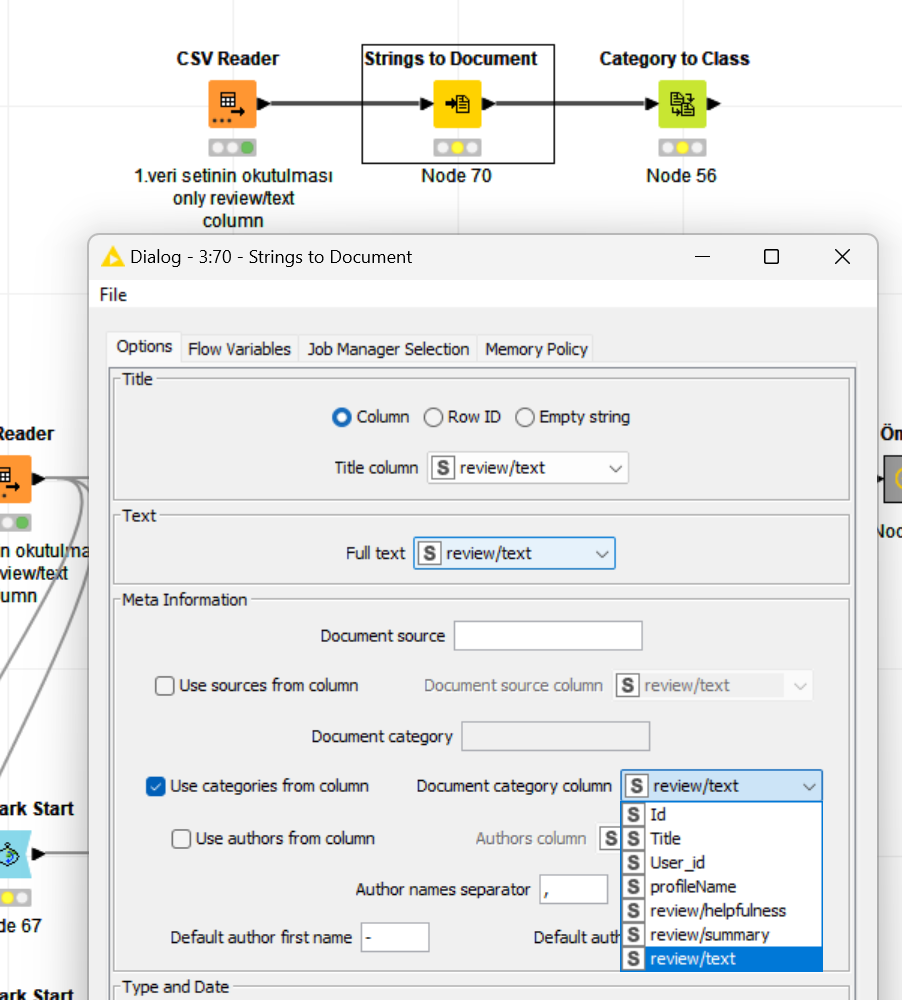
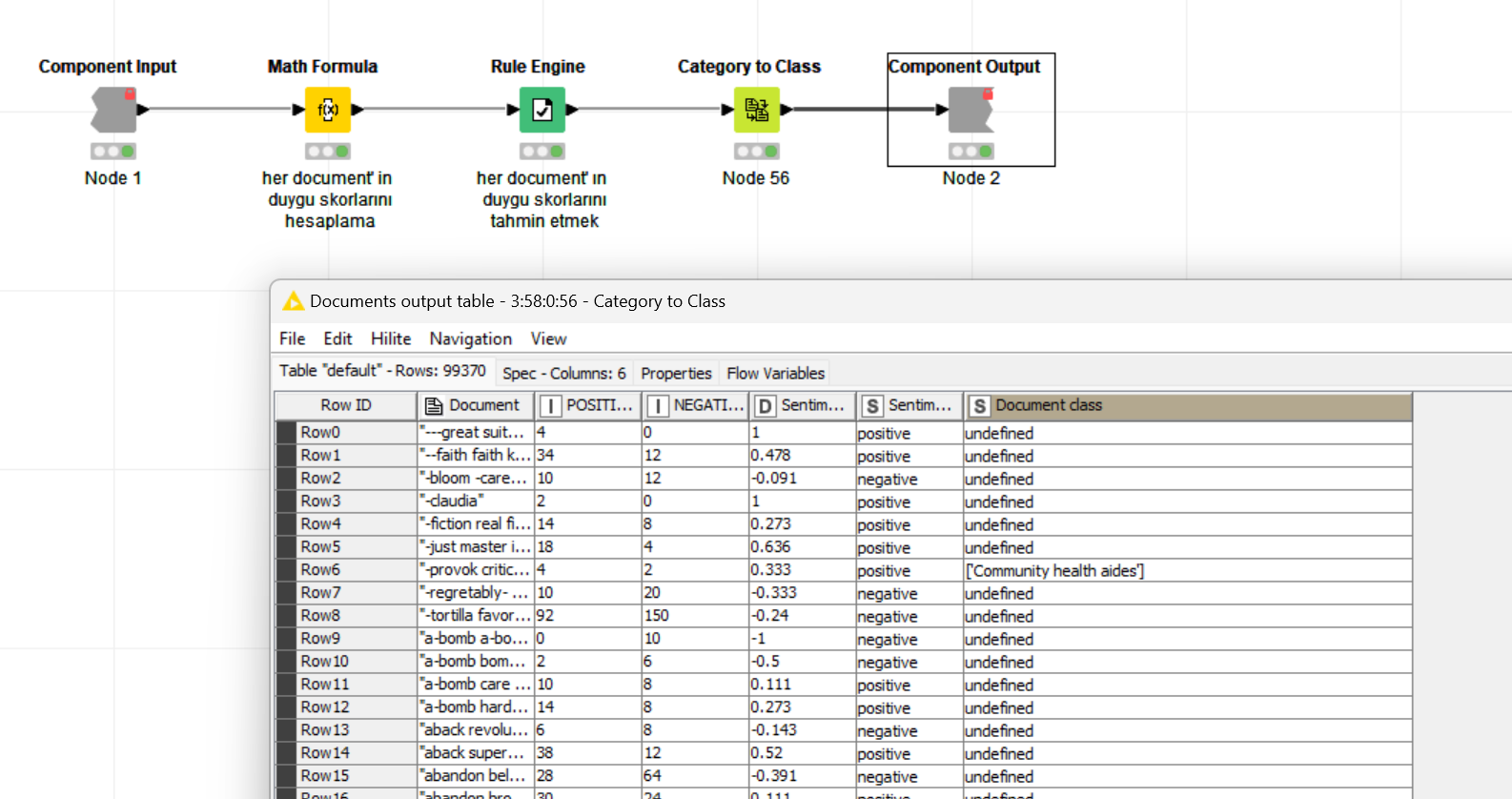
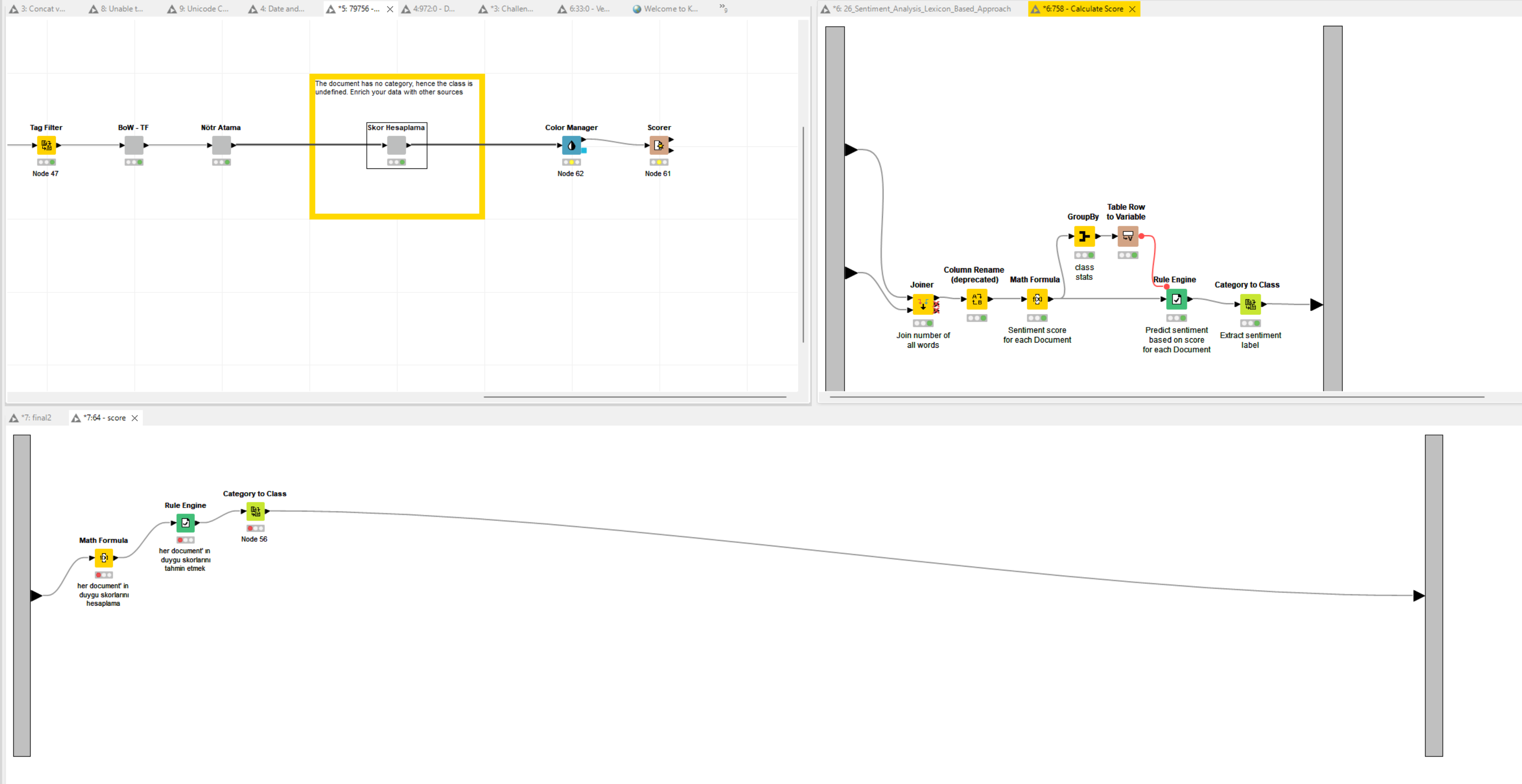
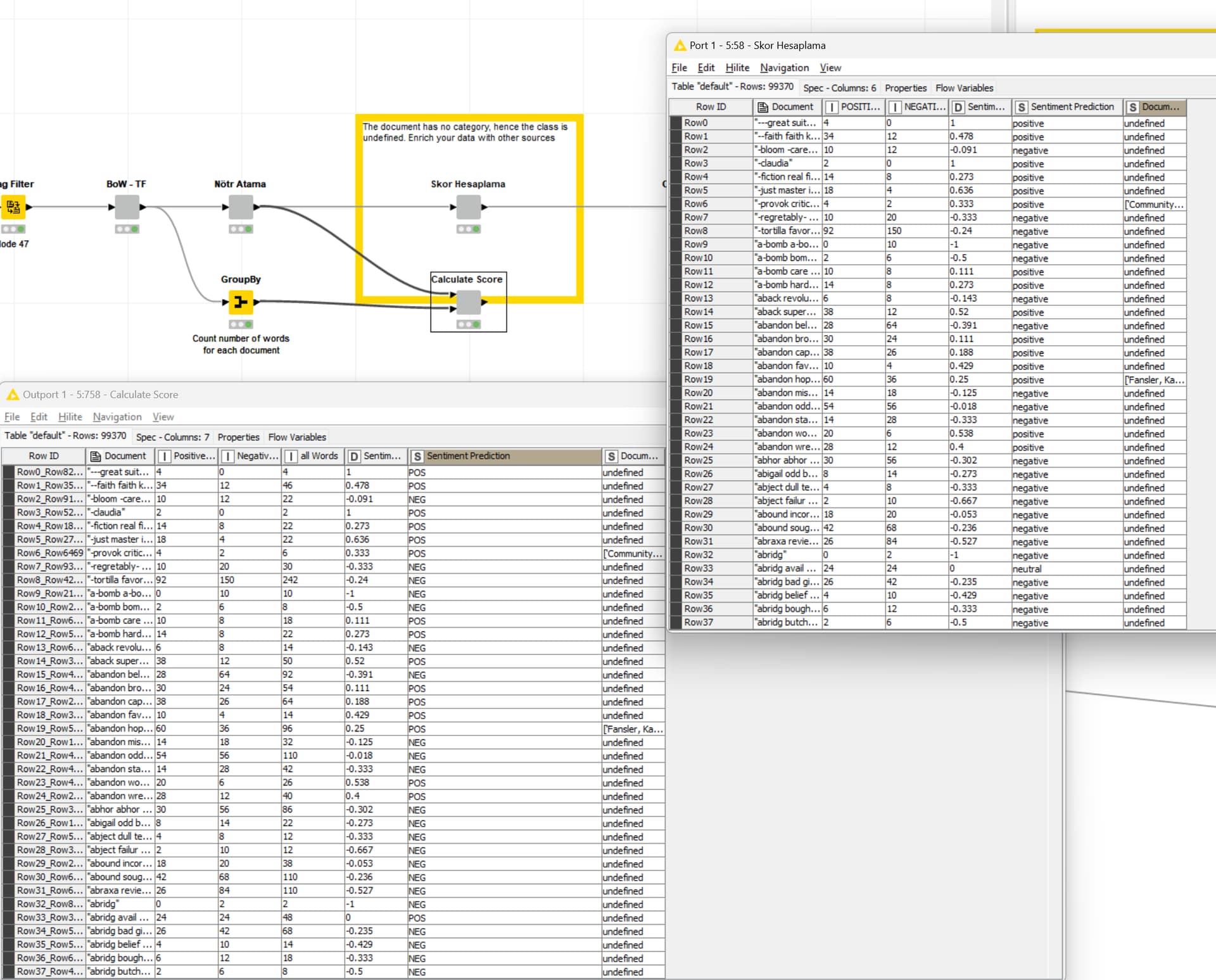
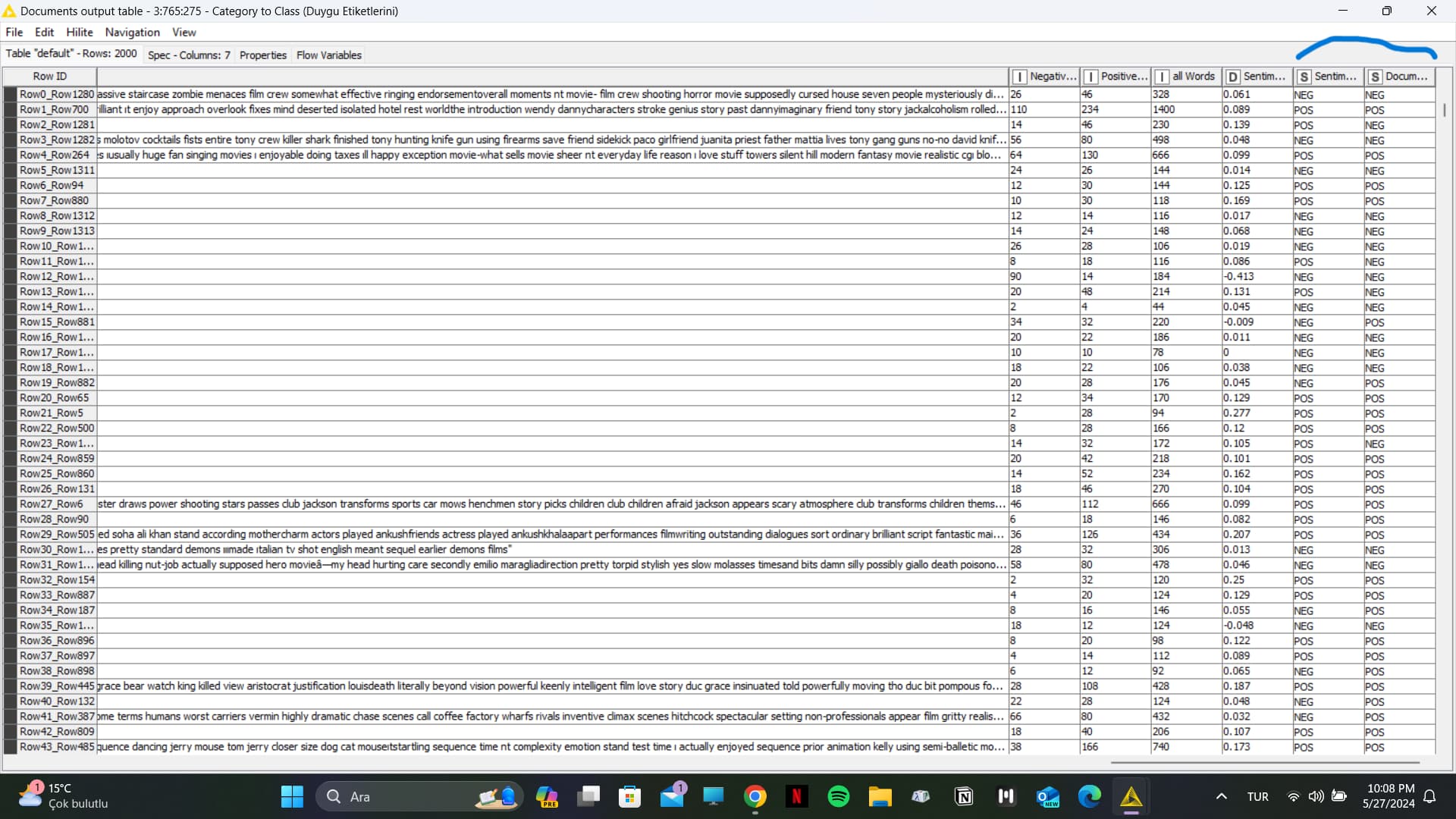
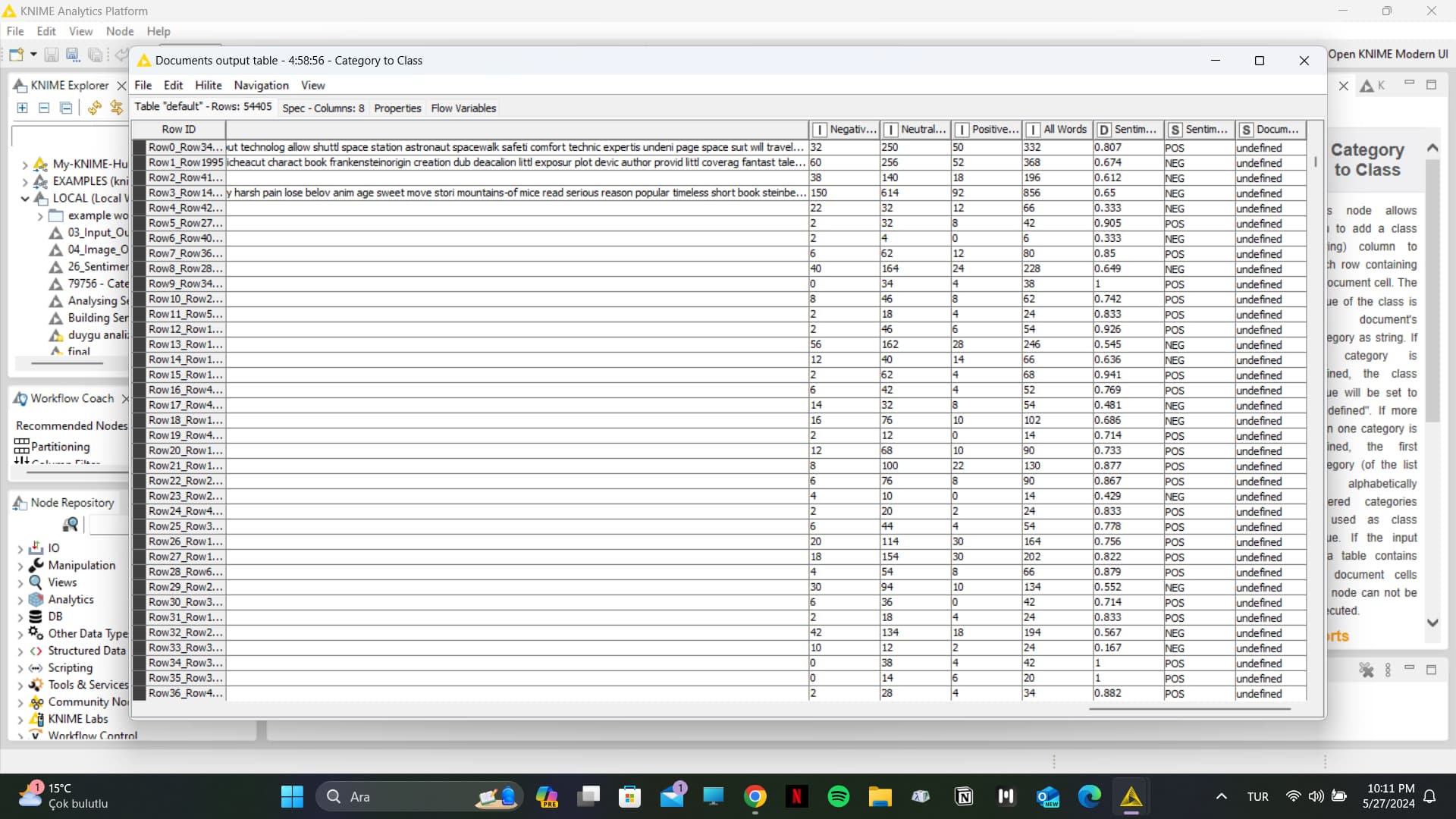
I am performing dictionary-based sentiment analysis on the KNIME analytics platform. However, when I run the Category to Class node, it returns ‘undefined’. I have been unable to solve this problem. Below, I