Estoy empezando con knime y tengo algunos conocimientos pero estoy intentando sacar unos valores pero no soy capaz. A modo de ejemplo lo que estoy intentando conseguir es si por ejemplo hay una tabla que contiene como valores 2,3,4,5,3,2,1,5,6,3,8,9,9,10,11,13,14…
Me gustaria que se me devolviera un resultado que contara los valores que son superiores a 9 que en este caso seria 10,11,13,14 y se me tendría que devolver un valor 4.
Tengo algunas ideas en la cabeza pero no se ponerlo no se si debo utilizar un IF o un Value counter… agradecería que alguien me pueda echar una mano.
Primero de todo agradecerte la rápida respuesta pero no pude contestarte antes.
Gracias por el workflow.
Y pensando que teniendo un ejemplo sabría salirme.
En mi caso, yo tengo unos datos y de esos datos aplico una formula con el Math.Formula por ejemplo 5+2=7 que se crea una columna que se llamaría “nivel alto” y luego en el rule engine o value counter quiero decir que cuente los valores que son más grandes que “nivel alto”. Es decir el valor de 7 que da la suma y me los ponga en una sola columna.
Mi intención final es generar una tabla o varias tablas que al final pueda poner la suma total del numero y poner el 100% de los datos en Niveles que yo establezco…
Lo que me esta pasando es que yo pongo el math.formula y le pongo un valou.counter y me sale como respuesta un 1. A mi me gustaria poner el math.formula y despues el value.counter porque lo que creo que esta pasando es que el math.formula solo te hace el calculo y al ponerlo ya no puedes tener en consideración los valores previos al conectarle otro nodo.
Espero que me comprendas porque sé que no me explico bien.
Si no me entiendes procuro expresarme de otra forma, te lo agradezco mucho.
Hola @rsierrama
La verdad es que no queda muy claro. Veo que tienes el mismo problema abierto en el foro de inglés.
Según la respuesta que da @elsamuel en el otro post, y los comentarios …
[…] Puedo imaginar que se trata de una tabla en la que tienes en la primera columna el ID de usuarios que respondieron n. preguntas; sus valoraciones para las n. preguntas están dispuestas en n. columnas.
El resultado buscado sería: mediante una aproximación matemática / estadística sacar los rangos altos medios bajos para cada columna Q1, Q2, Q3, … Qn, como por rangos Inter-Quartiles para sacar variables discretas:
Por ejemplo: P1 [nivel bajo] / Q1 / (nivel medio] / Q3 / (nivel alto] P99
Es decir, necesitas una solución que haga un loop por columnas y recalcule la condición en cada paso de loop.
Muchas gracias de nuevo por contestarme. Te lo agradezco.
He estado mirando tu workflow y si… mas o menos lo entiendo… en mi caso lo que necesitaría como dices quizás porque ya me encuentro colapsado seria hacer un loop que recalcule la condición.
En mi ejercicio, hay valores entre 1 y 5
Nivel bajo sería inferiores a 0 a 1
Nivel medio superiores a 1 a 3
Nivel alto superior a 3 a 5
Entonces después hacer conteo como te devuelve tu workflow con el valor total de la suma. Lo que puedo hacer es cogiendo tu workflow es poner un Numeric binner y poner los valores manualmente ¿cierto?
Te adjunto el workflow a ver si ves el error que estoy cometiendo…
Exactamente mi ejercicio es que existe una gran cantidad de valores, despues se divida en niveles. Para establecer los niveles hago uso de la medias y desviación estandar. Por ejemplo, si la media es 3 y la desviación estándar es 0.7 si un valor se encuentra en 3.8 al ser superior a 3.7 es un nivel alto. Por el contrario si la media es 3 y la desviación estandar es 0.7 restandole esos dos valores da 2.3 y si un valor se encuentra por debajo es nivel bajo…
No se si me explico… pero espero que sí…entonces yo hacia uso del math.formula para hacer esos cálculos y quería que la columna resultado estableciera los limites pero no me funciona… sea lo que sea… si consigo hacer tirar el numeric binner en el ejemplo que me pasaste es suficiente porque pondre los valores yo manualmente… Con tiempo intentaré mejorar esa parte pero me gustaría acabar esto pronto.
Muchisimas gracias de nuevo, se ve que tienes mucho nivel.
Creo entender que los rangos se delimitan por la media mean +/- la desviación estándar, como das a entender:
mi ejercicio es que existe una gran cantidad de valores, despues se divida en niveles. Para establecer los niveles hago uso de la medias y desviación estandar.
He intentado configurar el Numeric Binner controlado por variables pero es complicado, al final he optado por el Rule Engine que es más directo.
Las métricas estadísticas las puedes tomar directamente de tu data con el nodo ‘Statistics’ , el nodo ‘Statistics’ dentro del Loop te extraería las métricas sin tener que usar ‘Math Formula’. Las métricas dentro del Loop, las envías a un puerto de variables y están listas para operar con ellas y calcular los bounds de los bins.
