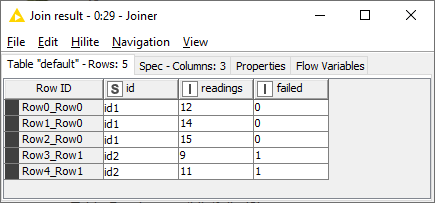
I have 2 tables.
Table A columns: ‘id’, ‘readings’ and looks like this:
id1, 12
id1, 14
id1, 15
id2, 9
id2, 11
Table B columns: ‘id’, ‘failed?’
id 1, 0
id 2, 1
id 3, 0
I wanted to take the ‘failed?’ column data and add it to Table A’s data so I have:
id1, 12, 0
id1, 14, 0
id1, 15, 0
id2, 9, 1
id2, 11, 1
I tried using Joiner and all the different join options but my data ends up showing the last record in A repeated, like this:
id1, 15, 0
id1, 15, 0
id1, 15, 0
id2, 11, 1
id2, 11, 1
@elsamuel thank you for checking the question and probably solving the problem.
Could you upload the workflow here or on the hub? From my experience if you struggle with a seemingly simple task it might help to see a working example possibly with some additional hints.
I usually do upload the workflows I’ve worked on for questions here, but in this case I guess I figured my simple 3 node workflow wasn’t going to be that useful.
Thank you, elsamuel, for replying. My data sets are 2 files: 8 columns by 28,603 rows and 46 columns by 5714 rows. The common column between the 2 files is a “serial id” item.
When you said your simple 3 node worked, I reduced my data sets to 8 col by 5369 rows and 46 cols by 1023 rows. The join then worked as expected. Perhaps there is an issue with the “serial id”.
I noticed in both join attempts that I’m missing data at the end of each join table. Both files have data through November 4th. The joiner with all of the data ends with October 5th while the reduced data set ends November 1st.
I’ve uploaded my workflow with the data included: reduced_prod_data.csv, full_prod_data.csv, reduced_cal_data.csv, full__cal_data.csv. I had to rename the extensions from .csv to .txt to get the upload to work.
@rrd2 you should take a close look at your whole data structure. You have duplicate IDs in both tables. Question is this what you want to have. This might bring all sort of problems in the future especially if you have cross-joins. I would advise to think about this from your business perspective.
The point with your data: it is the case that for 4,351 IDs from the (right) production data there simply is no match in the “Cal” data. I think you should take a serious look at your data stream and concept. I do not think it has anything to do with a KNIME node or function.
Thank you, mlauber, for replying. This data comes from our production cell. One file contains all of the calibration attempts and the other is the overall production results. Unfortunately, a given part is sometimes tested more than once, hence the duplicate IDs.
I usually use Excel to match up pass/failed part records with their respective calibration records. I was hoping to learn Knime to speed up the process. Looks like I need to learn a lot of Knime’s data cleaning techniques.
I am going through your example and want to thank you again!
In this case you could use the last entry as the one you want to join or the last one with valid data, heck out the duplicate node from knime and my linked article. I think KNIME is a great tool to standardise and automate such processes.
There is a dedicated free book about migrating from Excel