am providing the workflow and the data I used. Can you please help me?
Thanks everyone in advance.
the explanation might be simple when you check the node description::
The value of the class is the document’s category as string.
Since you converted a string to a document, it has no category, hence the class is empty. The data lacks that information so you might want to enrich it with other sources.
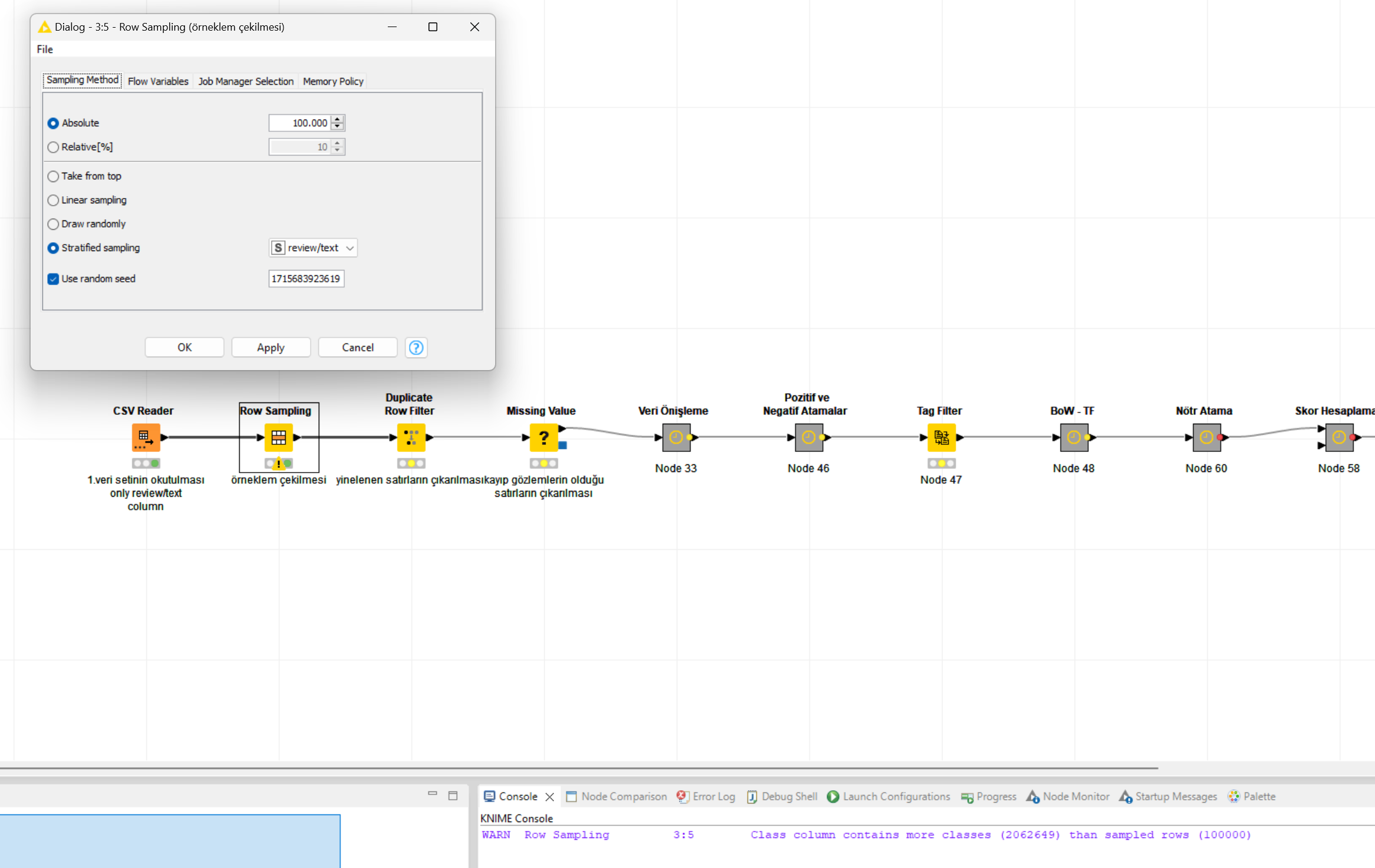
