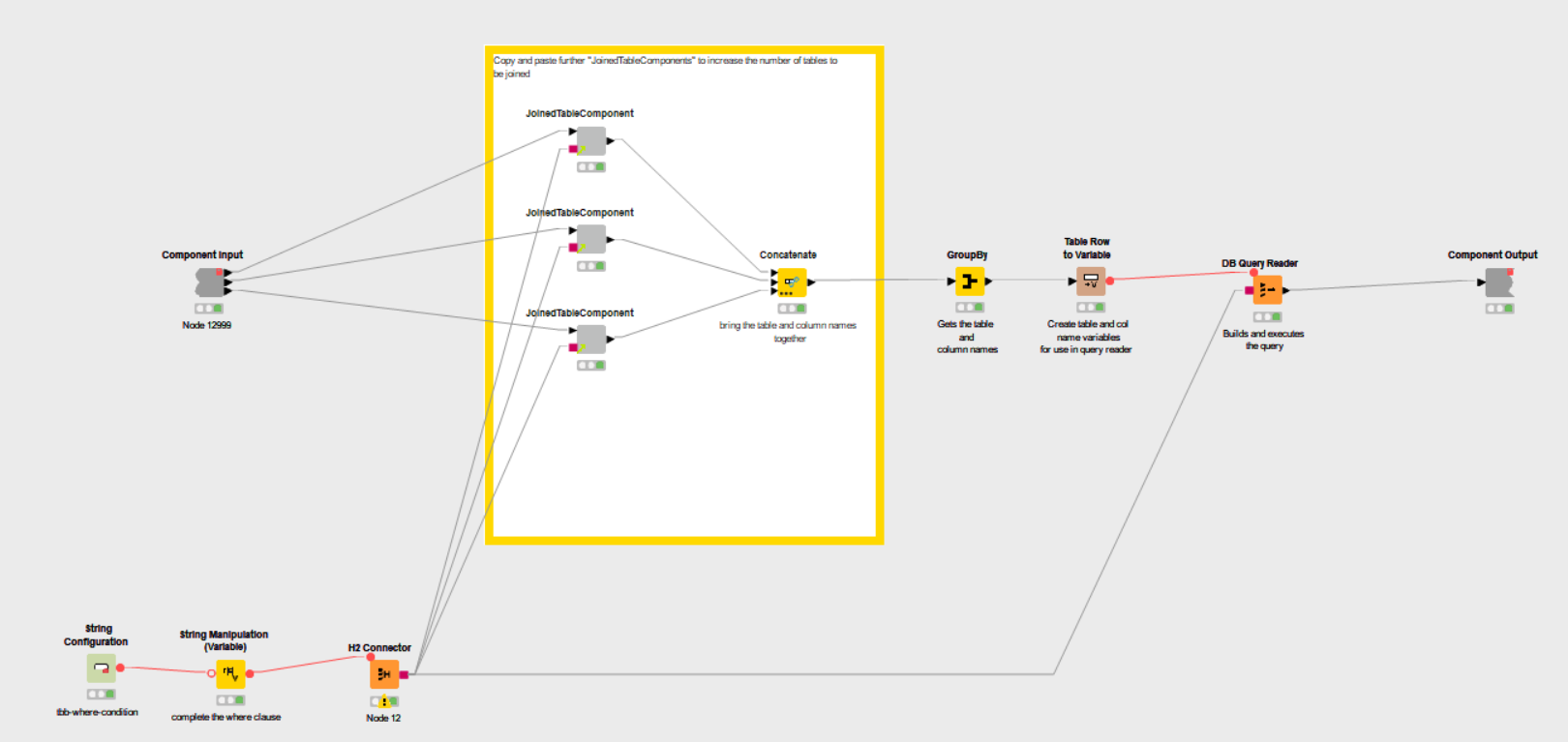
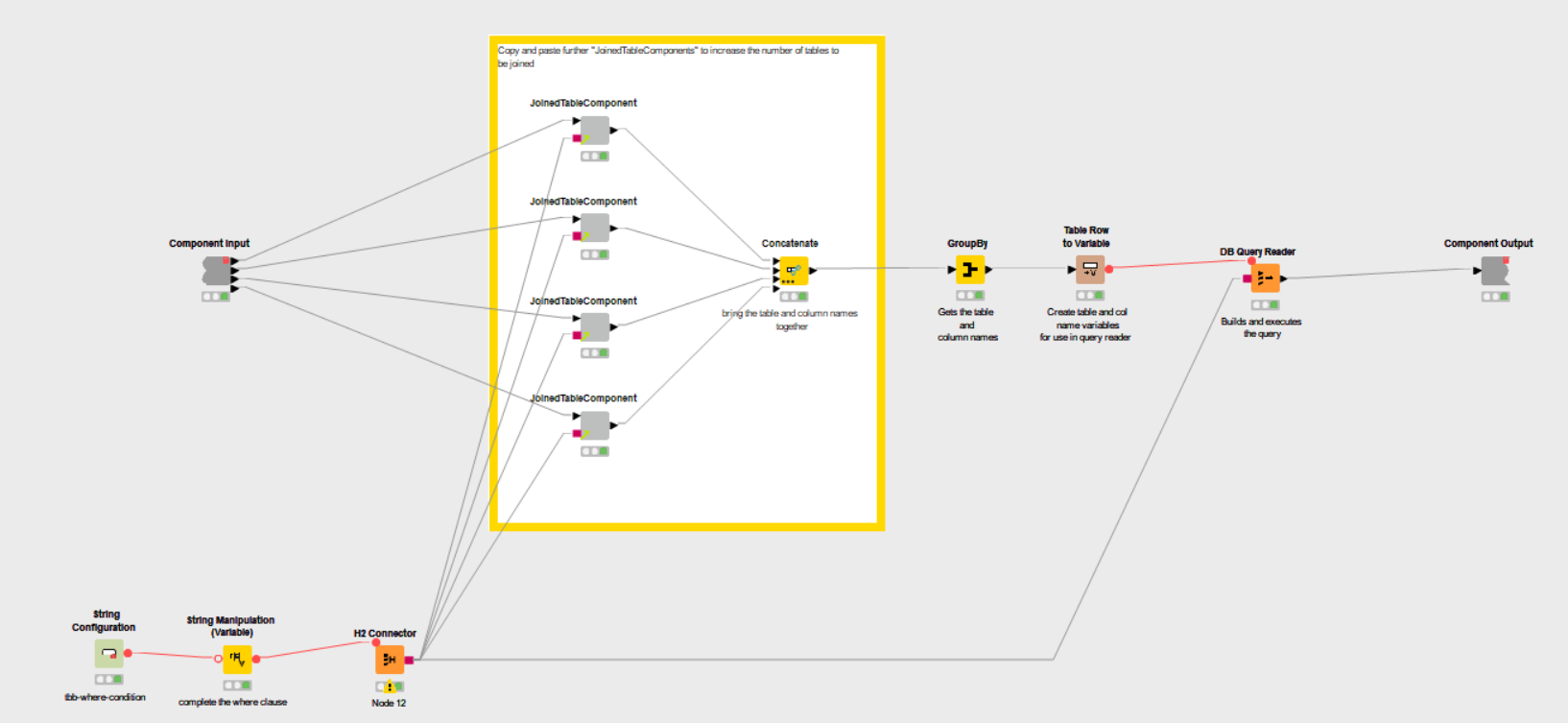
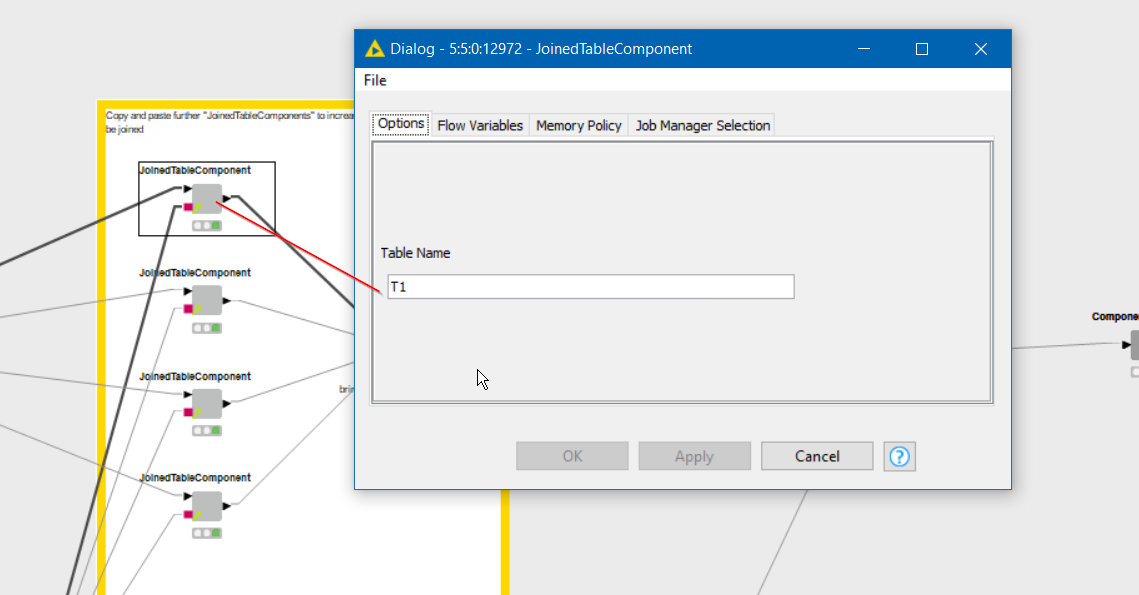
I recently found the “Join Custom Condition” component by @takbb and it has opened up a world of simplicity and possibilities to complex projects. That being said, it still lacks the options and left / right outputs of the Joiner node which requires a series of additional nodes for condition testing, reference filtering, column combining, etc.
I think that the addition of a new “Advanced Joiner” node could superimpose these “conditional” capabilities over the standard “Joiner” node, and it would open up a new realm of possibilities to all KNIME users by maintaining a more user friendly and flexible UI. This node could replace dozens and dramatically simplify highly complex joins.
Basically you could have the interface look the same for your basic Input1/Column1 = Imput2/Column1 join condition logic. Then add additional “criteria tests” (which would effectively function as the “where” clause in a database join). The advanced criteria tests could be managed via a user interface similar to entry of filter criteria in “Row Splitter (Labs)” to provide user friendly and / or and grouping controls. It would need the ability to incorporate “like” / “matches” as well. Both the basic and advanced Join Criteria could be controlled via this Row Splitter (Labs) interface approach as well, if that turns out to be the easier user interface approach.