I am struggling with combination of rule engine and math formula.
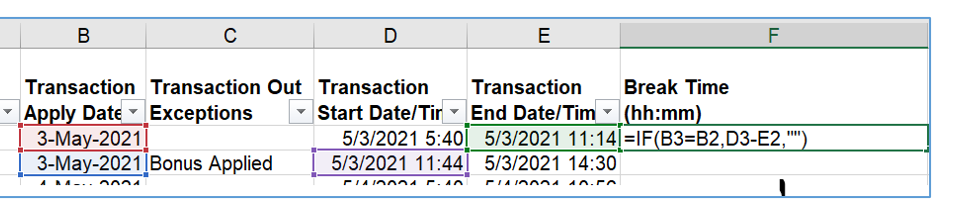
In this case I have to check date with the next row, if they are equal I have to take difference between lets say row3 Column D - row 2 Column E (with previous row)
I have kinda done it using rule engine and lag, but seems like it is not proper solution. I can use snippers, but unfortunately I do not know programming language yet
Lag node followed by Rule Engine seems like a way to go in this case. One things that could help you is a negative lag to get next date(s) one row up. See here:
Yes I agree with @ipazin , @Karlygash, I’m not averse to using the odd java snippet, but really I only use them if:
It would (really) simplify a flow, avoiding a large number of KNIME nodes
I cannot think of a totally non-scripting/programming way to achieve the desired result, using the other nodes.
