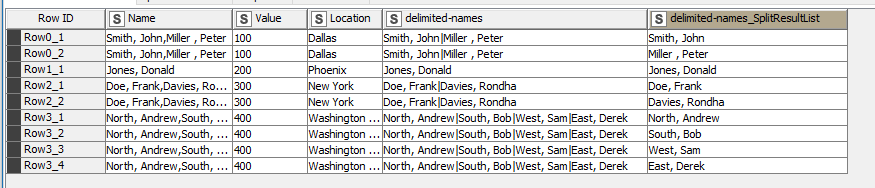
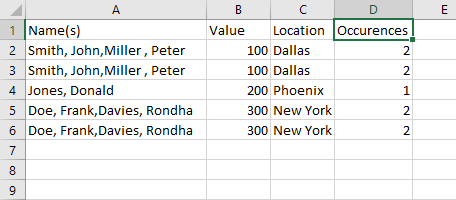
Hi @kowisoft, I wouldn’t feel stupid about it… the problem is that the data here and the ability to use the rank node is slightly contrived as the number of rows that an occurrence of “Name” appears in, in your initial data set is directly related to the number of individual names within the data.
So the Rank node is then able to provide an ordinal ranking grouped by Name, so assigns 1 for first occurrence, 2 for second and so on. This allows it to work in this situation and provide $1, $2 as required to retrieve each of the individual names from the data.
However, it only works because of the repetition already provided in the supplied data.
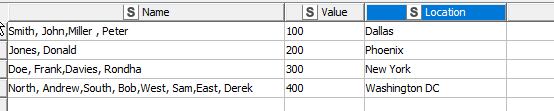
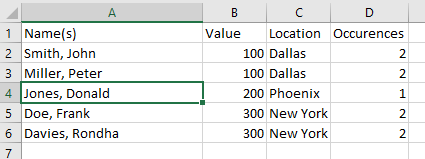
If your data had started as simply:
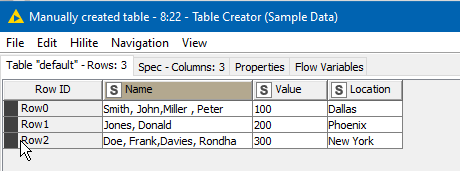
A different approach would be necessary, as rank would just assign 1 to each row, and you’d never get the second name returned.
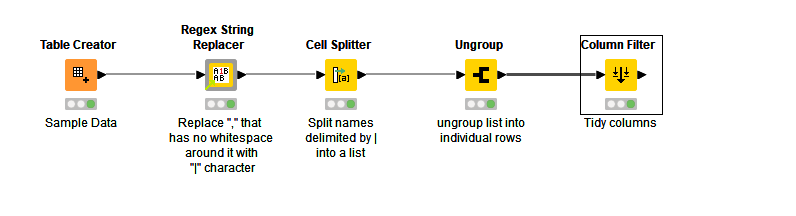
Ideally, we would want to be able to easily split up any number of delimited names into individual rows, but there are some limitations here with doing this with regexreplace within String Manipulation. As it stands in the above workflow, it only handles at most a pair of names. The presence of some commas in the names which are not delimiters of individual names makes it additionally difficult to split them up using the cell splitter, as it is difficult to differentate “different types” of commas.
It can be done with a java snippet though, and for convenience, I have wrapped this into a component which I have just uploaded to the hub (I based it on a slightly different component I uploaded back in June). I have used it in the workflow below.
The basis of this is replacing commas that have no white space around them with a different delimiter the pipe “|” character, Then a cell splitter can split the names on | and return them as a List data type, which can then be ungrouped into your individual names. As you can see, this then works without the data having to be initially repeated, and with more than two pairs of names in the sample data:
Sample Name splitting.knwf (25.1 KB)

 is highly appreciated. Took some Udemy courses but they were “meh” (or I was not clever enough, who knows…
is highly appreciated. Took some Udemy courses but they were “meh” (or I was not clever enough, who knows… 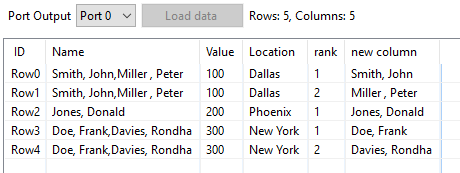

 )
)