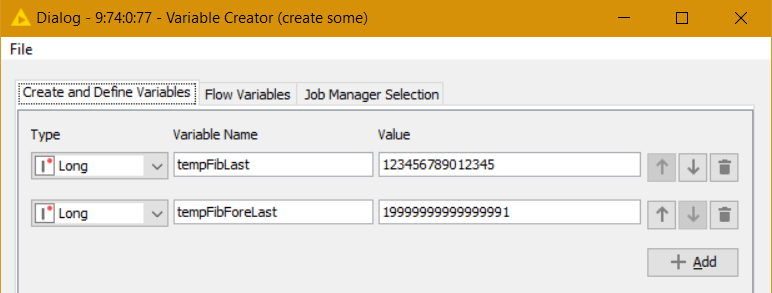
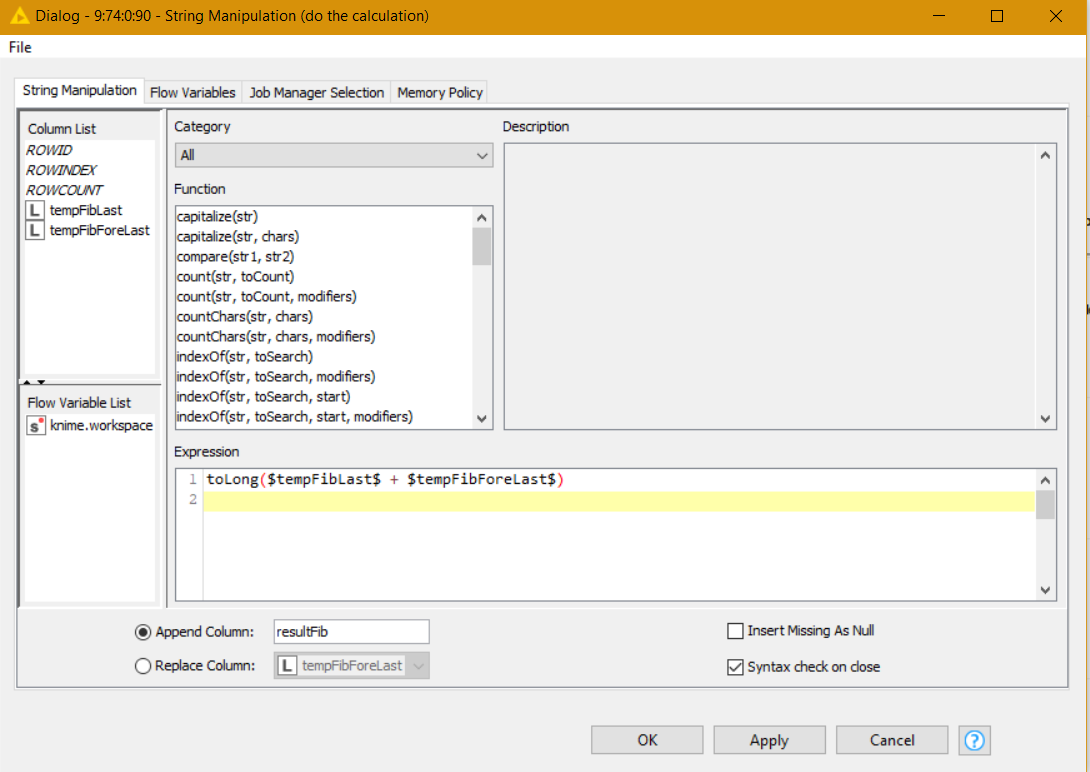
Hi,
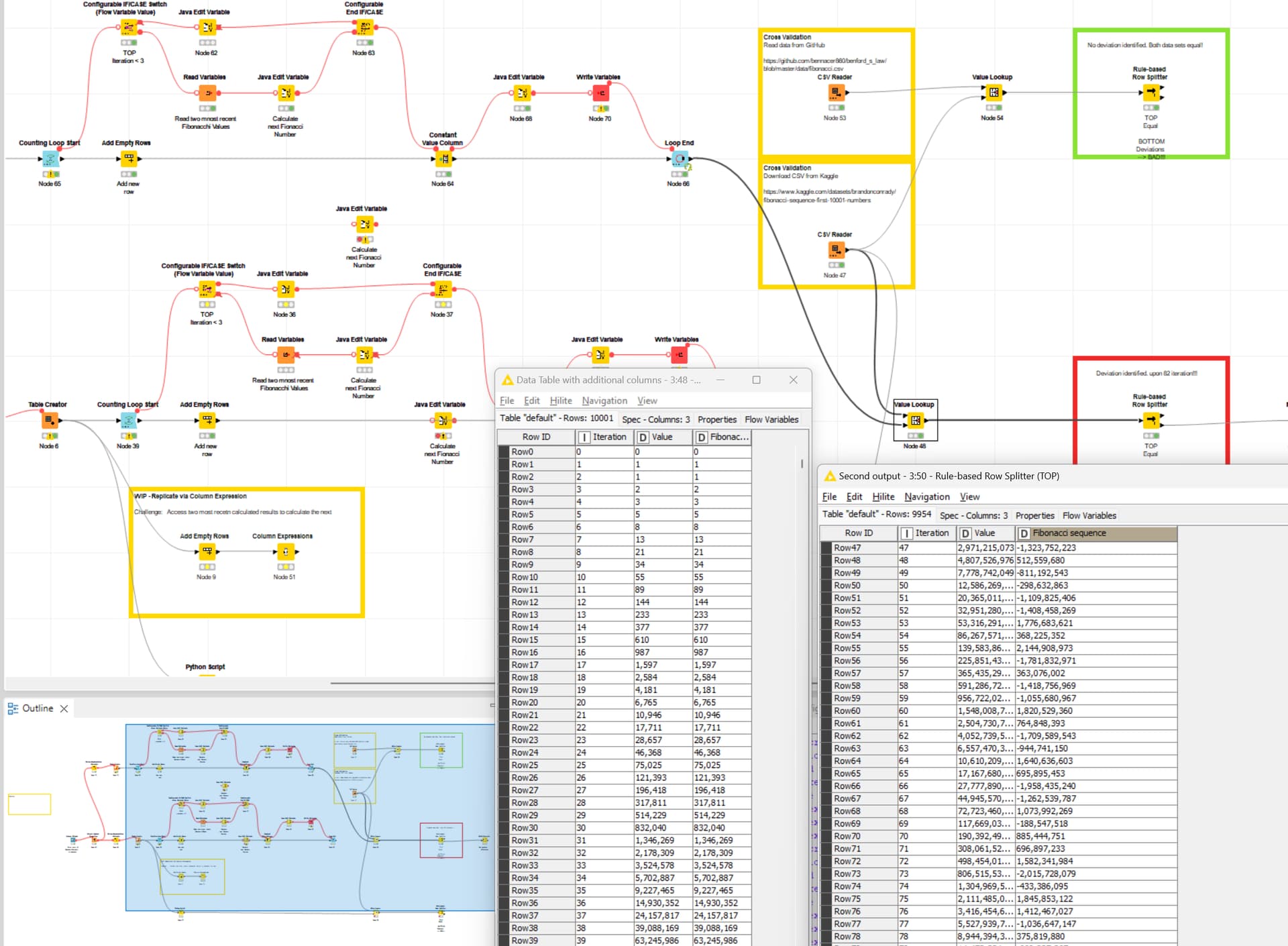
I created a workflow to calculate the Fibonacci sequence with the purpose to:
- Use the process to scale up test workflows i.e. for performance testing or bug hunting
- Publish a series of articles
- Show and provide education for Knime Starters (one challenge, many solutions)
