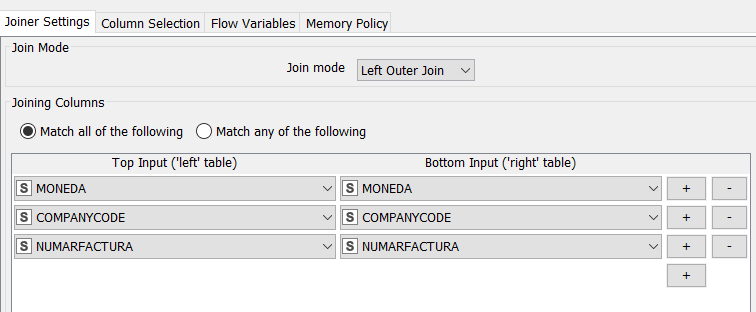
I have to create a workflow with two input files, each of around 20 mil rows. I have to compare the data from each of the tables, based on 3 columns see below.
However, I do not know how to make this into a loop so that the workflows executes each 2 mil rows iteration, joins the data and then outputs it to a concatenate node or something else so that the “final” output is the sum of all iterations. As you can see in the joiner picture, I am interested in adding in table A, all rows that match the criteria.
I have tried using a chunk loop start node, however I don’t know how to join this (it gives the error “Unable to merge flow object stacks: Conflicting FlowObjects: <Loop Context”).
All the help or suggestions are very much appreciated.
If you could use some sort of loop very much depends on the nature of your data. If the table that has to be joined is significantly smaller that the left a (chunk) loop might be an option. But this depends on the data. What kind of duplicates would you expect to occur and how would you handle them?
As mentioned by @mlauber71, the solution to your problem will be “nature data” dependant on what you expect to get at the end. Here you are trying to join 20 M to 20 M rows. I guess you are not eventually expecting as results 4 x10^16 rows but many less. However, if you try to solve this by “brute force”, i.e. using directly a joiner, the joiner will try all these possible combinations, even if eventually it comes to much less matches. Useless to say how useless and frustrating this can be . So before trying to use BIG data tools such as SPARK or HIVE in a 4G computer (or even on a very powerful cloud), it may be better to think about what could be done (and what cannot) depending on the nature of your data.
First question one should try to answer is how many matches one expects at the end of your joining ? Do you have an answer to this question ? Otherwise, this question could be preliminary calculated or estimated at much less computational cost than directly doing a “joining”.
If the answer is “not that many”, lets say a few 100 thousands, then there is still hope and people could share with you a few tricks to achieve your task, but definitely not doing it directly using a joiner.
I’ll be happy to help to contribute with possible solutions if you could answer this question.
To add more details regarding the data and the output, I would expect to have an almost 100% match between the two tables, as this is the purpose of the workflow to test if the all items from one source are also in the other, and then adding Math Formula Node to check the difference between each item’s value between the two tables.
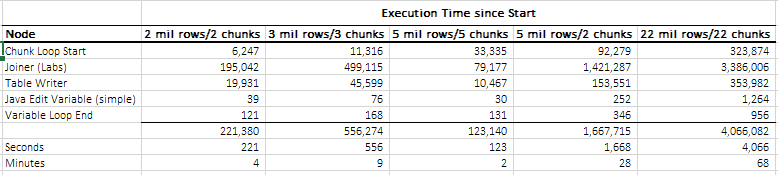
I tried the new Joiner node, and wow, huge improvement in performance, see below.
I will try integrating the column storage nodes to see how they can help.
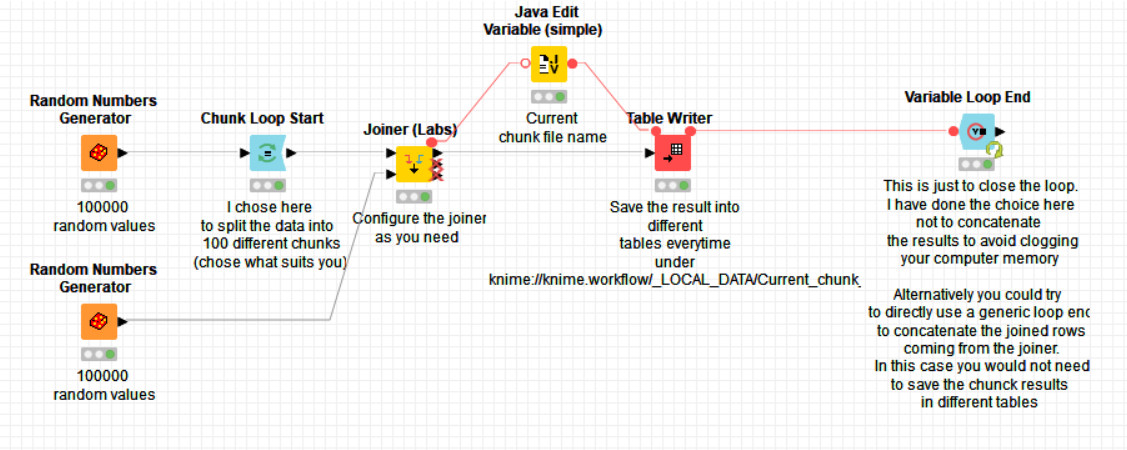
I was thinking using a chuck loop node and then a joiner as:
I would like to do 1 mil rows at a time
I would thus have a progress/status of the joining, i.e. lets say that each input is comprised of 1 file that contains data for 12 months, if I will do each month as a chunk I can then isolate it and analyze it separately.
