Dear Knimers, today I dealt with a few uncommon tasks. This post is intended to be a sharing session, but I hope it’s not one directional.
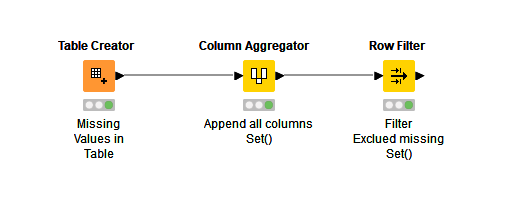
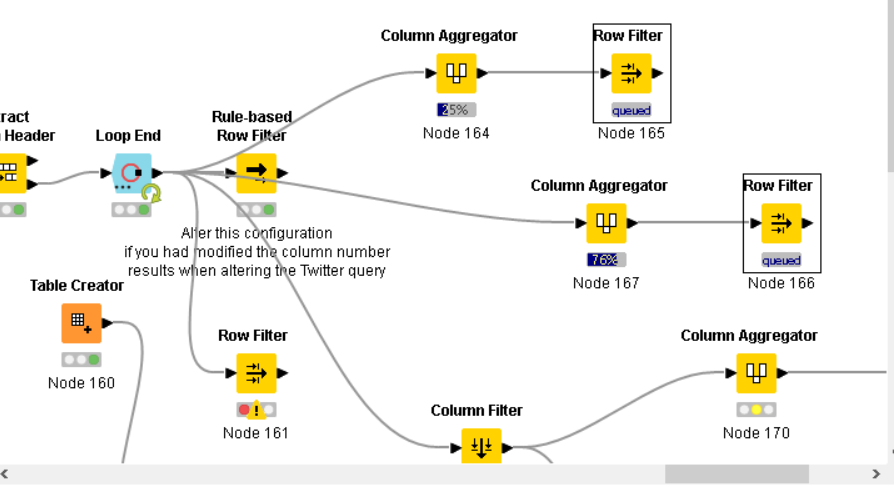
- Removing rows that contain missing values for ALL columns:
Context: The Row Filter Node can’t handle multiple columns at once. Meanwhile, the Missing Value Node treats all selections as ‘OR’ instead of ‘AND’.
The solution I came up with is the Rule-Based Row Filter Node:

As you can see, I had to manually write the script to include all columns and to use the ‘AND’ operator. Imagine if the number of columns is >20, that’ll be irritating - I guess.
