Hi,
apologize in advance but this is going to be a rather lengthly bug report.
While in a meeting with @DanielBog (wasn’t it you?) and Peter Schramm (I cannot find his nick), I accidentally stumbled across another bug we chucked away as a glitch (explained further below). At least we concluded it was not worth sharing.
However, I now face a much more severe issue where Knime becomes totally inresonsive requiring me to force quit it. Previewing data seems also impossible (again continue reading). Heap Space is still changing, memory and CPU utilization in the task manager fluctuate too but I only hear the chime after trying to configure the RegEx Extractor from Selenium (@qqilihq FYI).
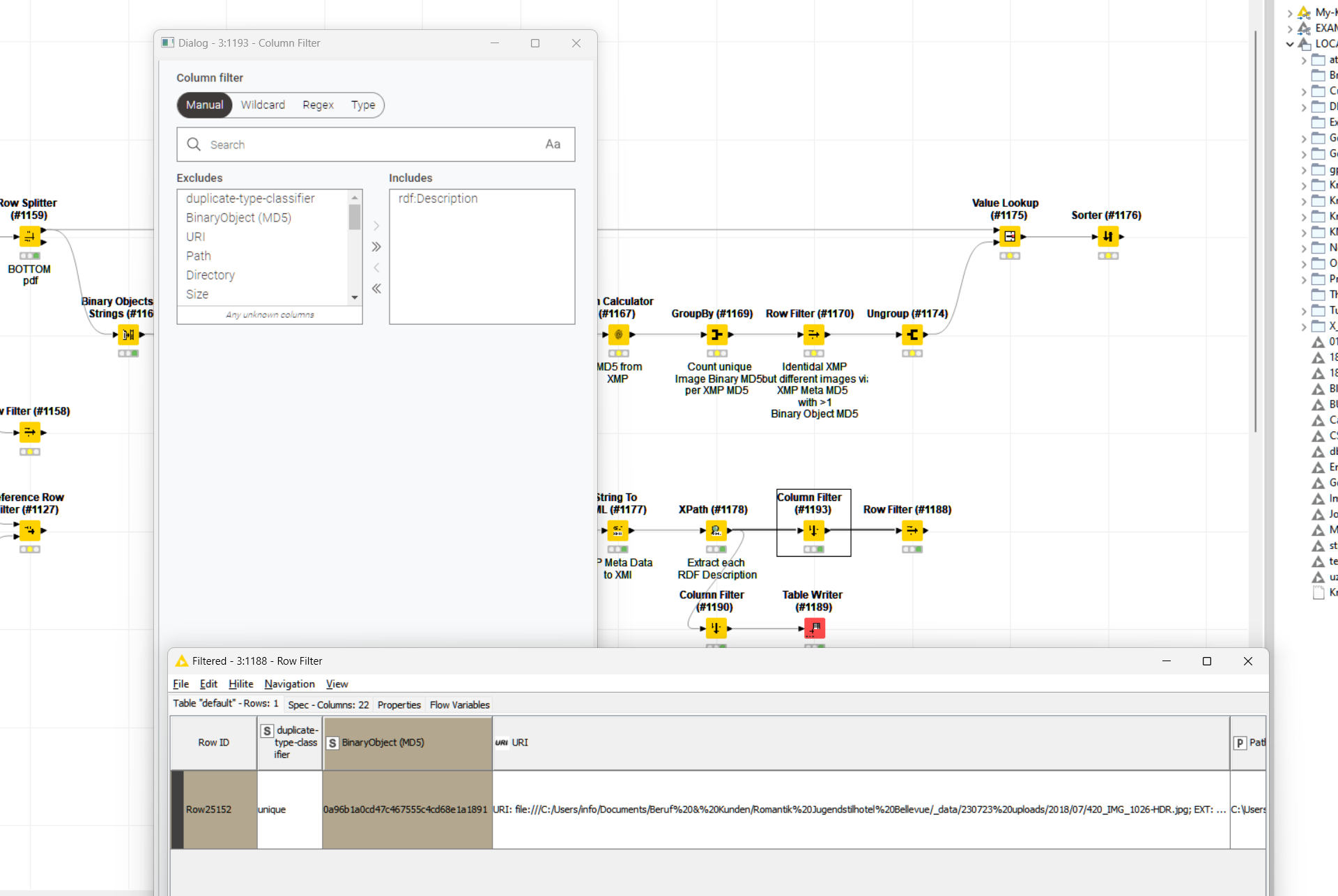
I post this in this forum as the aforementioned “chucked away” issue was with the XPath Node where the UI became inresponsive for about 30 seconds upon first opening the node configuration. Upon second opening, it was fast as usual.