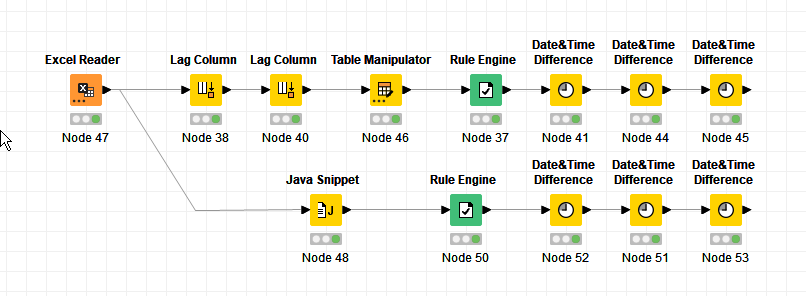
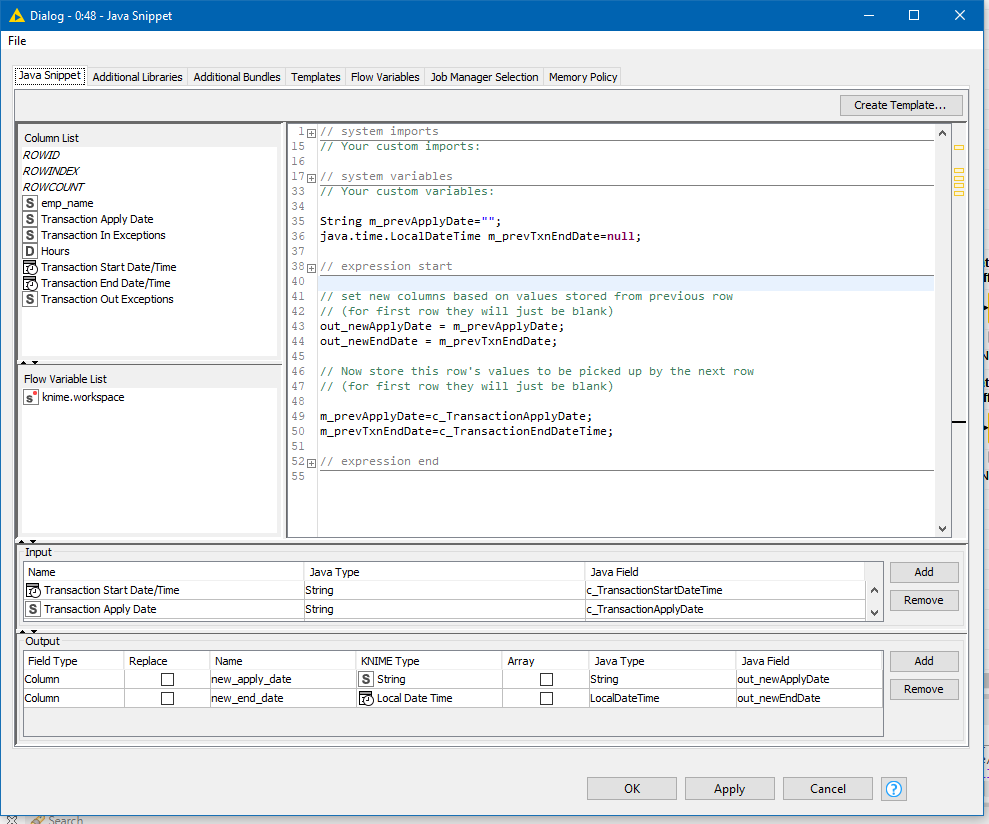
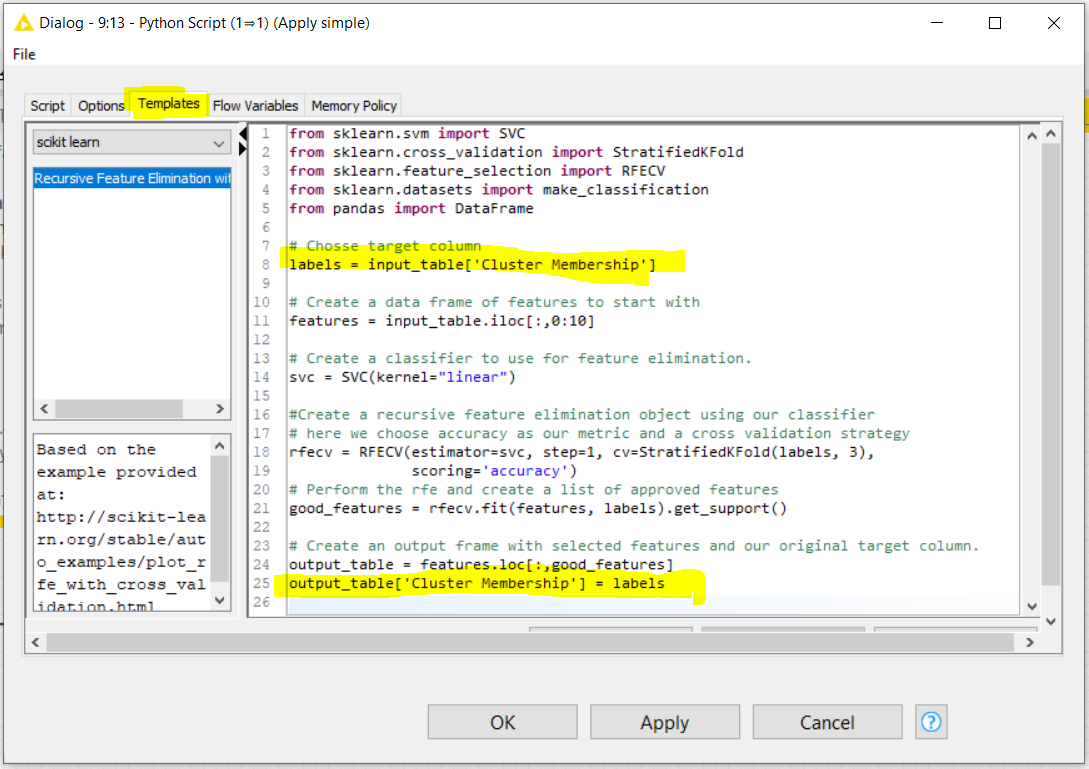
Yes you could use a java snippet in place of the lag columns here, and I’m always happy for people to learn some java or python, or both, so it might look something like this:
and if you really felt like it, could (probably) go the whole hog and replace all the nodes with the one snippet , but I wouldn’t do that… and the reason is that the use of standard nodes such as Lag columns have a clear and defined purpose and have been previously tested so you can be confident that they will do the job asked of them. It is much easier and safer to put in a couple of Lag Column nodes than it is to hand craft a small piece of java each time. If you share workflows, you are also reliant on other people understanding the purpose of your code!
