I have been getting instances where if the second table has missing values on a concat node, then it will fill those missing values with the first or third table. Concat Issue.xlsx (8.8 KB)
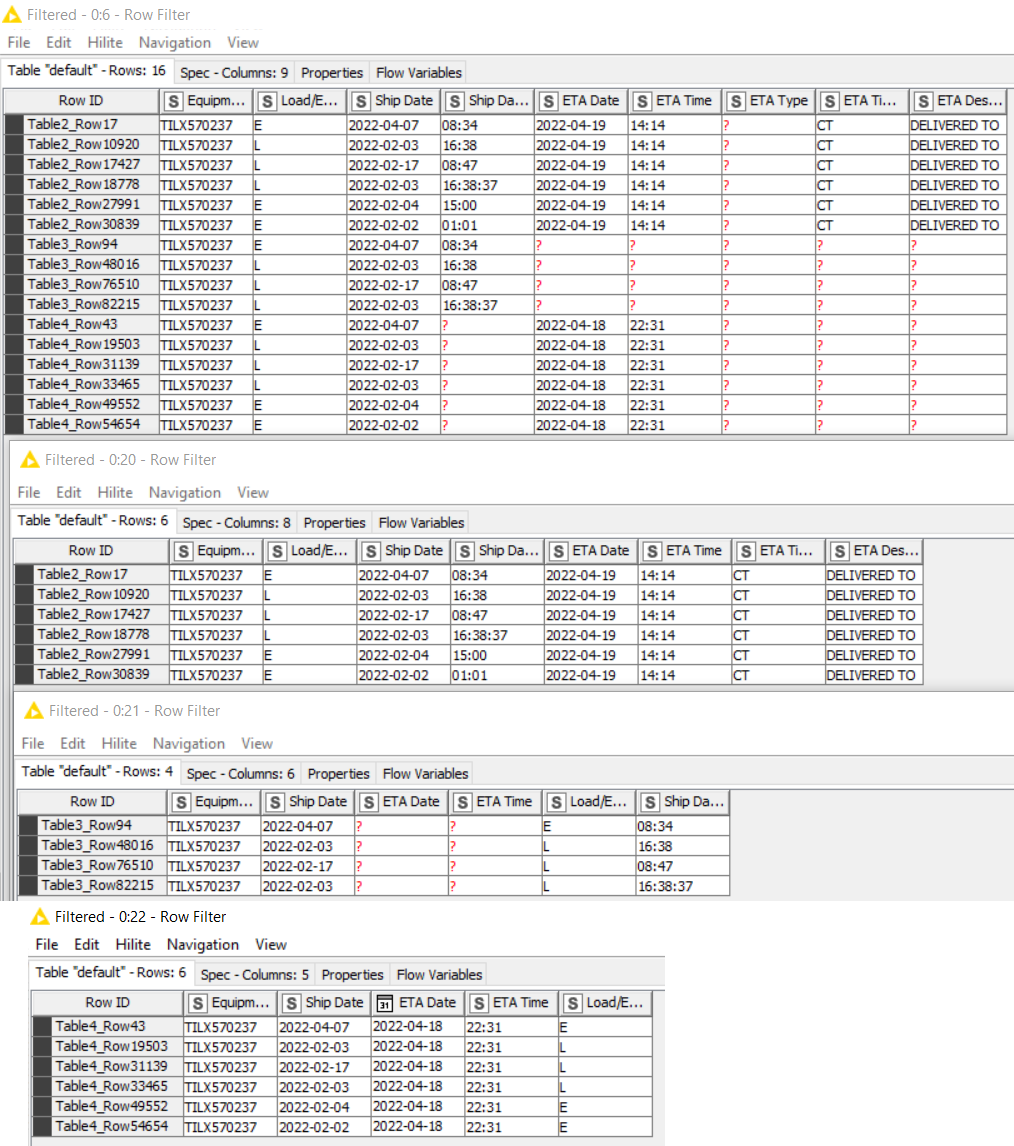
The first row what shows after the concat, and the second row is the same rail car number that shows an ETA.
Is there a better way to union in Knime or should I fill all missing values with something so this doesn’t happen?
Can you share a workflow that reproduces this behaviour? We can then see how your input data looks like, what the results are, and what you’d expect. This post might help you:
You will see that some of the cars that had proper ETA’s in the excel reader nodes now have different ETAs tied to them after the concatenate. I only spot checked three and the third one had a different ETA
Example is car # TILX570237 from excel reader node 4 has an ETA of 2022-04-18 on the reader node, but after the concatenate its listed as 2022-4-19
I’m sorry, but I’m still not able to see what’s wrong. Can you also share the xlsx files, or at least not reset the workflow when exporting? Thank you.
Hello Thyme, I have attached the worksheets. To reproduce I would suggest pulling 4 random car numbers from each file and then concat each of those file together. After the concat see if those ETA’s of the cars you selected have changed (as they shouldn’t)
Top is concatenated table, below that are the 3 input tables. No values have been changed.
Can you please share a complete, minimal, reproducible Workflow?
complete: the Workflow is self-contained, everything necessary is in that workflow. You can use the data area to transport files (it’s a folder in the workflow directory, named “data”)
minimal: no need to upload 45.000 equipment numbers, a few of them are enough
reproducible: the workflow shows the mentioned behaviour
I think the issue might be related to how many are being concatenated though, how would you prefer I send you the reproduceable workflow if I want to include all data?
I already had to minimize the excel documents to transfer over because they were pretty big.
I really apologize for being late on this response. I have not been able to get back to the data set that was impacted as of yet. Would you like for me to close this for now till I get back to it?
I think it’s better to keep it open, the topic will automatically close 3 months after the last reply. That way the topic won’t be scattered over multiple threads if someone has new info to add.