- Educate and challenge myself to understand mathematical principles and how to transform them into some sort of “analogue” representation
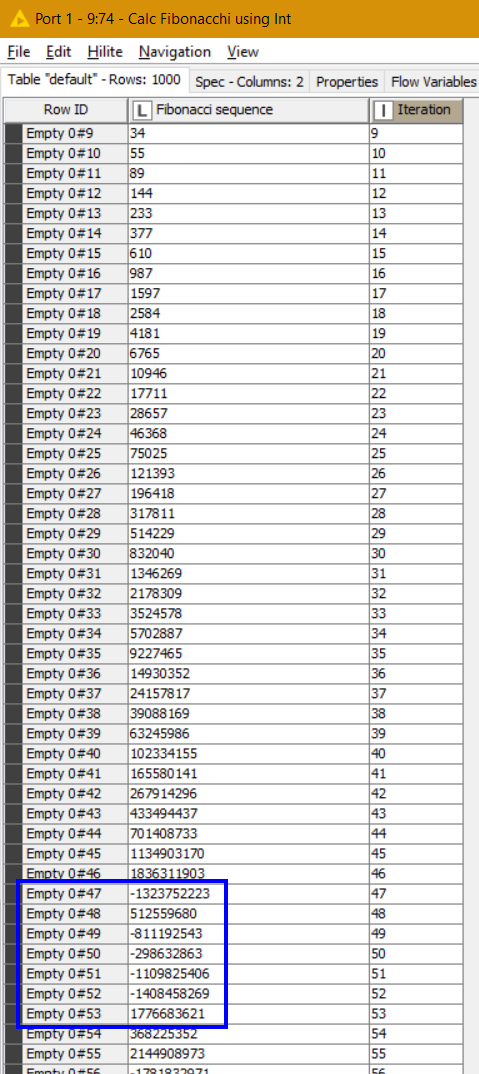
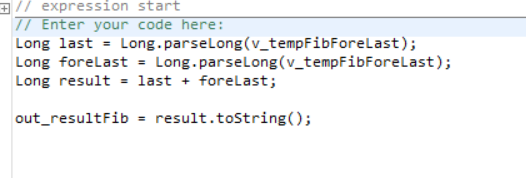
The logic is simple, if the initial results equal to the expectation, the solution is correct. The problem I noticed, when calculating the Fibonacci sequence and cross verifying it with two independent resources (Kaggle & GitHub), there is a deviation upon the 82 iteration.