A java snippet on the other hand is very powerful, but every line of new code written increases the chance of errors creeping in. I wouldn’t want them to not be available though as they allow us to extend functionality without leaving KNIME if we really need to. But the emphasis I think should always be on “really need to”.
I just realized that @takbb was posting at the same time an alternative solution. You now have the choice but please validates the one by @takbb, He deserves it ! Excellent solution and well documented answer, kudos !
Hi @aworker , thanks but no, on this occasion I was writing one of my “life , universe and everything” essays, so wasn’t really providing a solution, so this one is all yours!
@takbb@ipazin@aworker thank you for you help and I really appreciate your effort
I would love to use java snippers , but my skills are not enough yet(( @takbb your solution is really great, just one node and proper, cool solution!! I agree with that when you are sharing your workflow other users might not understand it. Specially when your customer asks to load input files by themselves. @aworker as usually you always give the best solution using KNIME nodes. Actually I haven’t used Rule Based Row Splitter yet(. It is good chance to practice using this node
Thanks for your compliments and glad you find these two solutions useful !
I totally agree with the pros and cons of KNIME coding versus classic coding. Having said that, it’s really amazing how sometimes, a single line of classic programming (Java, Python or RegEx) can replace a good dozen of KNIME nodes lol ! @takbb (with Java or Python) and @armingrudd (with RegEx) give us very often the opportunity to learn more, and thus save us from racking our brains the whole day haha ha ! Kudos again to them !
There is no much difference between the Java/Python/JavaScript used in the KNIME snippets compared to the one used in other environments, so classic tutorials on Java/Python/etc. from the web would be useful to start with. The only thing different you need to know is how to gather the data and how to return the results.
Most often I learn this by looking at simple examples in the KNIME forum or in the hub. One thing I really love about the KNIME web site is that is full of examples associated to every node. For instance, if you need to know how to program in Python with the Python Script node, good places to look at are the following:
Thanks for your links that you provided, I started with Java, but it was a bit tough for me(( Then I moved to python) Hope that in future I can write some extra functions as you using snipper)
Thanks a lot for your help
@aworker, hello=)
I am using your solution right now, I have one question related to moving aggregation.
Is it possible to move the row within the group?
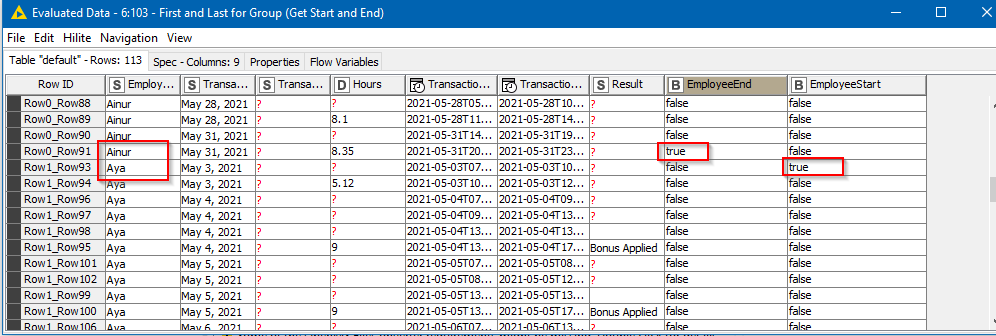
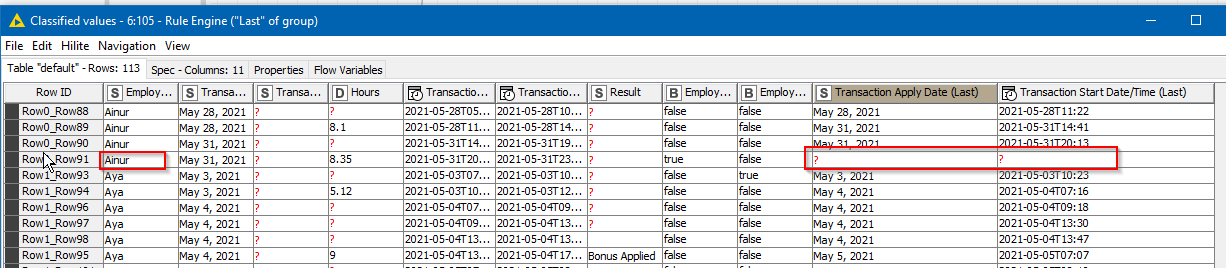
For example here in this case I have only one employee, if I add other employees, it moves down appropriately but it is taking incorrectly
I guess what you mean is that this should be done separately (independently) based on employee, so the rows for one employee should not be taken into account for the next or the previous employee ? Is that the right interpretation ?
