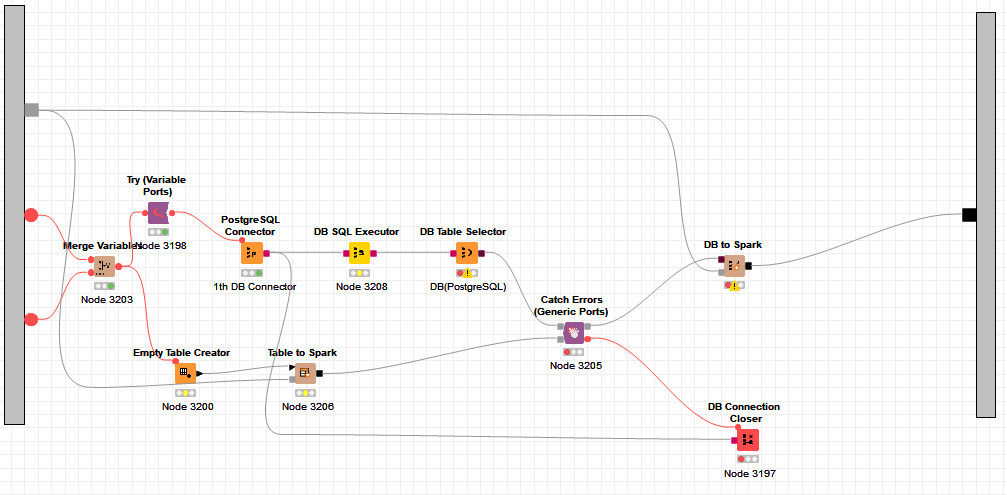
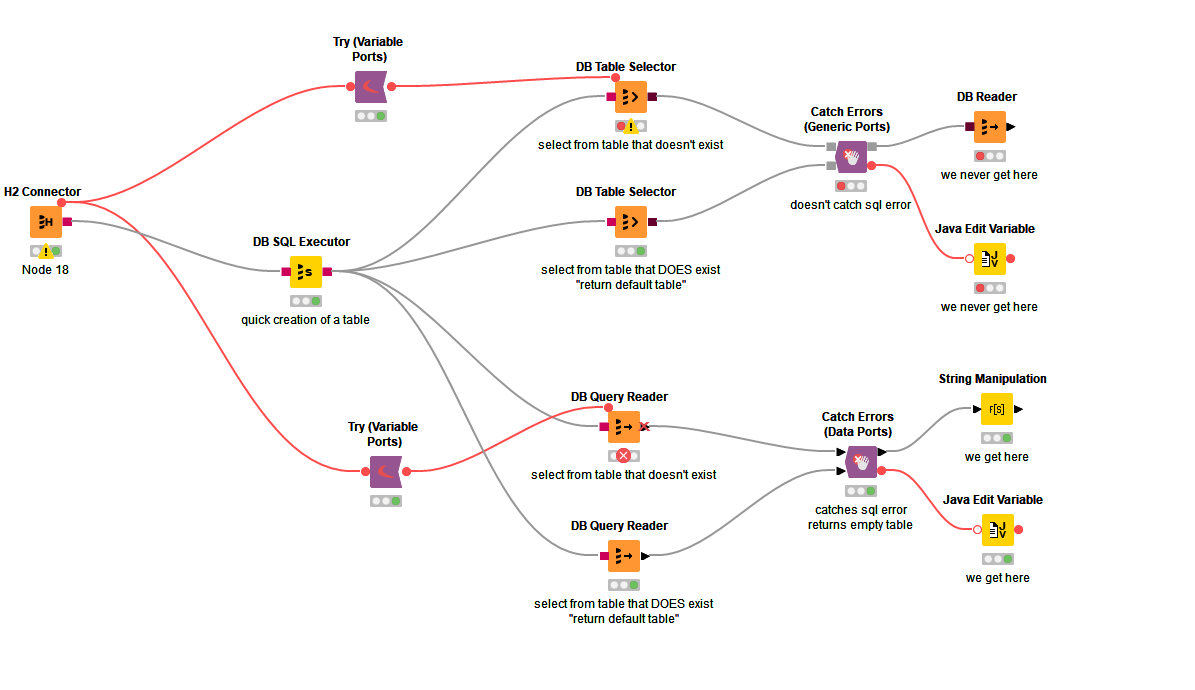
Hi @JaeHwanChoi , yes I feel your pain having to do a two-stage process of DB SQL Executor followed by DB Table Selector to enable error checking.