I wonder how would you approach this differently?
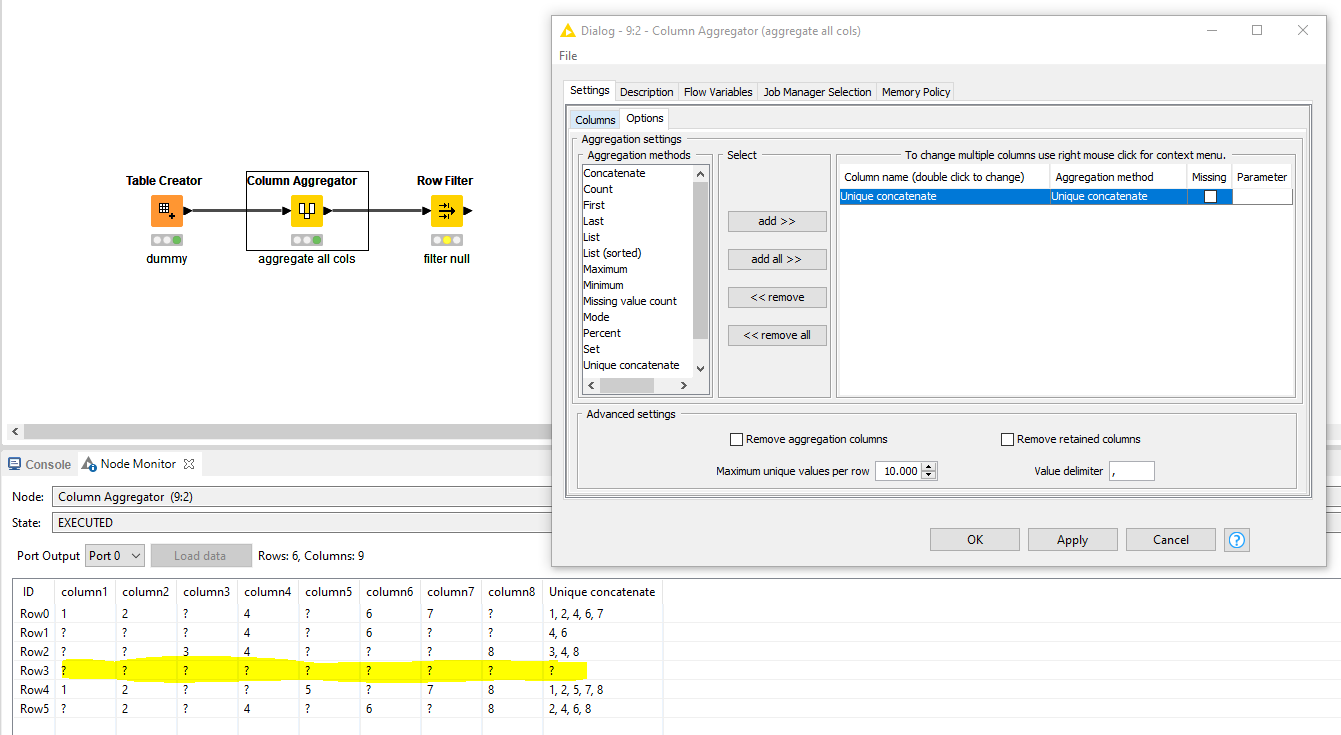
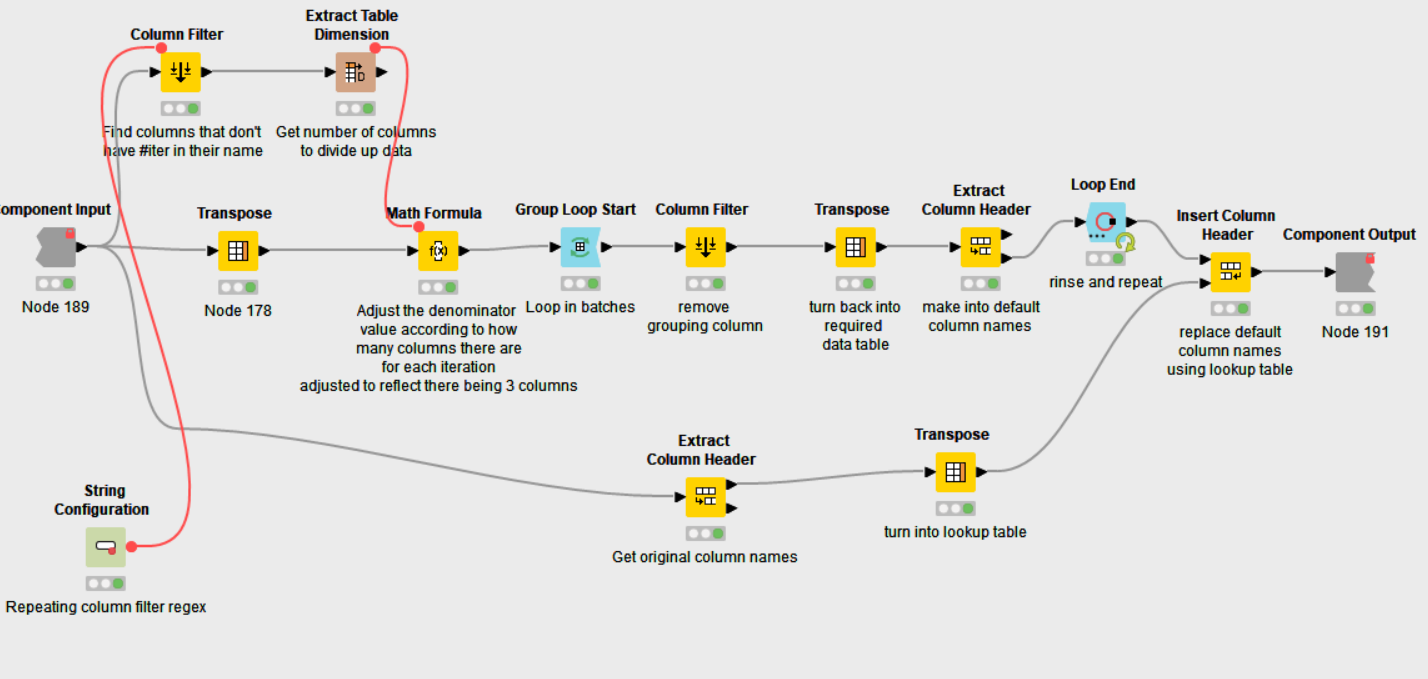
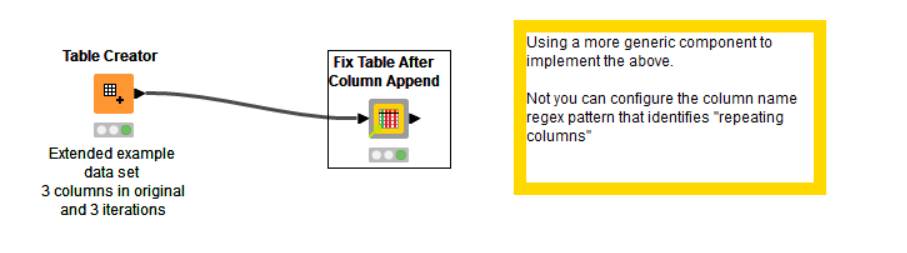
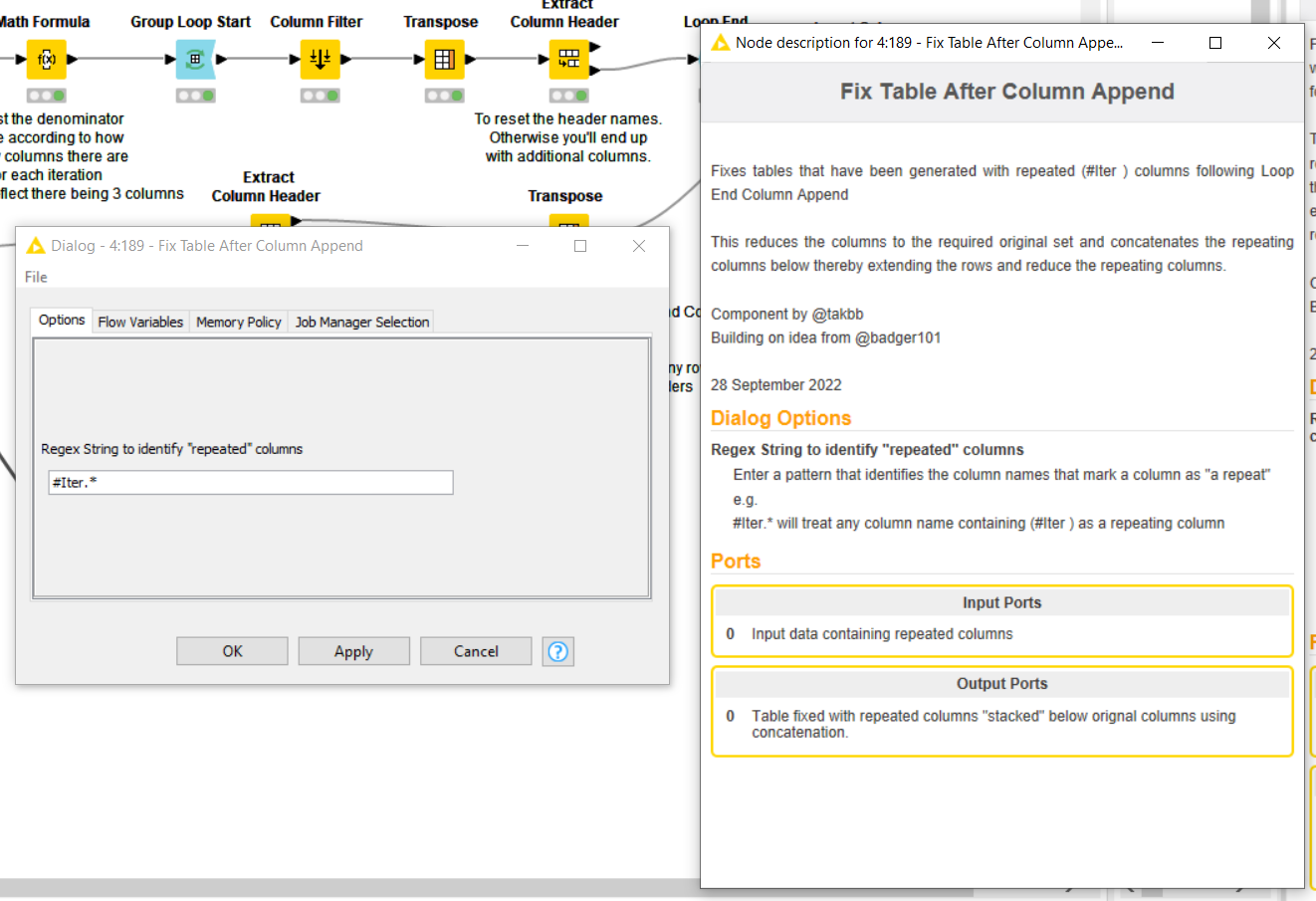
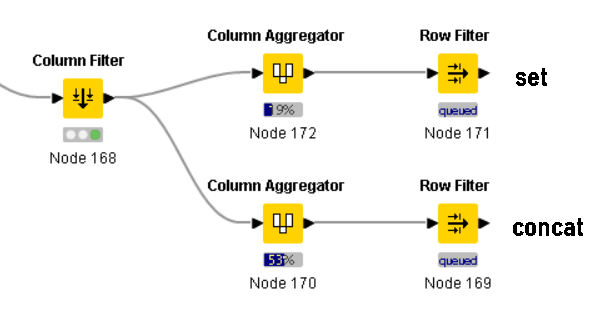
- Dealing with the downstream tasks after the Loop End (Column Append) Node.
Context: Each iteration produces duplicates of columns of the same attribute. In order to use the Concatenate Node to join the iterations together under the same attribute, the columns need to be split (and then renamed). Splitting the columns using the Column Splitter Node has its own difficulties: If one is to choose the Manual Selection, as the name suggests, it’s a manual work. And the node has to be used repeatedly to split all columns from each iteration. If one is to choose Wildcard/Regex, even though there’s a pattern that can be utilized (whereby each column has the iteration number appended to the name), the first iteration (Iteration 0) is not available. Lastly, if one is to choose the Type Selection, that’s not helpful since each group of iteration columns can’t be distinguished by the column types.
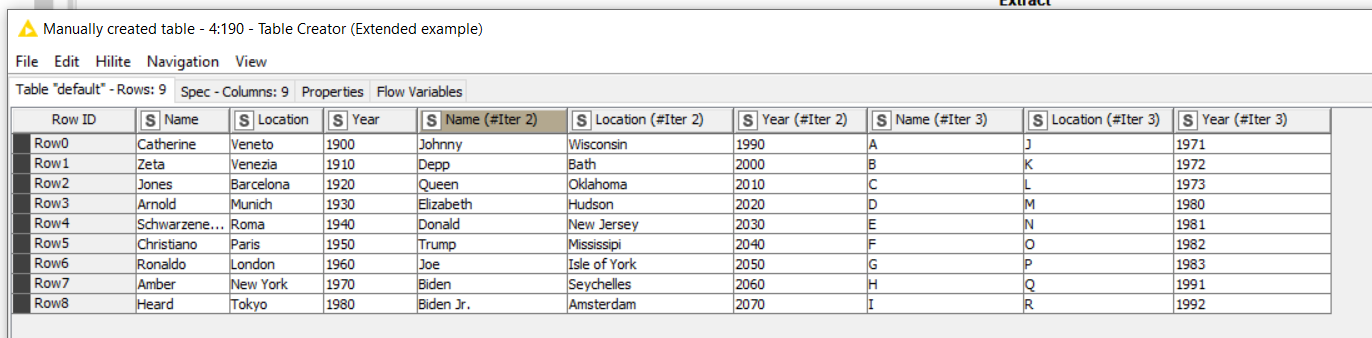
Here’s how a simple version of how a table may look like upon being regurgitated by the Loop End (Column Append) Node:
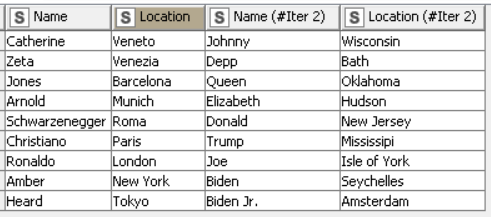
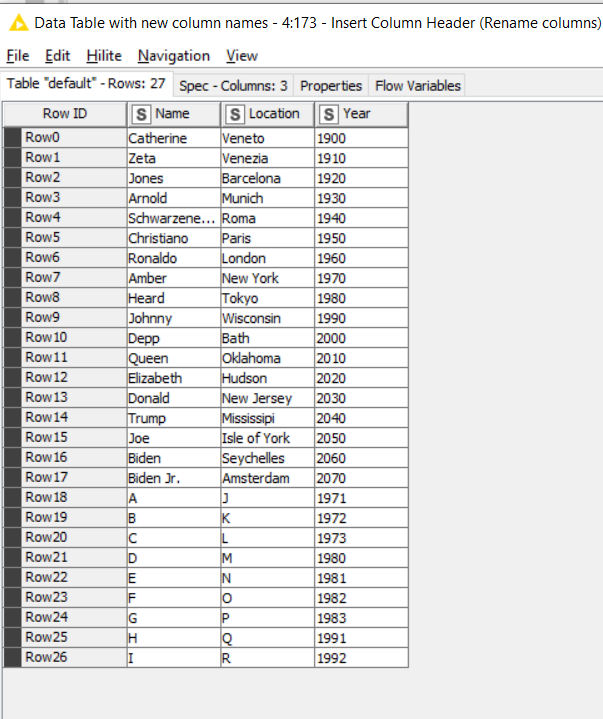
The solution I came up with is:
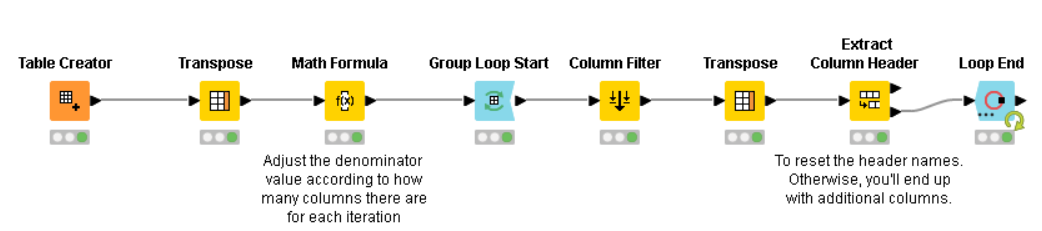
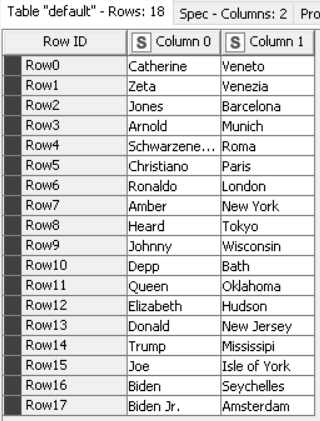
Which converts the table into:
- Another uncommon task I encountered today is to classify the result of Twitter API’s profile icons into three groups:
i) Non-human images
ii) Image of a male human
iii) Image of a female human
This is useful for demographic descriptive analysis. I’ve heard that there are libraries out there for human skin detection, and gender recognition. I’ve also heard that Knime’s adopting the unsupervised zero shot models, which, although is more focused on NLPs, but based on a few presentations I watched on YouTube, it seems like it’s also possible for image classification. I’m hoping that in the future there’ll be example workflows for such purpose.
At the moment, I have no workaround for such image classifications. Till then, I’ll leave the thread open for commentaries/discussions. Have a great day!