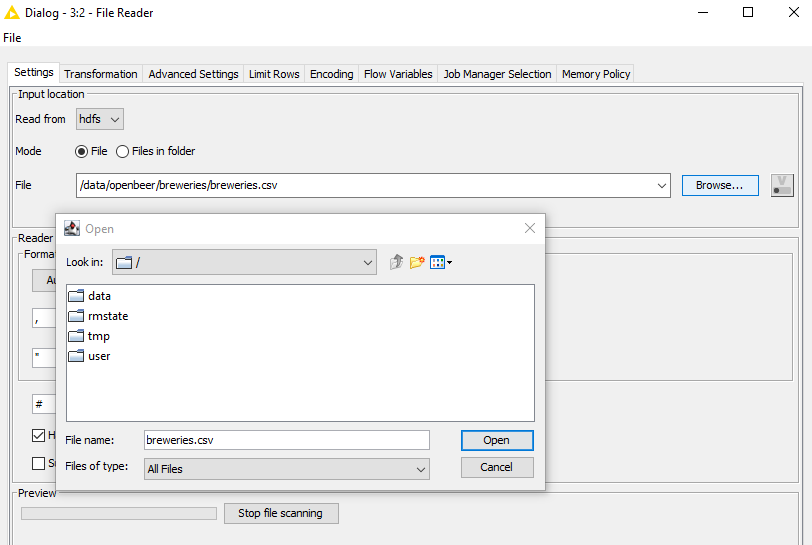
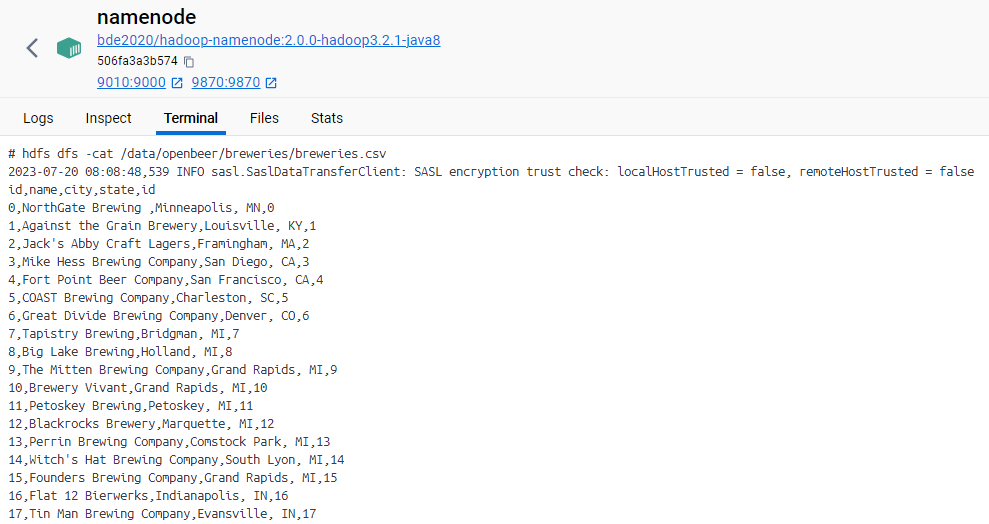
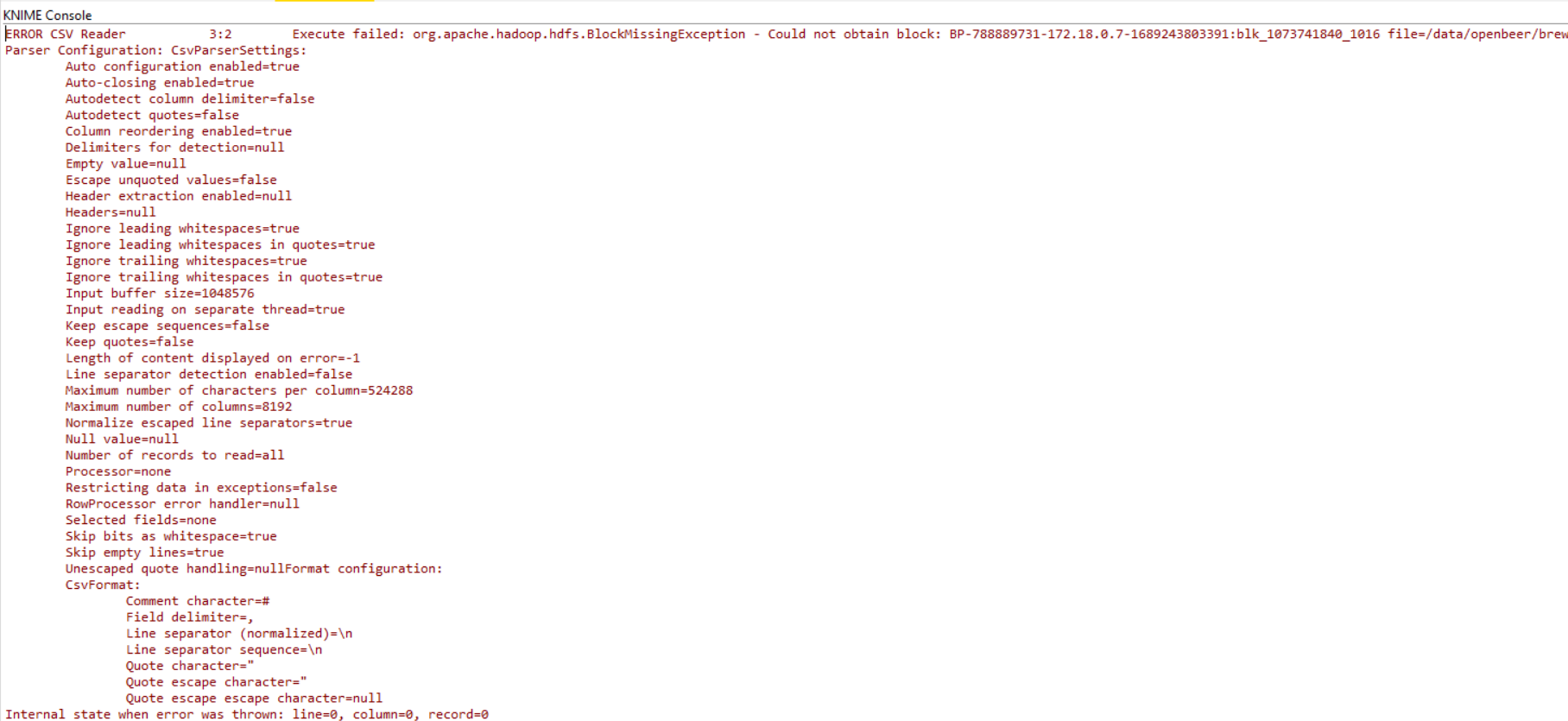
I am currently trying to read in a csv-file from my Hadoop cluster in KNIME and keep getting this exception org.apache.hadoop.hdfs.BlockMissingException - Could not obtain block: BP-788889731-172.18.0.7-1689243803391:blk_1073741840_1016 file=/data/openbeer/breweries/breweries.csv.
