As a new user I'm trying to use Nominal Value Row Filter to select a subset of rows in a data table, based on specific values in a selected column. My problem is that the column I want to select doesn't appear in the list of columns in the node dialog. There are 23 columns in the table I want to filter but only 8 columns are available for selection in the filter dialog.
I've had this happen in two separate, different workflows now. Can anyone advise on why this problem might arise and if I can do something to avoid it? I've not been able to find a solution through searching.
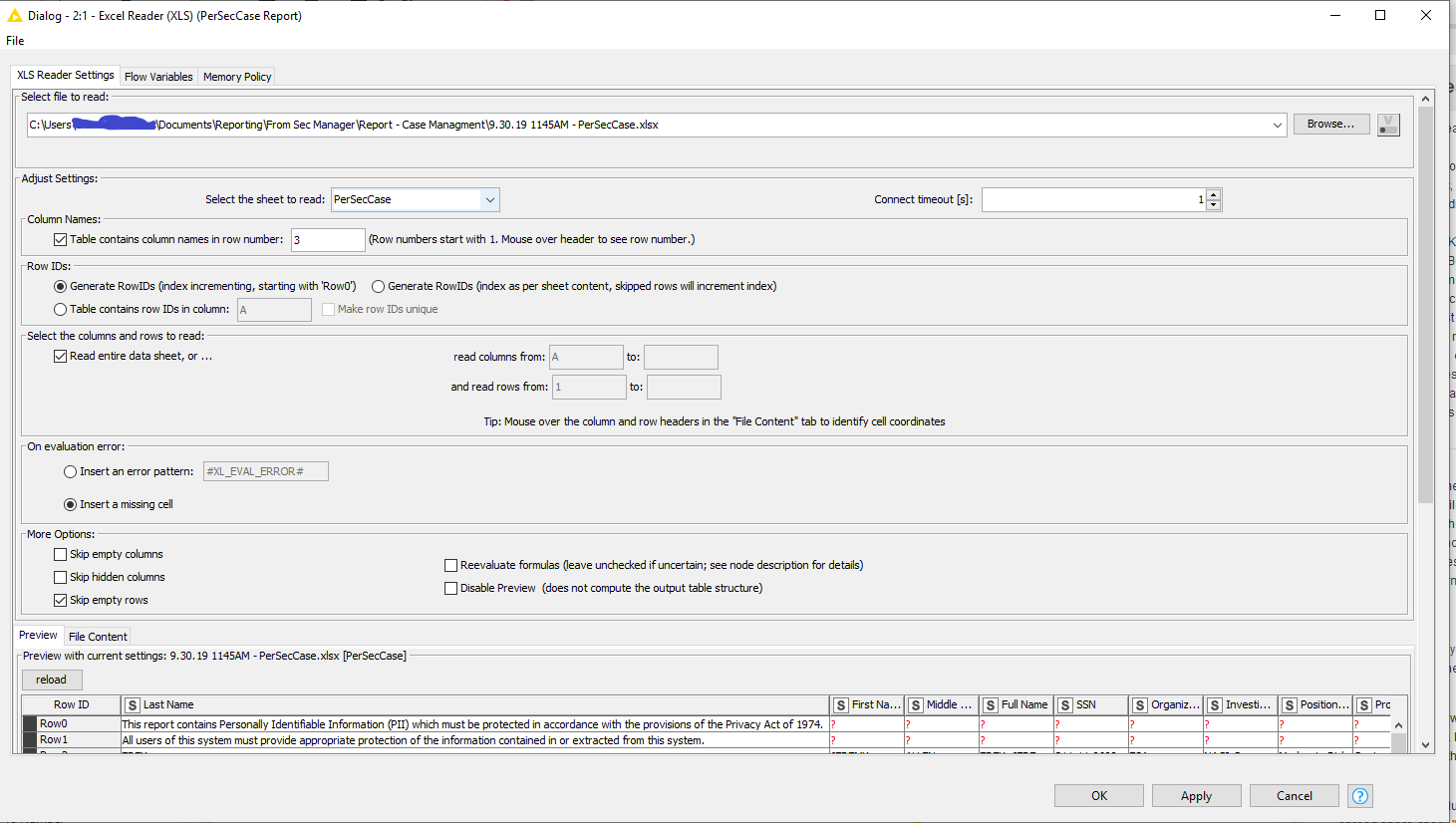
In this picture you can see that there are 5 string columns (Last Name, First Name, Middle Name, Full Name, and SSN) before the sixth string column Organization Name.
