Here I would like to know the best practices for read the large amount of data tables into KNIME. while I’m reading large DB.Table (20GB/7M rows) data KNIME nodes ((Data Query Reader/ DB Table Reader ) taking hours or end with execute failed.
Not sure how to execute the large datasets in KNIME.
I’m sorry to hear that you have problems reading large amounts of data from a database. In general this shouldn’t be a problem also if the data is much larger than your memory since KNIME cache data on disc if necessary. However as Sascha mentioned we recommend you to push down the data preparation into the database as far as possible to make use of the databases processing power.
To better help you, can you please be a bit more specific e.g. which database are you connecting to, are you executing complex queries e.g. with lots of joins or only simple queries e.g. SELECT * FROM table, and what error messages do you get in KNIME
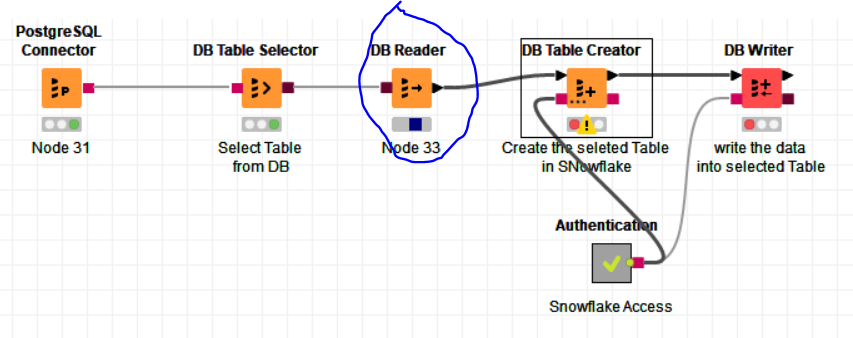
Its very simple workflow, we are reading a table from postgresDB, then writing into another DB in snowflake. I don’t have any issue with small table (<300MB size). But, we have a Table size 20GB which are struggle to process.
If I understand correctly, we need to read the data from table then pass into chunks. But, we have issue with DB Reader/DB query reader nodes it’s not pass data to next node. it’s either taking hours or execution failed.
really I need to understand, how we send the data chunks wise before reader node ?.
@kotlapullareddy with the streaming you would do the downloading within the streaming component and so only get a few rows per chunk. Maybe you take a look at the examples provided.
The DB Connection is inside the component:
Do you have any IDs or RowIDs you could select first and use to reference a chunk?