Thanks for your answer, @ipazin
in the other thread they recommended the node “String Similarity” unfortunately it did not work because that makes a comparison between 2 cells of the same row of the same document.
What I need is for me to find a similar cell in the entire column of the other document.
It depends a little bit on the size of your dataset, but maybe you can first use the Cross Joiner node to create all possible combinations and then do a similarity search.
gr. Hans
Suggestions by @ipazin and @HansS are perfectly fine and sensible to compare in general strings with insertions, deletions and substitutions. However, I notice that your examples also have permutation and this may be the issue. For instance, you would like these two sentences to be considered as the most similar among the others:
TRR6/7 Waterheater
654864273_ Waterheater TRR6/7 - Sparepart
when compared each other, given that they share 2/4 words, regardless of the word order. As showed in the example, “Waterheater” and “Sparepart” are permuted. In this case, the -String Similarity- node or b.t.w. the -Similarity Search- node will perform not as well with for instance a Levenshtein metric.
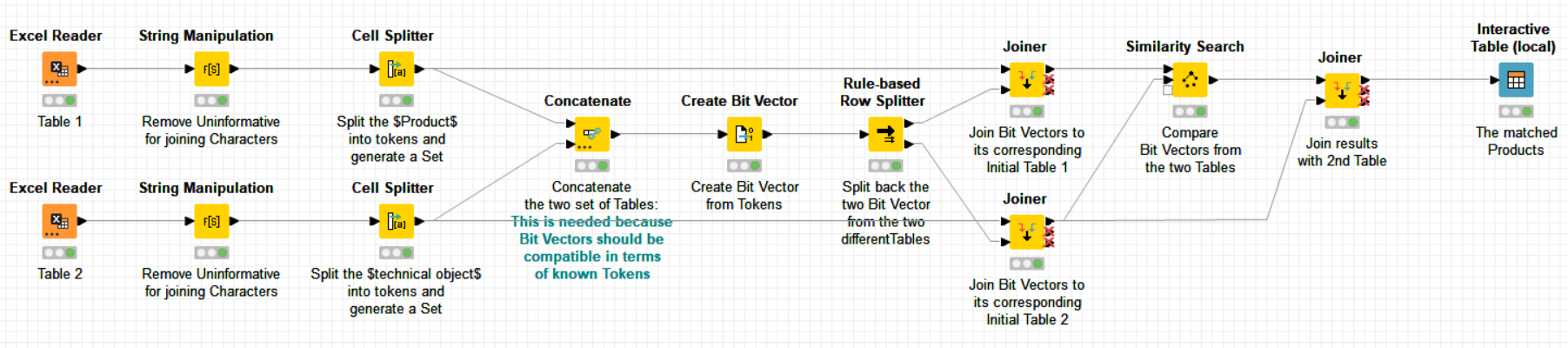
The solution to deal with permutation in string similarity, is to tokenize your sentences, i.e. to convert them into a number of binary type (or frequence type) columns where every column tells whether a “token” (i.e. a word) is present or not in a sentence. In this case, the important thing is the presence or absence of same words, not the order. The similarity comparison between string is thus done in terms of proportion of same words present in two different sentences.
The set of binary columns can be in this case converted for simplicity into a single column of type bit vector to become a fingerprint. If all the words (despite permutation) are present in two sentences, similarity between fingerprints is then maximum. The metric to use here is for instance Tanimoto (for binary fingerprints) or cosinus distance for frequency fingerprints. KNIME has all the needed nodes to achieve this type of string comparisons.
I would hence tokenize the sentences to convert them into binary fingerprints and then use the -Similarity Search- node but this time with a Tanimoto metric.
Hope this helps. If this sounds too complicated to put in place but interesting to you, please share a dozen of rows or more of your data with couples of strings which should be considered as similar and I’ll provide from there a workflow implementing this suggestion.
@aworker you described my problem very well. Permutations is a complicated part of the issue. I have prepared 2 Excels with about 20 rows. The original document have more than 8k rows.
