Hello - I have completed the Udemy bootcamp course for Knime. I found some of it helpful. I am a complete beginner (not a programmer or data science student at all) so I think it’s not exactly at a beginner level (in my opinion) still a good starting point because my questions may be more “articulate” now.
I’m behind a proxy so some links/resources I won’t be able to review at work but i will do so at home.
Data Access question - trying to piece info and use the correct terminology:
We have a work server. I have an accounting application called quickbooks on my desktop that reads the file on the server.
can Knime access the data in this application? How?
I am working on the data mining activities in the udemy course. I’m missing understanding the “why” component to a lot of the explanations.
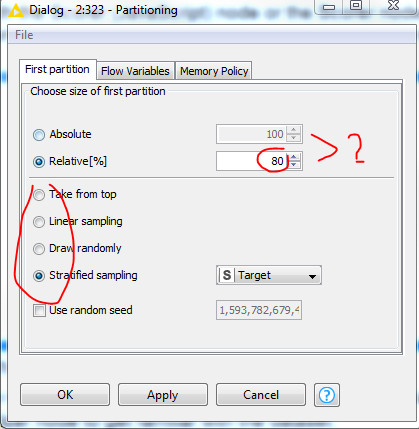
For example, for partitioning - why do I set the relative value to 80%? what is the benefit of this? why not 90%? why do I use stratified sampling as opposed to draw randomly? the whys weren’t explained clearly in the online course. I have even more questions but that would just fill up the entire post. It was so technical, I think my mind blew up. Can someone point me to an even more basic thread or resource?
Hi @mayankgupta, I can’t help you on the data access question, because it’s a filetype unknown to me.
But for the second on data mining I could try to explain it.
The basic idea behing partitioning is that you split your data set into a trainingset and a testset. The trainingset is used create a model (in a Leaner node).
The testset you use to see how well this model works. You let a Predictor node apply the model on the testset and use a Scorer node to check the predicted value against the actual value.
Since the testset is independent from the trainingset (it’s other data) it gives you a more objective way to measure the quality of the model.
The usage of a percentage of 80% is a bit arbitrary. It also depends on the amount of data you have. The more data you have, the bigger the testset can be made. If possible I like to use 70% for the trainingset.
This default value of 80% is a rule of thumb of which you can deviate. Just play with it and see how this influences the accuracy and precision of your model.
The option to choose in the second half of the configuration window depends on the type of data you have:
“Take from top” is typical for modelling timeseries data. Timeseries data sorted on date and you use the oldest dates for the model and the most recent for the test. This is because one uses the model to forecast future values.
“Stratified sampling” is e.g. useful when you have to predict a categorical value and the possible values of this category are not distributed evenly. Suppose a column can be A or B, but 99% is A and just 1% is B. By stratifying on this column you have in both training and testset the same 99%-1% distribution.
This will improve the performance of your model.
“Linear sampling” is useful for large datasets which you need to downsample (make smaller), while maintaining a minimum and maximum value of a (numerical) column. Means the dataset must be sorted on this particular column.
For the application - is there a ‘model’ to follow though? yes I understand the file type may be unfamiliar, but would there be a method/workflow to try and access?
So in order to learn/explain it like you, how do you get there? i.e. you were able to ‘dumb’ it down for me. I’m okay to keep googling everything and I"m going to continue to take more courses in this and python.
I’m afraid I can’t really help you on the QuickBooks database. There is a DB Connector node, but in order to configure this correctly for your database you probabaly need some driver for it.
For the learning and explaining: over the last 5 years or so I followed many data science courses and did exams.
In april I joined the Spring Summit 2020, which was held online. Learned a lot on how Knime should/can be used for different types of problems.
If you want to get more background on Knime search on youtube for knime (and knimetv). There are many short video’s to explain things. On the Events calender you will see there are regularly webinars held, which you can often join for free. Previous webinars are published as well online. There are courses too, but these will cost you some fee.
So it doesn’t come overnight, but you do the right thing: keep on asking!
Google found this driver that promises to give access to quick books but it is not free and I have not tested it and there are some quite negative reviews out there …
It might be better to look for options to export the relevant data from the system as tables (CSV, Excel, …) and then import it into KNIME.
Then you could see if there are examples of access to quickbook files with R or Python since KNIME could use them.