The problem here is that I do not know how to do the chunk loop and Join, as I get the error message ““Unable to merge flow object stacks: Conflicting FlowObjects: <Loop Context”).”.
Thanks for this very useful extra information and your prompt reply.
When you say 100 % match, does it mean 20 million rows at the end (about 1 matched row to 1 matched row) ?
If I take the Joiner (Labs) result for 1 M x 1 M rows comparison, and I extrapolate to 20 M x 20 M, this shoul take around 40 minutes to be run on your computer. Please could you confirm that “1 mil” means 1 million ?
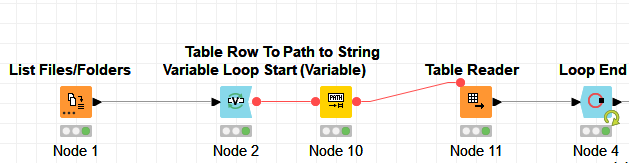
If this is the case, the best solution to implement is to use a chunk loop. I’m attaching here below a snapshot of a possible solution (on dummy data for the example):
Yes, by 100% match I expect the 20 million from table A to also be in table B, as such the output would be a table of 20 million rows.
Yes, the extrapolation makes sense, that is why I tried different sample sizes, ending with 1 million (mil).
In the image you shared, each chunk will be different, meaning it would not sample the same chunk twice, right?
In this workflow, if I understand, it will chunk 1 mil from table A and join with the full table B?
Thank you very much for your help and quick replies.
This is what I guessed from the headers of your columns. Good news. This should be hence feasible.
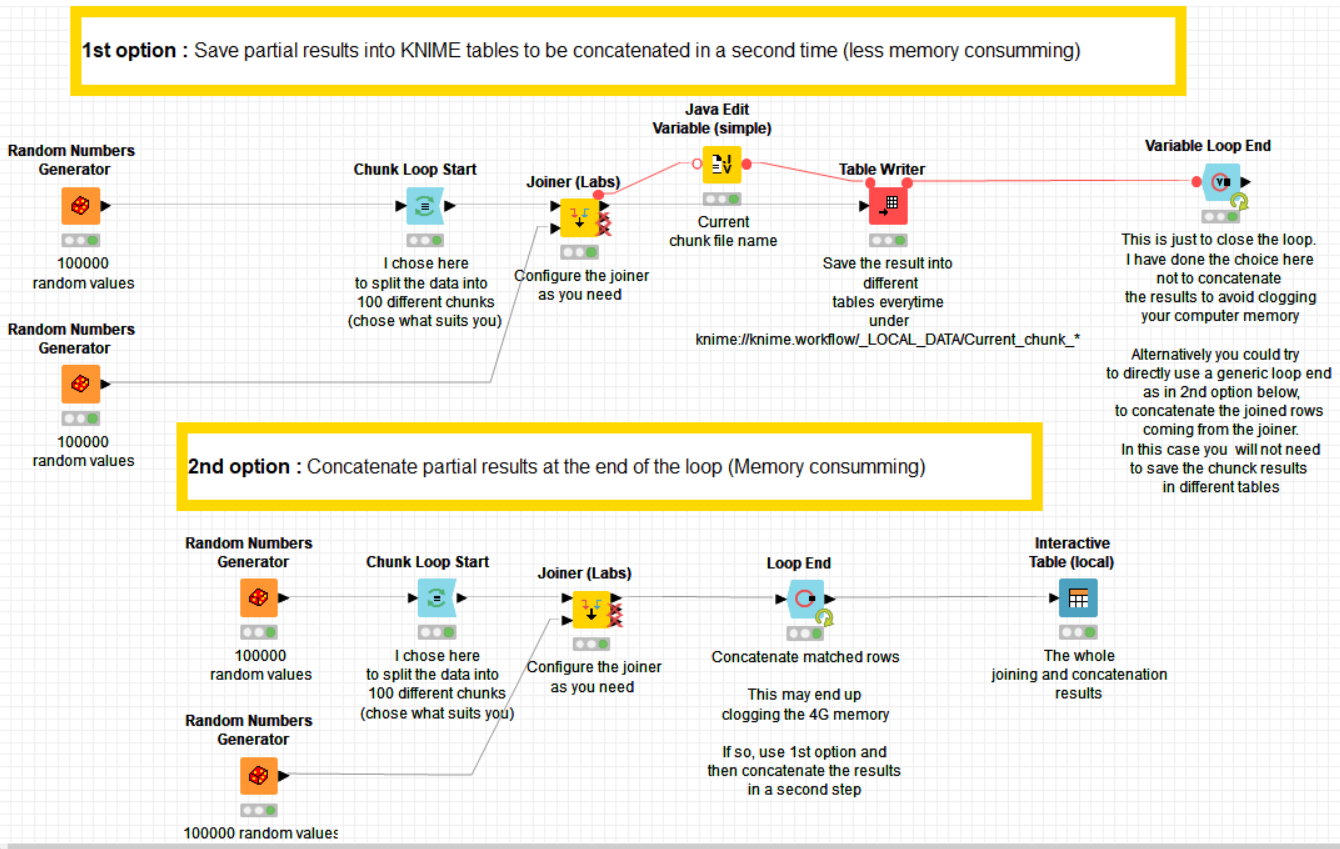
Exactly, but all the comparisons will be eventually done. By the way, the most probable reason why your initial workflow crashed after 40 minutes (the same as the estimated time) is that all the comparisons were done by the joiner (which is doing it by chunks in the background and saving partial results in disk) but then it tried to concatenate everything “in memory” and hence the reason for crashing. This is why I’m not concatenating the results at the end of the workflow but saving the results. You could modify the loop so that it does the concatenation too in case this first version works.
Could you please elaborate on that or link to a resource on why you think so? Can the current setup only run on a single machine?