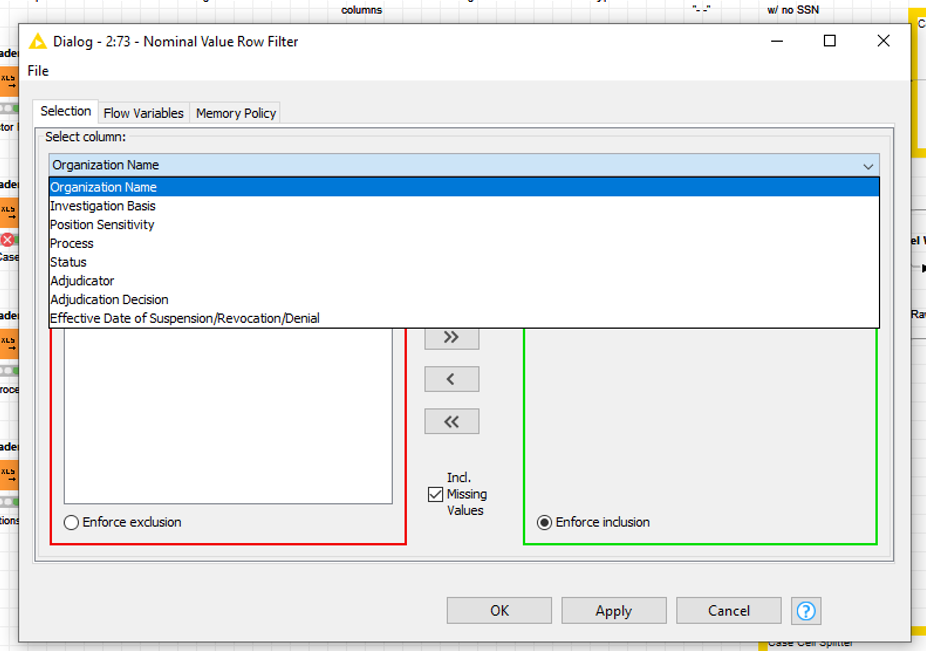
In this picture you can see that the Nominal Value Row Filter configuration only shows the string columns starting at the column Organization Name and on.
I tried to make an example data set by altering the table with dummy data (created a new tab in the same excel file and deleted the majority of the records). When I did that, my “example” actually showed the first five string columns that I was looking for in the Nominal Value Row Filter configuration. Unfortunately, when I changed the Excel Reader configuration back to my original data set it went back to only showing those string columns after the string column Organization Name and on.
Unfortunately, I cannot recreate the situation. Does using the Column Auto Type Cast node before the Nominal Value Row Filter node help?
If not, May I know what are you trying to do? Maybe we can find an alternative solution.
Thank you so much for trying armingrudd. What I am trying to do is really simple, I have two rows, row0 and row1, in the Last name column that I am trying to filter out of my data set. I am a former Alteryx user and in that software there is a configuration to “skip first N records”. I have not been able to locate an equivalent option in Knime. I know that I can use two row filter nodes, one for each row I am trying to exclude, but I’m looking for an option more dynamic.
The reason why certain columns are not seen in Nominal Value Row Filter (or Splitter) node is because they have more than 60 unique values. In KNIME domain is not automatically calculated for those columns. To solve this you can use Domain Calculator node and uncheck option Restrict number of possible values. For some nodes in node description this is mentioned so it will probably be added for two mentioned above as well. Domain information for columns can be checked in output view under spec tab.
Now to your row skipping. In Excel Reader node there is option Read entire data sheet, or…. You should uncheck that option and specify from which row to read data. The row number is an absolute number from Excel sheet.
Now to Alteryx switch. Here is topic you can check. There you have links to another two interesting topics and also link to just published guide From Alteryx to KNIME. Hope it will help.
This makes so much sense re: the unique values limitation. My data set has over 50K unique values. I have explored the options in the Excel Reader node to specify from which row to read data but I got a little turned around and frustrated because of the volume of my data set. I run this workflow multiple times a week and I didn’t want to change the excel reader configurations for the column rows every time I changed the input. This sent me on the hunt for a more dynamic option because I will consistently have to delete the first 2 rows of every data set that I generate and run in Knime.
The links that you provided re: the transition from Alteryx are very helpful. I initially was extremely frustrated with my transition but after many late nights of searching the forums for advise and guidance things are definitely getting better.
I truly appreciated everyone helps with trouble shooting this issue!