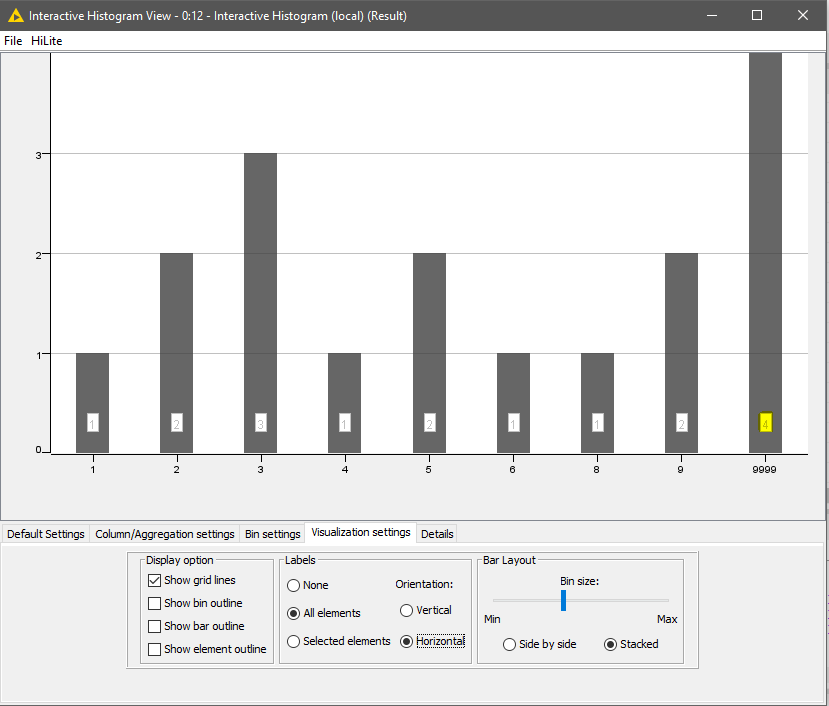
He utilizado tu workflow y he puesto un números fijos y me ha funcionado perfectamente generando lo que aparece en esta foto:
Que es lo que quería…
No obstante luego he intentado hacerlo con una variable como esta en tu workflow y en el rule engine puse lo siguiente:
$Performace$ < $${DDOWNSD15}$$ => “Nivel muy Bajo”
$Performace$ < $${DDOWNSD}$$ AND $Performace$ <= $${DUPSD}$$ => “Nivel medio”
$Performace$ < $${DUPSD}$$ => “Nivel alto”
$Performace$ <= $${DUP15SD}$$ => “Nivel muy Alto”
y el resultado es que me aparecen todos en nivel muy alto… he probado diferentes combinaciones y todo el rato lo mismo.
La variable que pone downsd15 me gustaria que fuese la media - 1.5 de una desviación estandar y up15sd lo mismo pero sumando 1.5 de desviación estandar…
entonces puse el siguiente return que creo que lo estoy haciendo bien…
No encuentro el problema… a ver si me puedes echar una mano…
PD: Voy a crear el mismo recorrido de workflow para cada una de las variables que quiero evaluar (aquello que en el ejemplo es Q1,Q2,Q3,etc…). Entiendo que para que lo haga automaticamente y coja todas las variables habría que hacer un loop dentro de otro loop ¿no? yo estudie programación hace muchos años y me vino eso a la cabeza pero eso ya me supera a día de hoy.
Una vez más espero haberme explicado bien… de no ser así pruebo de explicarme de otra forma
Hola @rsierrama
Creo que para el reto que tienes entre manos, tienes todos los fundamentos necesarios en el último workflow … intentaré contestarte por pasos:
He utilizado tu workflow y he puesto un números fijos y me ha funcionado perfectamente generando lo que aparece en esta foto:
No entiendo esta imagen, primero me dices que los rates son de 1 a 5 y generas 5 divisiones categóricas (?), si aplicas estadísticas para asignar el sesgo de la distribución, es lógico que que si las respuestas tienen sesgo se te quede alguna de las categorías sin counting. Te va a pasar con cualquier método que utilices si tratas de sacar 5 clases.
La variable que pone downsd15 me gustaria que fuese la media - 1.5 de una desviación estandar y up15sd lo mismo pero sumando 1.5 de desviación estandar…
Al no conocer el tipo de distribución de cada pregunta Qn (ver columna de ‘Histograms’ en el nodo output de Overall Statistics)…
sigo pensando que tu solución sigue siendo el ‘Auto Binner’ agrupado por secciones iguales [.001-.2[; [.2-.4[; [.4-.6[; [.6-.8[; [.8-.999] aunque con 5 variables discretas te seguirán dando clases vacías
Y por último, no intentes ni de lejos hacer loops anidados. KNIME no los va a relacionar; se necesitan hacer cros-joiners para single loop y muchas transformaciones de data.