It was presumably to good to be true to avoid the whole big data spark setup and apply big data analysis/transformation in KNIME instead of pyspark/ databricks.
Topic is rather new to me so your input is highly appreciated!
best regards
@Daniel_Weikert the Big Data environment by KNIME per se does live on a single machine and is therefore linked to the resources of that environment. I do not know any way to use it on more than one instance; typically, that would be a job of a ‘real’ big data system like a Cloudera system or something derived from the Apache stack.
Then: Big Data is not some magical thing but is there so that you can scale up operations on a potentially unlimited amount of data while the single nodes within a Big Data system can execute their jobs independently (and will later collect the results). So the use of Big Data should be considered if your data is so big that ‘normal’ databases can no longer handle the data.
So you can use Hive technology with the environment but you still would be limited to the resources of your machine.
I would use the local Big Data environment to develop use cases on my machine and then deploy them to a ‘real’ big data environment. An example is given here:
Then the local environment does not provide PySpark. You would have to individually install and establish that.
If you are interested in further information about these subjects you could explore this collection:
Here is a collection of methods you could execute from KNIME on a Cloudera Big Data system:
Highly appreciate your answer (including a video). Now I have an idea who mlauber actually is
Even though I once assumed based on your knowledge and your willingness to help you have to be a KNIME Team member.
br
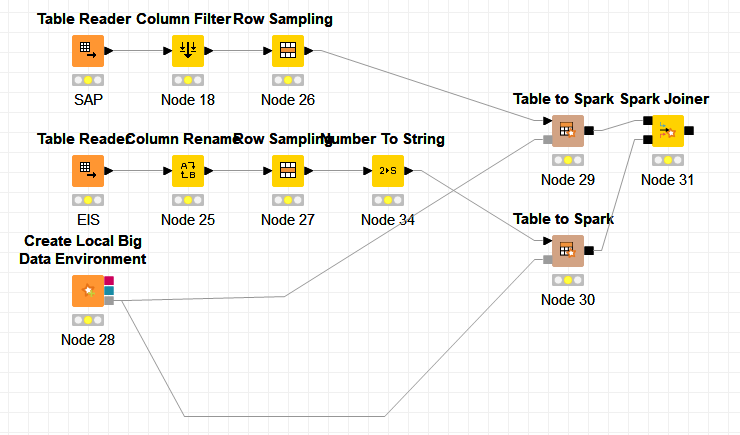
 . So before trying to use BIG data tools such as SPARK or HIVE in a 4G computer (or even on a very powerful cloud), it may be better to think about what could be done (and what cannot) depending on the nature of your data.
. So before trying to use BIG data tools such as SPARK or HIVE in a 4G computer (or even on a very powerful cloud), it may be better to think about what could be done (and what cannot) depending on the nature of your data.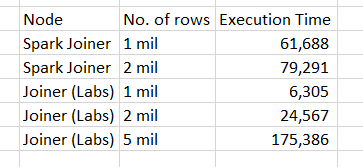
 !
!