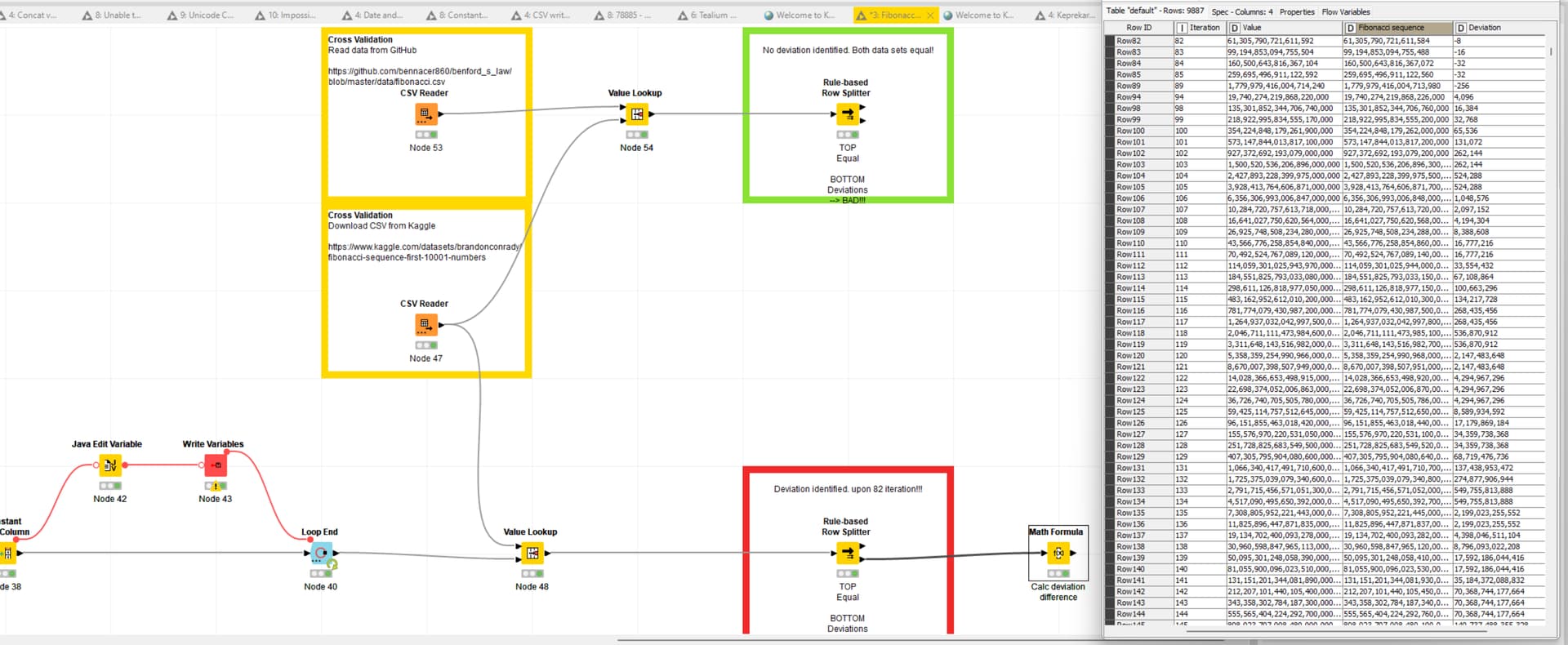
Most interestingly, the deviation starts with -8 and keeps increasing by that factor which makes me wonder, given the are eight bits in a byte, if there is a connection.
On another occasion, albeit being a more complex mathematical scenario, I happen to notice a deviation as well. Though, that really might be a mistake on the workflow.
I hope I am the problem here and not Knime ![]() Here is the test workflow:
Here is the test workflow:
PS: I replicated the exact same issue, failing at the 82nd iteration, even through other means using Python too which points towards a more fundamental issue. The test workflow was updated with the latest changes.
Best
Mike