Extra information:
The column “Product” of the “Insurance” document at best contains the information found in the columns “Functional location” and “Technical Object” of the “Maintenance” document.
The workflow is self-commented but please do not hesitate to come back if you have questions.
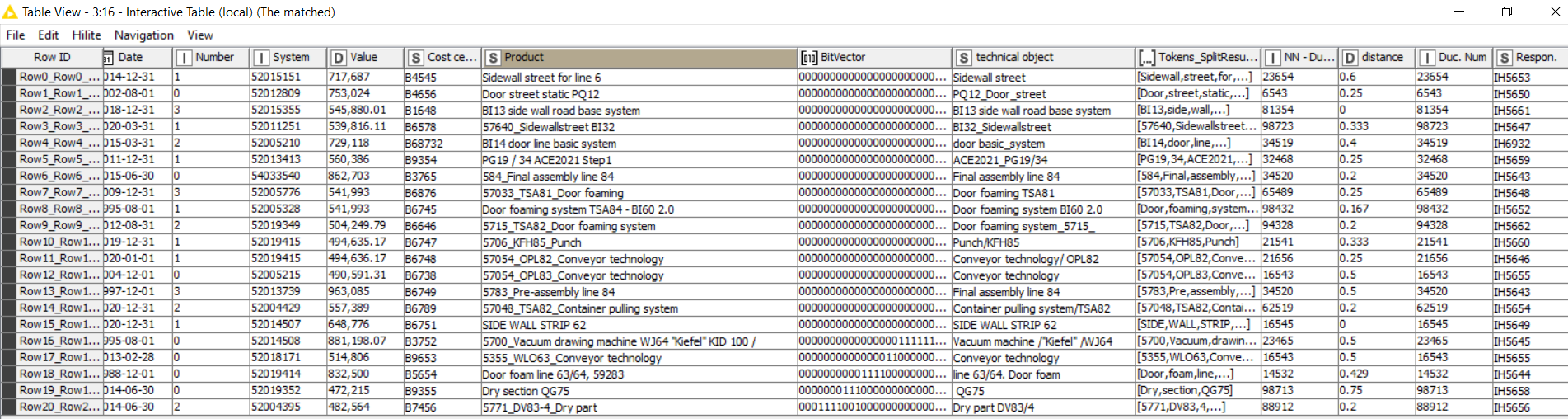
Please be aware that even if here the comparison was 100% successful, any sentence comparison with such complicated variations may not be always successful. Nevertheless, I believe this solution solves a big percentage of the automatic matching problem.
Did you have the opportunity to try and test the workflow on your 8k rows ? If so, how well did it perform ? I’ll be grateful to have your feedback @D_Valle
Hi @aworker !
Thank you very much for your answer!
Now I am testing it with the real files and checking the accuracy of the results.
At the moment it seems to be a very good solution!
Thanks again!
Thanks for your feedback and really glad to read that this is working so well !
There is room for improvement though and for new features beyond this preliminary solution, if needed.
Please let me know how things go and get back in touch if you have any further questions.
I have a similar problem and would really appreciate if you could give me a hand. The issue is following:
I am using 2 excel files - Basketball_players and Baskeball_dataset.
The idea is to compare the records from the column “Title” (Basketball_dataset) and column “Player” (Basketball_players) in order to find similarities within.
When found - rename the record from basketball_dataset to match the name of the most similar record from basketball_players (maybe use rule engine or smth)
Please see example bellow:
e.g. 2020-21 PANINI ILLUSIONS RICKY RUBIO #18 TIMBERWOLVES will probabbly be the most similar to Ricky Rubio record. Final result should be Ricky Rubio.
same goes for 2014-15 RICKY RUBIO PANINI ELITE BASE CARD! → Ricky Rubio.
Hi @DivineBlink and welcome to the KNIME forum community
Have you tried to adapt to your data the workflow I posted in this thread ? You have this same workflow as a solution in this other solved thread too:
Both workflow versions show how you could adapt it to your data and needs. Please have a try to it and let us know if you have any questions. I will be happy to further help from there if needed.


 !
!