On another note, some easily overlooked default node settings can cause inaccuracy in your analysis i.e. if you pay attention to the console you will see:
WARN Row Sampling 3:5 Class column contains more classes (2062649) than sampled rows (100000)
Here are a few tips you can use to optimize your workflow to improve compute power and efficiency by:
CSV Reader: You filter for one column after reading the huge file. You can configure the CSV Reader to only read that column.
Dimensional Reduction: Prior to sampling remove duplicates and empty row. If you have only one column it is also much faster using a GroupBy to get the unique values than using a Duplicate Row Filer
In regards to #2 you can use the GroupBy, when getting a set without missing values, to both get unique values and remove missing in one go improving performance by 300 to 400 %
Memory usage: Since you convert 3 million long strings to a document, lots of cells and tables are caches. I have a system with 64 GB low latency memory, a beefy CPU and fast SSD. Yet, it started to sweat which is unusual. You might want to consider using the Don’t save Nodes to discard interims data
With the performance optimizations in place, the saving operation was speed up substantially from about a few minutes to mere seconds. Here is the improved workflow. You might want to search for sources about the document author and it’s category to enrich your data and accomplish your goal.
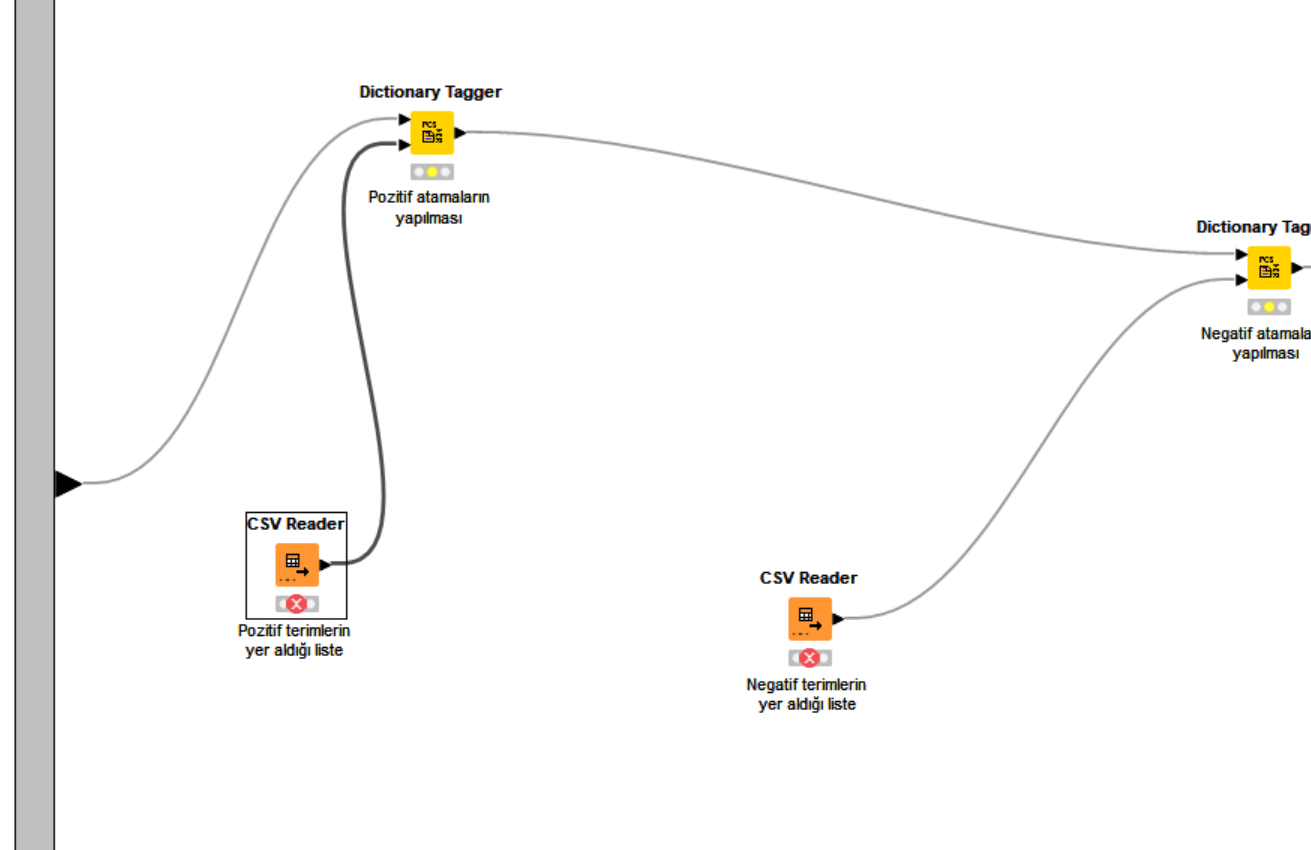
I forgot to add the positive and negative dictionaries. Your provided information is very valuable, and I will take them into consideration. Now, I will place the missing files below. Could you please review them again? Because I still haven’t been able to solve the problem. Thank you for attention!!
