran it through with the spreadsheet from my uploaded workflow with all the 16k+ rows exposed. The “alternative” branch of your new workflow completed in just a few seconds (Column Expressions node slows things down a little but removes a whole load of complexity!).
The image below is the situation within the loop even after what is probably around 10 minutes of processing on my somewhat antiquated desktop pc… I’ve opened the Group Loop Start output table to see where it’s got to and it is only up to Row1076… so only another 15000 or so rows to go A good demonstration of why I try to avoid KNIME loops unless I am totally stuck for an alternative (or the data set is very small), and even then… I desperately try to find an alternative to there being no alternative
Thanks for sharing. Always great when ideas can be built on collaboratively.
That is exactly correct, and that is what I said. It sorts on the column that you are grouping on, in this case name, and keep the row order, meaning it’s already doing what you were trying to do. But yes, I agree on why you were doing the sort explicitly.