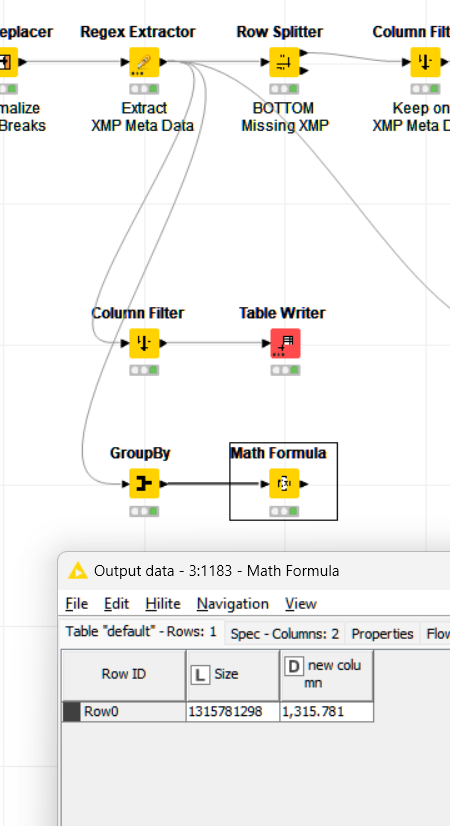
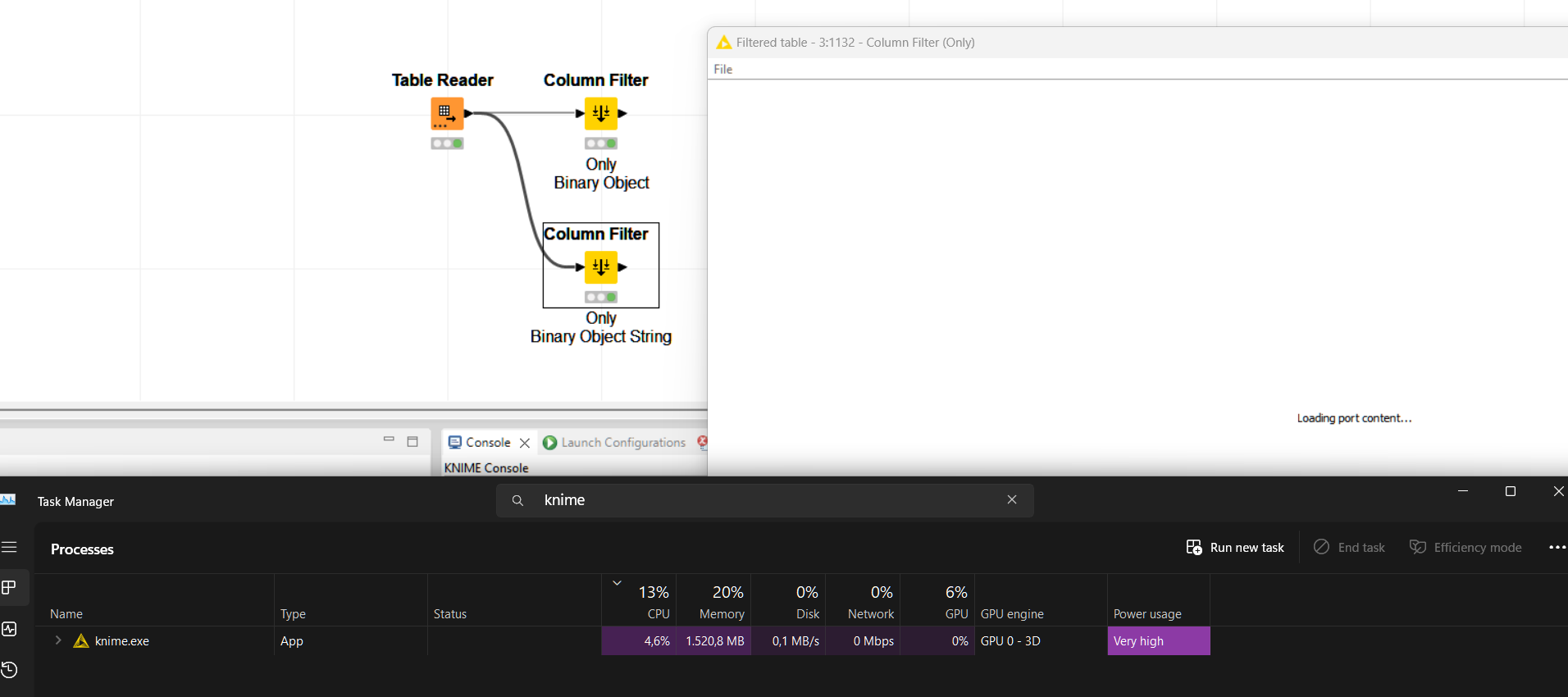
I presumably tracked it down to the precense of a binary object column. Removing an impage column didn’t made a change and trying to preview the data actually never finishes either. Closing the preview window doesn’t work so I am again required to force quit Knime.
Note: I have extended the example workflow form another bug about the MD5 calculation in the string manipulation node.
My Knime config I cannot share as it is >5MB and ZIP / RAR etc are not allowed for upload …
Best
Mike