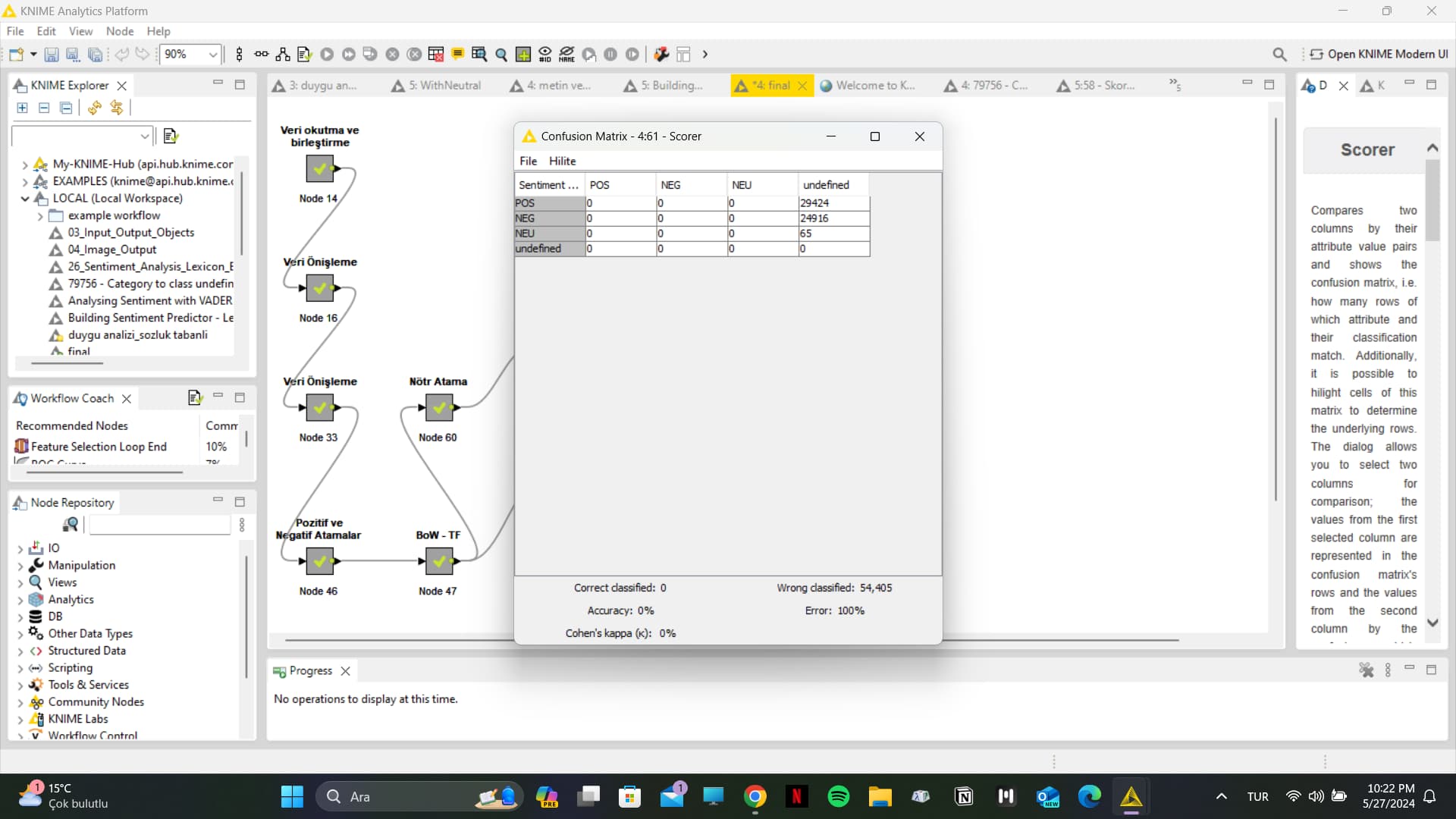
Actually, when I run the Category to Class node, I want it to give me the values ‘positive’, ‘negative’, and ‘neutral’. Because after this node, I need to run the Score node to obtain a confusion matrix. So unfortunately, I cannot use the last suggestion you provided.
