I have a challenge and I can’t get my head around how to resolve it. I have two tables.
Table 1 is a list of transactions.
Table 2 is a summary of payments to suppliers.
I need to associate the individual transactions in table 1, to the summary payments in table 2.
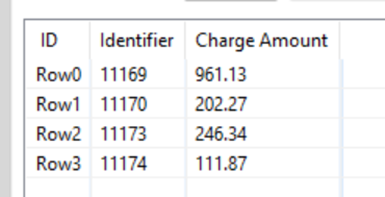
Example of Table 1:
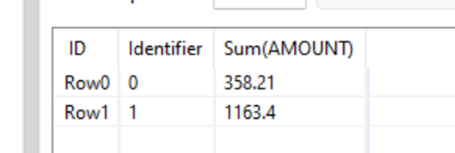
Example of Table 2:
Solving manually:
*Transactions 11169 and 11170 in Table 1 are associated with Identifier 1 in Table 2 (i.e. the sum of 961.13 and 202.27 from table 1, sum to 1163.40 in table 2).
*Transactions 11173 and 11174 in Table 1 are associated with Identifier 0 in Table 2 (i.e. the sum of 111.87 and 246.24 from table 1, sum to 358.21 in table 2).
I need to do this in bulk, but can’t find an efficient way of solving. Does anyone have any ideas? I contemplated a loop, that writes the values to a CSV, sums, and then joins on the values, but this feels too overly engineered.
Hi @Unlockedata , so are you saying that the only thing identifying the link between the tables is that some amounts in one table sum to the value in a row in the other table?
What happens if two amounts in one or other of the tables is the same, or if there are multiple possibilities for which rows added together make a sum?
Can an amount ever be zero?
Is it guaranteed that all rows in the tables should find matches, or can there be “orphans”?
How many rows of data would you be expecting to process at one time?
Is there any grouping to the rows in table 1, or could " related" amounts be scattered anywhere in the table?
Is there a maximum number of table 1 rows that would combine to make a value in table 2?
If you literally have thousands of rows at a time which need to be matched, then you could end up with a massive number of combinations to process.
I wouldn’t worry about a solution to something like this feeling over engineered. I’ve tackled problems like this in the past and trying to match arbitrary values to sums (finding a “best fit”) is generally a non-trivial problem! Finding an efficient mechanism (if it exists) will depend on the answers to my above questions (and more that I haven’t thought of yet! )
One challenge of " best fit" is deciding the optimum matches.
Suppose table1 contained
75
25
20
10
25
15
5
And table 2 contained
55
80
40
We might determine that
55=25+20+10
80=75+5
40=25+15
But what if we instead found that
55=10+25+15+5
That would then leave us trying to match
75
25
20
With
80
40
which would not work.
So you can imagine resolving that could require many many iterations and testing of combinations if you have a large dataset.
@takbb, thank you for taking the time, and asking good questions. I appreciate it.
Linking between the tables - the values are not the only link. In both data sets there is an additional string field that I intend to do string matching on after the matches to ‘weed out’ incorrect matches / joins. This would be a data quality / cleansing process once joined.
Amounts will not be zero, no. But, there could be credits / refunds.
The two tables will not match financially - the sum of transactions in both is different.
In terms of volumes - I have around 3,000 transactions I need to match against a source of around 40,000 transactions.
From experience, the task if running against the kind of numbers of transactions you are looking at would take an exceptionally long time to complete as every additional row multiplies up the number of possible combinations to assess. The time increases exponentially with the row counts.
You will need to do everything you can before the number-matching occurs to “weed out” incorrect matches if you are to have it run in any reasonable time frame.
For every value in Table 2, you are going to be trying to find all possible combinations of rows in Table 1 which sum to the value. You have said there could be credits/refunds which I take to mean negative values too, so you cannot necessarily rule out numbers just because they are larger than the target, since there may be a balancing negative number further down the list. So at worst case (i.e. with no specified constraints) you are attempting to sum all possible sets of 40,000 values. If my maths is correct, that is 2 raised to the 40,000 power combinations! Which even processing 1million combinations per second I think it wouldn’t complete within the expected lifetime of several universes!
So, we would need to refine the rules to make it manageable. This is why it is important if we can say there would be an absolute maximum limit of the number of rows in Table 1 which might realistically combine to form a row in Table 2. The lower that number, the fewer combinations the process would have to consider. But with no stated limit, it would have to assume everything is possible.
If you can group the 40,000 transactions into much smaller groups because maybe you know that all related transactions are likely occur in a certain timeframe, or because you have some other way of knowing how they are grouped, or you have this string value that rules out certain rows on Table1 from from being related to a row on Table2, then you need to find a way to apply those first.
Basically, you want the tables being compared to be as small as possible, without compromising the matching process. Combinations are your enemy, and there are far, far fewer combinations in a very large number of small tables than there is in one large table.
The next issue is how do we know what the termination-condition is. If we knew that we are looking for everything to balance, then the termination-condition is when everything matches. But in this case, there may not be a match for some things. So pulling together different combinations we can find that we can match things up in different ways but never have it fully balance. How do we decide the job is complete, and how do we choose the “best” set of combinations ?
So still plenty of questions, and things to think about. I haven’t got any answers at the moment, but I have some posts on related problems from which we might draw some inspiration (and I suggest plenty of coffee!)
This sounds similar to my audit approach. Essentially the easiest way is to approach the process as a series of cascading joins. Easiest first to get them out of the way, then 1 join approach at a time starting with the matching strategies that you have the highest confidence in first. I use this component from @takbb for the process.