I have just downloaded the last version of the workflow by @Karlygash and while using the last download version of KNIME (4.3.3), I’m facing this problem:
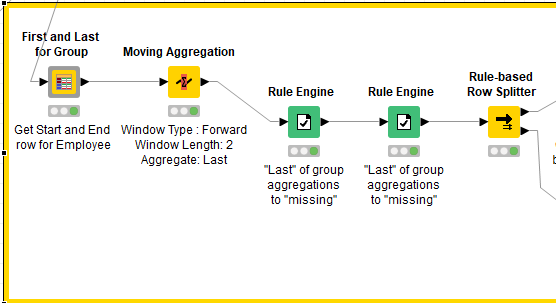
and I do not know why. I guess this is working on your side. If so, would you mind to take over from here and reply to @Karlygash question ? I believe a solution may be a “group loop” node by employee so the processing is done only based on separate employees. But may be you have a better solution in mind !
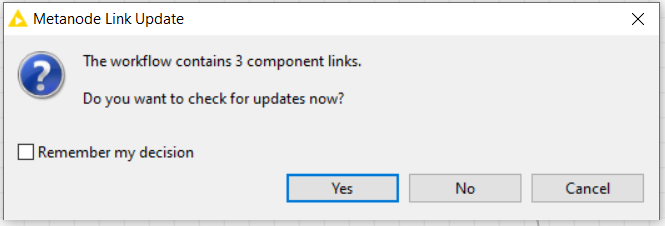
@aworker , oh yes, here are some updates. @takbb implemented new cool components, I installed them and that s why it s asking about updates
Component name is First and Last for Group
I do not know how to share with comments:D
yes the workflow contains three copies of a component but clicking Yes to update (or No ) should allow it to work. However, what I’ve done now is “disconnected” the component from its reference on the hub so hopefully it won’t ask for updates any more.
Apologies for delay, but I had to catch up on the previous messages as I hadn’t been following the “moving aggregation” part of the flow, as I knew that bit was already in (more) capable hands.
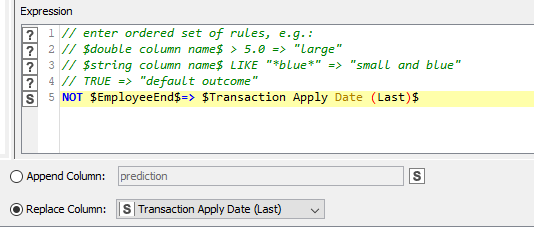
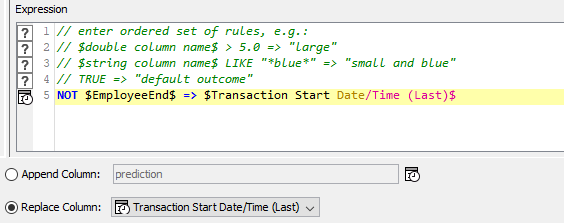
However, I think I understad, that basically each time the employee name changes, we need to have the “last” values from the moving aggregation set to missing just as it is for the final row in the dataset.
