Dear KNIMErs,
I am still fighting with the use case I described in this post (split by regex)
Now I seem to have a different problem, let me explain:
I extended the list I used in the other question by an employee ID because this pretty much matches what my original file looks like:

The thing I need to achieve now is that in my example the first entry in the name column gets assigned the first Employee ID from column B.
The result should look like this:
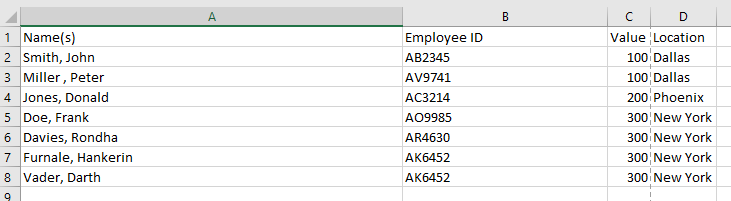
I tried it with the Unpivot Node as described by @Kathrin in the original post and then created a helper column the String Manipulation Node to create a unique value I used then for duplicate deletion utilizing the Row Filter Node.
But somehow it doesn’t work for the Employee ID’s.
The basic “rule” I want to implement in KNIME is this:
- the first name in column A gets assigned the first ID in column B
- the second name in column A gets assigned the second ID in column B
- the third name in column A gets assigned the third ID in column B
… and so on…
Thanks a lot in advance.
list-of-names_v2.xlsx (12.6 KB)