My Hadoop Cluster runs locally with Docker. I successfully connected my Hadoop Cluster with KNIME through the HDFS Connector. But whenever I try to read in a simple CSV File which I stored in my HDFS File System it can’t seem to be able to access the file. Which is really weird cause KNIME seems to be able to see my HDFS File structure with the CSV Reader.
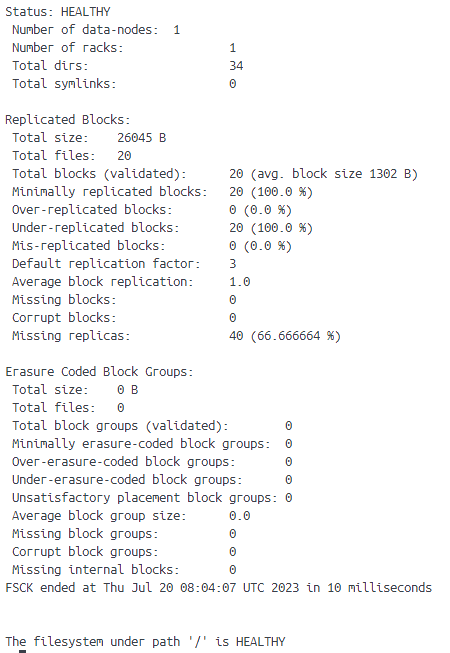
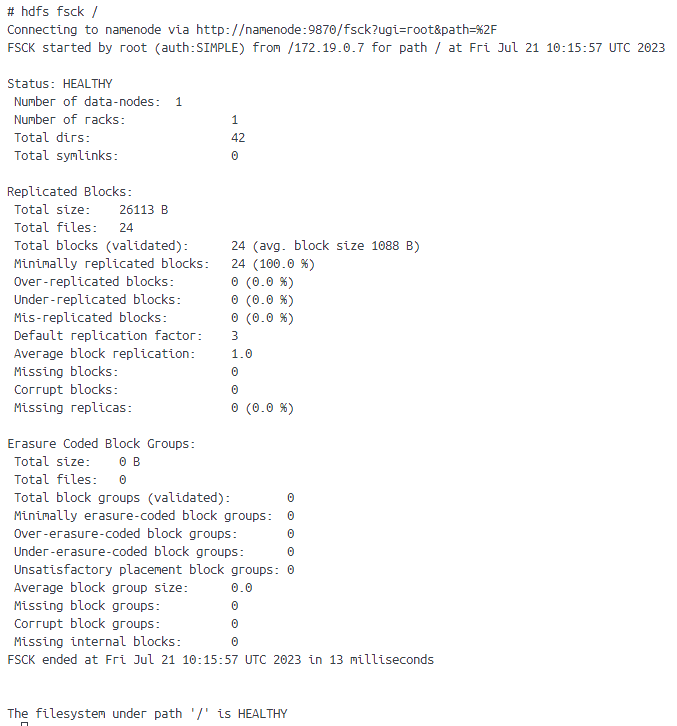
I already went through some post with similar problems and tried several solutions including some where corrupt files where included as the cause of this exception but I already checked through commands like hdfs fsck and my nodes seem to be healthy.
Not sure what container you are running in your local docker setup, but what is the health state of your cluster? Maybe check the Web-UI of Hadoop and the logs, if there are problems distributing the blocks in the cluster.
And I am able to access my CSV File from the shell without any problems.
In theory that means that my Namenode has unrestricted access to my Datanodes.
So we can disclose any host/port related problems.
Your screenshot mentions that the data is under-replicated. Default replicated settings in HDFS are 3 replicas, but you only have one data node. You might be able to fix this on a single file using the cli (see here) or change the default via dfs.replication in the hdfs-defaults.xml (see here).
Do you have any other suggestions I could try? I really want to know how exactly the CSV-Reader works and what commands it uses when trying to fetch the CSV-File.
In theory it should be possible cause I am able to access the files in the Datanodes from my Namenode through simple commands in the shell.