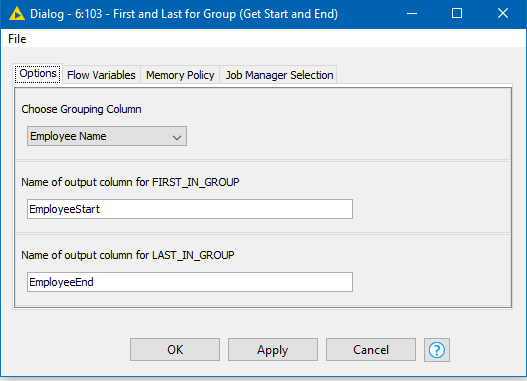
Assuming I got that bit right, then that “First and Last for Group” component can come to the “rescue”. If we ask it to mark the first and last row for “Employee Name”
then what it does is populate two columns “EmployeeStart” and “EmployeeEnd”.




 , but I wouldn’t do that… and the reason is that the use of standard nodes such as Lag columns have a clear and defined purpose and have been previously tested so you can be confident that they will do the job asked of them. It is much easier and safer to put in a couple of Lag Column nodes than it is to hand craft a small piece of java each time. If you share workflows, you are also reliant on other people understanding the purpose of your code!
, but I wouldn’t do that… and the reason is that the use of standard nodes such as Lag columns have a clear and defined purpose and have been previously tested so you can be confident that they will do the job asked of them. It is much easier and safer to put in a couple of Lag Column nodes than it is to hand craft a small piece of java each time. If you share workflows, you are also reliant on other people understanding the purpose of your code!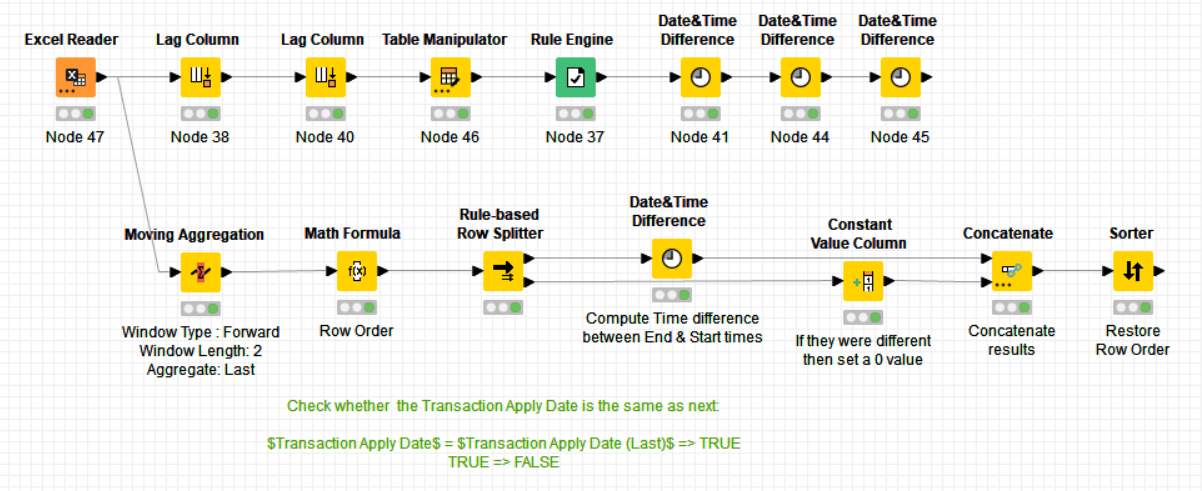
 ! Excellent solution and well documented answer, kudos !
! Excellent solution and well documented answer, kudos ! ! So funny
! So funny  !
! and glad you find these two solutions useful
and glad you find these two solutions useful  !
! ! Kudos again to them !
! Kudos again to them !


 !
!
 )
)
 !
!