Hi Team,
I am using Amazon S3 Connection(legacy) node in my workflow. usually, it works fine but sometimes it gives this error. WARNING: Unable to execute HTTP request
This error is resolved after I restart my workflow manually.
Is there are any way where the Amazon S3 Connection node tries to reconnect automatically in case of the above error and I don’t need to restart the workflow manually.
as ipazin already mentioned, there is a new Amazon S3 connector node that uses the new File Handling and new S3 client version behind the scene. Does the new node fix the problem?
With the new Amazon S3 nodes, you want to use the Transfer Files node, making sure to click the three dots to enable the dynamic ports, where you can add a source file system connection.
Maybe this blog post about the new file handling system helps clarify things for you? In particular, the list of old nodes vs new nodes:
I have modified my workflow to use the new knime nodes, hopefully the error which I was getting Unable to execute HTTP request:s3.us-west-2.amazonaws.com will go away.
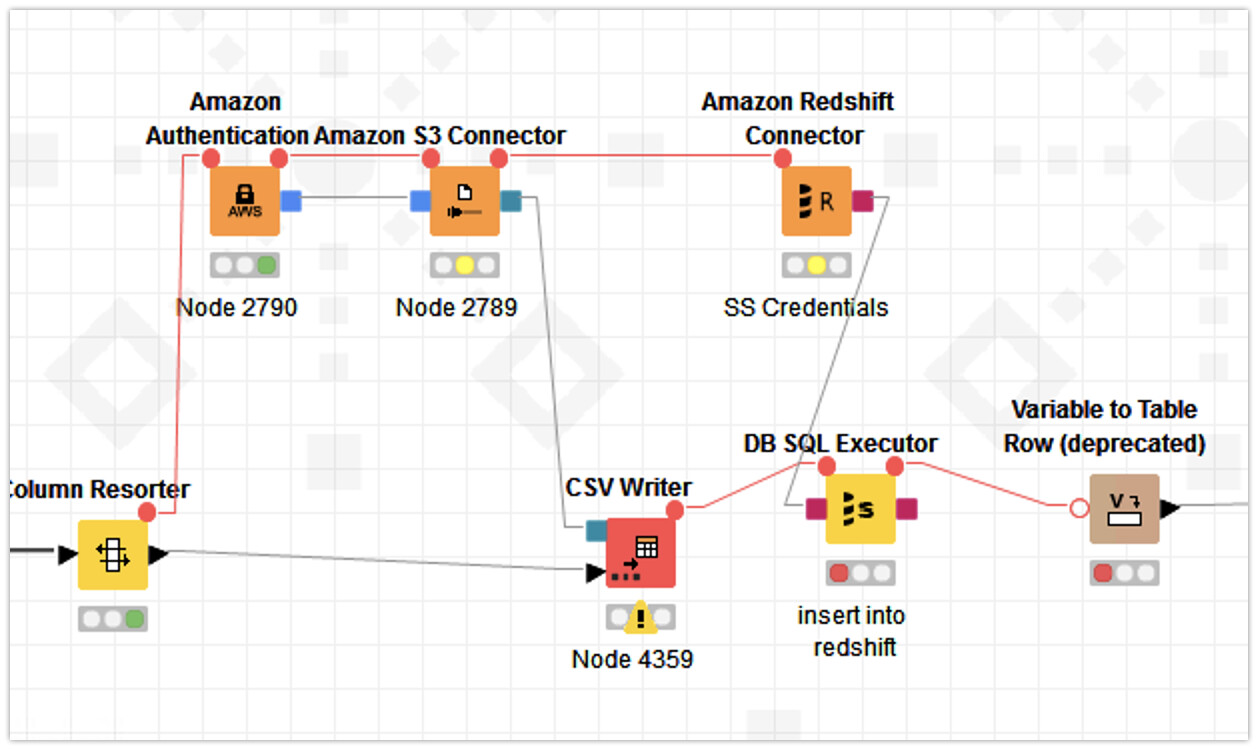
Hi @ShinagdeS , you should probably also link your Merge Variables node to the Amazon Redshift Connector. That way, the connection will be established only after the Merge Variables is executed.