After making the last few corrections, I’ll upload the workflow again: final2.knwf (59.6 KB)
Without offense but you might imagine it is bit challenging when support is given but nothing, not even the ordering, is taken over. I am also just doing guesswork without any English comments or a screenshot that guides me to the point in your workflow where your try to execute the sentiment analsis.
PS: I just copied the Metanode “Calculate Score” over, executed it and compared it to the one you had present. The results are pretty much identical and both contain a sentiment analysis column.
#4
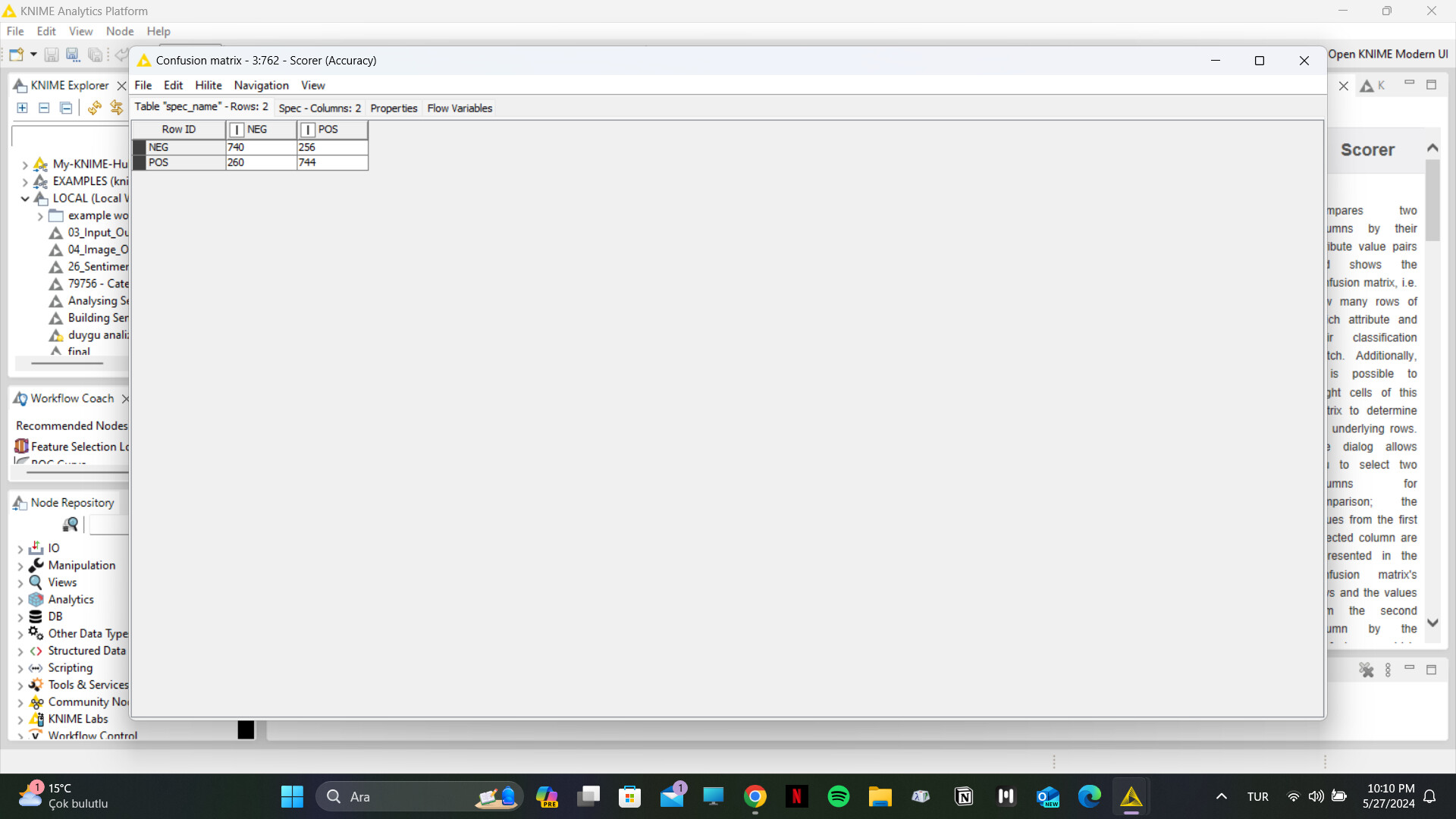
The image below is the confusion matrix I obtained as a result of the Scorer node from my workflow. However, since the values in the Category to Class node came as ‘undefined’, I did not get a correct output:
Thanks for sharing. I ma currently trying to finish my workflow for the current Knime Data Challenge but also try to enjoy vacation with my family. I will momentarily pause my work on this solution, resuming later this or next week and hope for your understanding. Though, chances are someone else is picking this up too