Hello everybody,
while testing some data i stumbled across the strange situation that after some numbers were multiplied by 1.000 they were often 1 to small.
after i ran this process:
like the first occurence where this happens is:
I included into the outputfile the original data (column “Volume”) its the column next to 32.299 and shows the original value of 32.3. (You can jump there by searching for the unixtimestamp of that line:1328216204).
The transformation in this process consisted of:
Import from a textfile into a variable with Datatype double
In a math expression node multiply with 1000 and save as integer:
toInt(column(“Volume”)*1000)
So obviously the result should be 32.3K and not 32.299.
This error happend in the 500K lines of the input file 236 time so approx every 2000 lines.
I had some time ago that i had some discrepancies after the 15 digit after the comma.
But this is a discrepancy on the first digit after the comma.
What is the reason for this?
Greetings to all of you!
Edit PS : is there a way to upload the workflow with pointing to the input file in a more “embeded way”? Right now if one wants to use it he has to change the path from my local path…
actually quite interessting case
As far as I can see this is not a KNIME problem but a general problem of binary representation for floating-point numbers.
So if you would do the exact casting in java/c++/… you will most likely get the same result
E.g. for your example case the 32.3 is actually stored as the Most accurate representation = 3.22999999999999971578290569596 as it cannot store the exact 32.3 in the available bits.
So 3.2299 * 1000 = 32299
e.g. better visualized:
Or similar problems most likely better explained:
“To be precise, it’s not decimal at all, it’s binary. A number like 17.3125 has an exact binary representation because it is 17 + 5/16, but 17.31 has no exact binary representation. You can’t express it as a finite sum of powers of two” from Mike Dunlavey in the linked thread.
->But thanks for giving me a heads up - this can really screw something up if you do not expect it…
And sorry for not providing a helpful solution - but I hope I at least could provide an explanation for this problem
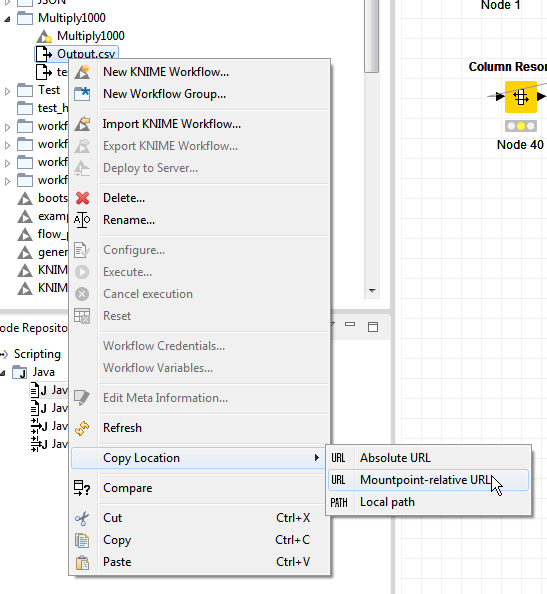
For your second question - you can use relative paths for most of the reader/writer nodes.
E.g. in your case:
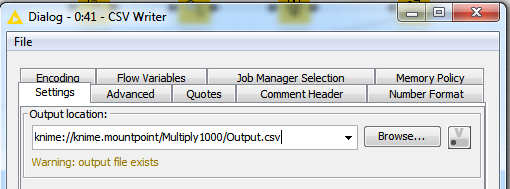
knime://knime.mountpoint/Multiply1000/Output.csv
Then you can use them like this (sometimes you have to change to file-path option in the node as well):
which would write the file to your Multiply1000-Workflow group - which if exported will work for anyone who imports the group
Hello AnotherFraudUser,
I had my head in work and just saw your answer. Thx for that awesome answer with that cool Links!! I want to understand this and it will take some time, since those “precision problems” are completey new to me. tomorrow i will have more time and will have a deep look at this.
So probably i 'll come back tomorrow and with some questions.
@Ipazin: Thanks for your answer too. I will first take some time to understand this and have a look at the solution in the link. For now thx.
So hello again,
i spent the day researching this - it was a fascinating read down the rabbit hole of floating point numbers, i think i stumbled across this mistake some times in my life but not took the time to full understand it - totally worth the time, now i only need to understand how to deal with it
@ipazin the links helped, thx! but still have some quick questions for this:
How are you guys handling this in Knime right now? Using a Rounding function directly after the import through a file reader node shouldn’t really help if i understand correctly. In those other threads even if 2 numbers are beeing beeing rounded to 2 decimals and then added the resulting number is again slightly off. So do you round after each calculation or only at the end before data is beeing written to a file with e.g csv writer?
BigDecimal would be the ‘root solution’ for this are there any plans to introduce BigDecimal for dataimports in Knime? I tried JSON too but that gave the same slightly off result.
What i still don’t get: I import the 32.3 into a variable of datatype double. And it is stored correctly as 32.3. One can see this since the orginal row with the untouched data is written to the csv too and there the value is correctly 32.3. But shouldn’t that be that 32.29999999… too? since the datatype is double?
or is data first importet as a form of string and only if a calculation is done and the data is send to the microprossor than the datatype double is “activated” or something? This would be good to know it is connected a bit to the first question, then i would know when i have to use a round function.
@AnotherFraudUser: thx again for the help with the embeding of files too. Will try it next time…
In case you want to preserve the data as is - i mostly import as string.
However in case of calculations on this data there you might have to think about how to handle it.
One solution would be to have the base number as string - do the calculations in a java snippet via big decimal and write out the result as string.
However nothing really great
Mostly i ignore this problem (if a small deviation is not that important)
After looking into your problem I also wondered why there is no big decimal option in KNIME. Not quite sure why not (maybe it is too confusing to have two options for decimals)
The number is “wrong” the moment you read in the data as double.
You just see (and later write out to csv) the “correct” value due to an automatic java rounding of double values if converted to string.
(as far as I know)
Basically an build in java function to deal with the inaccuracy of the double representation.
However this rounding only happens after casting to non-float objects. So while calculating with the double the inaccuracy gets bigger and bigger.