As it is right now, your Redshift connection is established when the workflow starts. That connection then remains idle until the first DB SQL Executor runs, which runs only after the Merge Variables is run. Before all this can happen though, there is a CSV Writer that has to happen, and I’m guessing there’s a bunch of processing that needs to happen before writing to CSV, then the Transfer Files to S3 needs to happen, so there is a risk that your Redshift connection could expire before you get to the DB SQL Executor.
Similarly, I would connect the CSV Writer to the Amazon Authentication or the Amazon S3 Connector rather than to the Transfer Files. Again, the S3 connection will be establish when the workflow starts, but will only transfer to S3 once the CSV Writer is completed. It’s always best to establish your connection right before you need it, that way you have less risk of connection getting expired, and Knime does not notify you if a connection is expired. The operations that are dependent on the connection will just fail if the connection is expired.
there is a new CSV Writer node that replaces the deprecated one and supports an optional file system input port from the S3 connector (click on the three dots like you did it on the transfer node). This way you don’t need the transfer node anymore. The connections are created as required in the new file handling system by the individual nodes.
I have modified my workflow to use new CSV Writer node to write files to s3 and then move to redshift.
When I execute the workflow manually it works fine, but when I schedule the workflow it is giving me this error -
CSV Writer 837:4359 - WARNING: No connection available. Execute the connector node first.
Amazon S3 Connector 837:2789 - ERROR: Execute failed:
software.amazon.awssdk.core.exception.SdkClientException: Received an UnknownHostException when attempting to interact with a service. See cause for the exact endpoint that is failing to resolve. If this is happening on an endpoint that previously worked, there may be a network connectivity issue or your DNS cache could be storing endpoints for too long.
I guess you try to schedule the workflow on a KNIME server? Is this a problem that occurs from time to time or every time you run the workflow on the Server? Sounds like a network/DNS problem. If this happens every time, make sure the server has a working network and DNS connection.
For example, you don’t need to link the Amazon Authentication with the Amazon S3 Connector with the variable port. They’re already connected with the AWS Connection port (the blue square).
Also, you can simply link the CSV Writer to the Amazon Redshift Connector only. Your bottleneck before establishing the Amazon Redshift connection is the CSV Writer.
Regarding the alternative with the loop, you may need to add a couple of things:
Add a Wait node inside the loop (either at the beginning or at the end) to create some delays between retries so you don’t abuse Amazon. This will also depend on how long is the timeout set to. If you’ve already waited 30 seconds because of the timeout, then it should be ok to retry right away.
Add a maximum number of retries - this is a fail safe that’s common practice where you don’t want to be stuck in an infinite loop where you can’t strop retrying because your connections keep failing. You have to set a maximum number of retries that you feel like at that point, you need to give it a rest and it’s not going to work and either retry some other time (may be different time has different traffic) or that something needs to be fixed before retrying.
great workaround with the try-catch nodes, but this should actually not be required and we should discover the problem. Can you explain a little bit how your setup looks like?
What means re-execute manually? Does this mean running the workflow local on your Desktop instead of running the workflow on the KNIME Server?
Does the workflow always fail on the KNIME Server?
Hi @sascha.wolke ,
My setup is, I am using a call local workflow node to call different workflows one by one, which is working fine. Once the call local workflow node is executed I upload the status of the workflow(failed or successful) to s3 and from s3 to redshift.
Now while uploading the status of the different workflows to s3, I used to use legacy nodes which were giving me some network issue, so I started using the new nodes which is also giving connections issues.
Re-execute means if Amazon s3 connector node fails it should re-execute the node. Yes, If the scheduled workflow fails on the server, I execute it manually on local on desktop.
Yes, almost 8 out of 10 times workflow fails on the server.
is there an opportunity to update the KNIME Server/Executors to a more recent version? Can you post the full Error Message and Stacktrace from the Logs? Not sure what goes wrong, but 8 out of 10 times workflow fails on the server sounds very strange.