In the DB SQL Executor, are you simply executing the query as supplied by the user? You should be able to cut it down to be a small overhead with either 1 row or even zero rows, rather than double time if you can “wrap” the query with an outer select, which should still then make the query testable.
e.g. if the user supplies:
select x,y,z from my table where something=c
you could wrap it with something like:
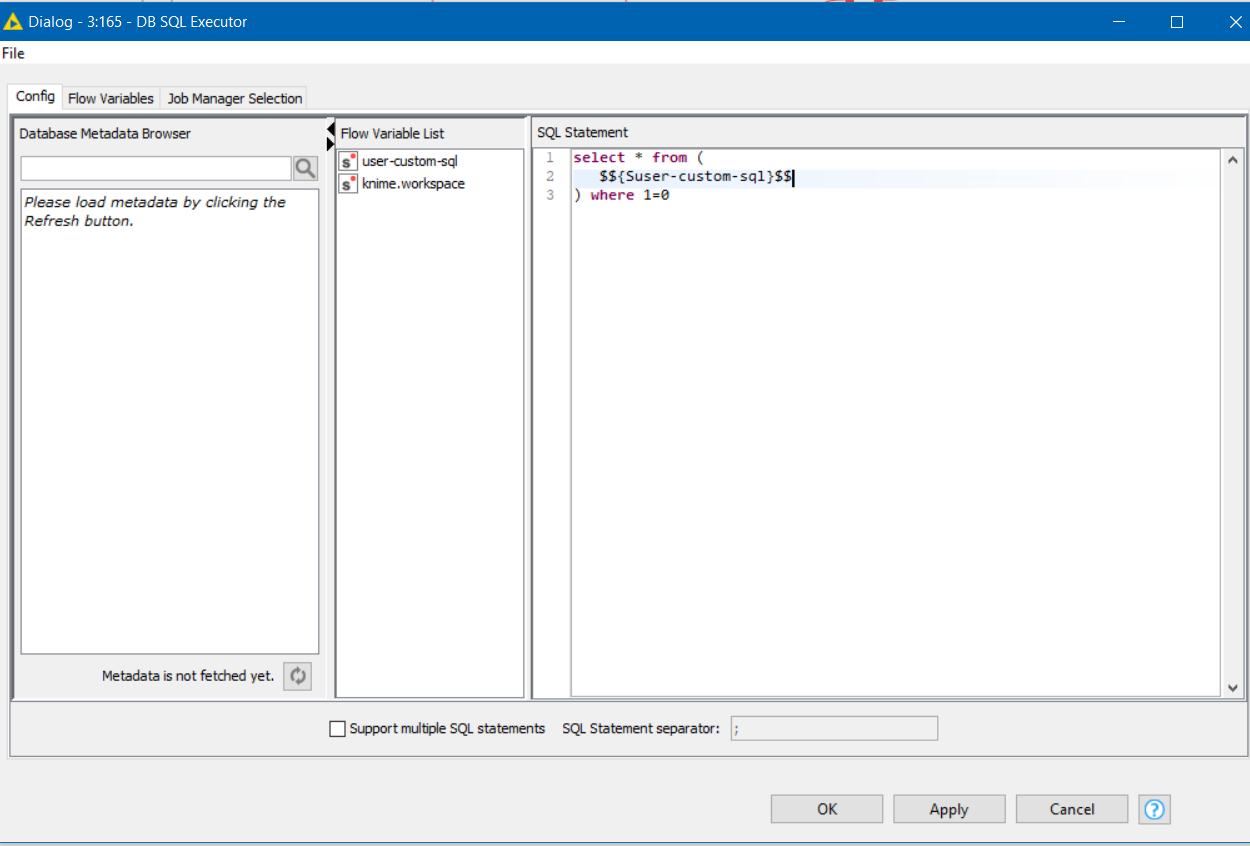
select * from (
select x,y,z from my table where something=c
) fetch first 1 row only
or
select * from (
select x,y,z from my table where something=c
) where 1 = 0
This should greatly reduce the execution time for the DB SQL Executor.
Typically in KNIME, a configuration error is a mis-configuration of a node that would prevent it from being able to execute. This can still occur at execution-time if the configuration is being dynamically set by flow variables. For example a String Manipulation node containing invalid syntax in a statement passed into it via a flow variable would still be a configuration error. Such errors block the execution of the node and cannot therefore be caught be error-handling. You can think of this as being like a compilation error in a traditional programming language
An execution error on the other hand would be something that allows the execution of a node to occur, but results in a run-time error occurring which can then be handled by try-catch. In a traditional programming language this could be a “file not found” or “division by zero” error for example.
With KNIME it isn’t always clear without experimentation what will be considered an error and what won’t. For example in Math Formula, division by zero results in a “missing” value rather than an error that can be caught. In Java snippet, an error/exception that is thrown other than an “Abort” results in the happy continuation of the workflow as if nothing had happened. In Python, meanwhile, throwing a runtime exception halts the node (I haven’t experimented to see if that one can be caught by a catch-node).
It is difficult to decide whether an invalid SQL statement should be treated as a configuration error or an execution/runtime error. There are a wide variety of error types with SQL, and the validity of a statement such as “select x from mytable” when written as a custom-query cannot be determined at configuration time because “mytable” may or may not exist at that point, and so I feel it should be considered a runtime/execution error, just as it is with DB Query Reader and DB SQL Executor, and handled as such. That there is contradictory behaviour between what appear to be similar situations to me is a problem. I would prefer that an invalid query were always treated as a catchable error.
But that is only my take on it, and there may be other underlying technical reasons why with that specific node, and its potential interactions with other downstream in-database nodes, it has to be considered a non-catchable error.