I went back and looked at the component and realised from what you said, that there was a bug in it. The String configuration wasn’t being passed through to the Column Filter!
I’ll fix that. I won’t remove the String configuration but I’ll update the default on it.to reflect this different string. Obviously I only tested it against the original sample data, and unfortunately the pattern that I had manually entered in the column filter was working for the sample data, so I didn’t spot the mistake.
I prefer that a component can be kept versatile, and the whole point is somebody can then use the component in future for a slightly different use. Ideally you should never have to edit a component or even look inside it to use it, just change the config in your workflow.
So if for example, a different scenario has fields simple like
Name
Address
Name (#1)
Address (#1)
and so on, it can still work by simple reconfiguration.
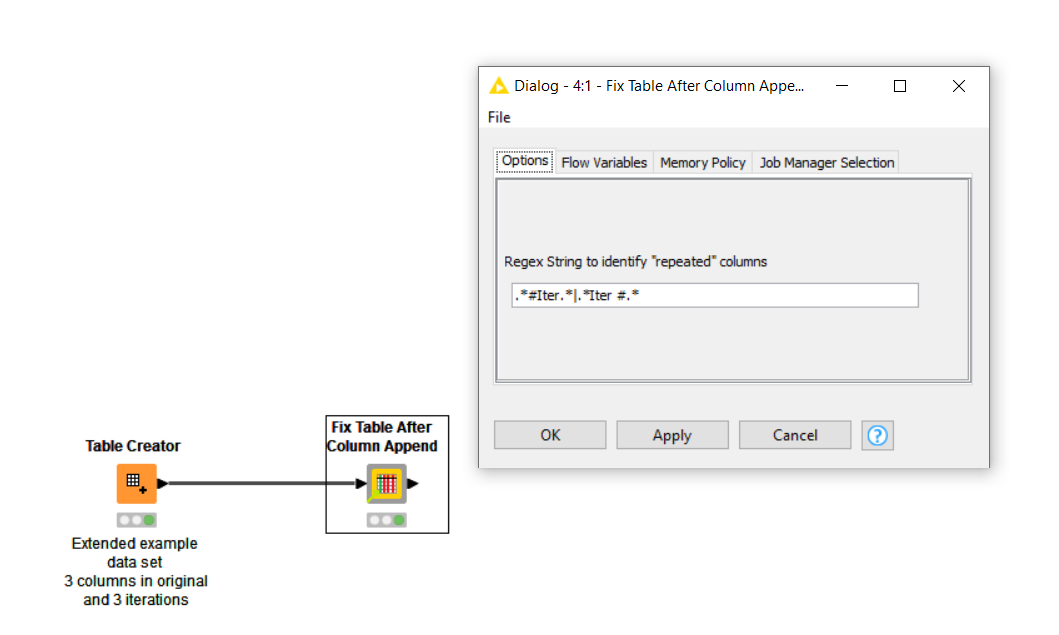
I’ll set the default pattern as slightly differently to how you suggested, as this is the pattern which identifies “repeat” columns, and is used to exclude them. I thought that was more user friendly than including “negation” on the config dialog. Just a shame I had misconfigured the column filter internally in the component. 
Anyway, glad you got it working
Edit:
I’ve now updated the component. As you can see from the following screenshot, I’ve set the default config to allow for two different variations and of course this can be overridden if a different pattern is required.
btw @badger101 , when you use components off the hub, do you get them into you workflow by using drag and drop or do you click the “download” link?
I’m asking simply because I’ve noted that both with this and another component you have “dived into” the component’s innards to sort out problems which whilst not an issue, I find unusual. On a different thread you talked about “losing connections” when the nodes in the component were cut and pasted into a different workflow, which is something I’ve not encountered other people doing before. Normally you take the whole component!
Your comments got me wondering. Especially when you suggested I could then remove the String Configuration node… You know that if you drag and drop the component from the hub, directly into your workflow, it can be used straight off as if it were a “node” without having to open it up and look inside, and that the String configuration node does actually serve the purpose of allowing configuration without digging around inside the component, don’t you?