In my opinion there is something wrong with the "corpus frequency " in the NGram Creator Node. I know there are already forum posts with answers to this topic (https://forum.knime.com/t/ngram-creator/11493, https://forum.knime.com/t/doubts-on-ngram-analysis/8824 ) but either I’m lost or - as I said - there is something wrong.
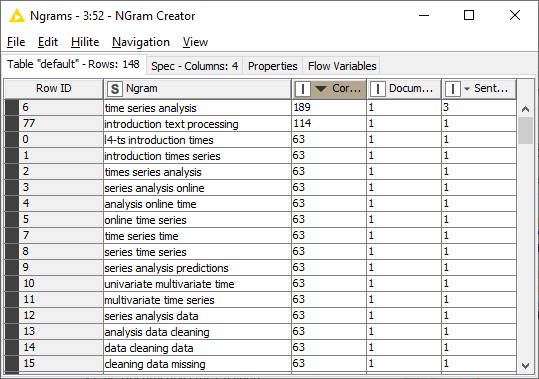
As an example: In the workflow for the self paced course “L4-TP Introduction to Text Processing” (Exercise: “Bag of Words and Frequencies”) two documents are analyzed, each one a one-page-agenda for the KNIME TS and TP courses. When I add NGram Creator Node I get a very high value for corpus frequency. How can this be?
Thanks for your support and many greetings
Christian
@Christian_Essen Hi, can you share the link to the exercise? I tried looking here knime/Education – exercises – KNIME Hub but can’t find any entitled ‘Bag of Words and Frequencies’. (Or you can also upload the workflow directly here so I can have a look.)
Thanks! I have looked at the workflow. It seems that the N-Gram Creator node treats each preprocessed document in the previous BoW node as one, meaning that it’s analyzing a corpus of 120 documents instead of just 2 of the original documents.
Because of that, you see many duplicates of N-grams (e.g. ‘time series analysis’ as shown in your screenshot has 189 occurrences rather than 3.)
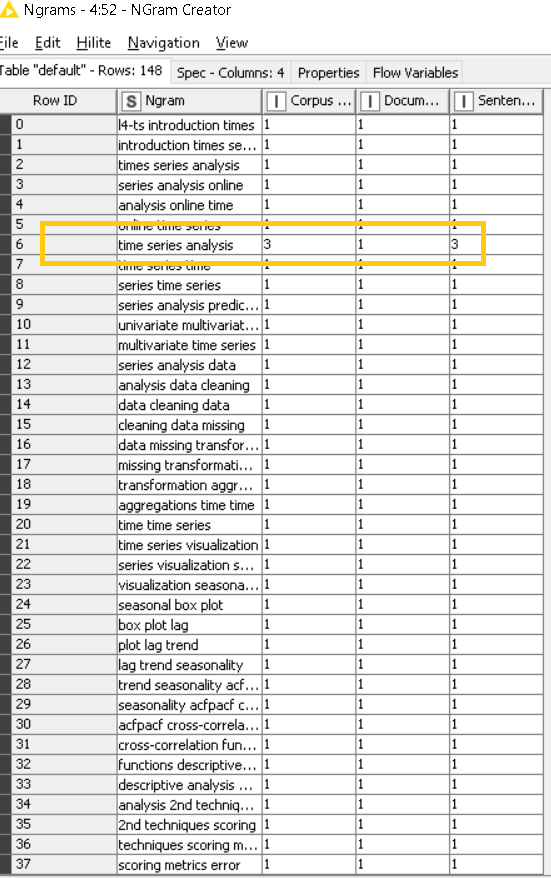
To validate what I’m saying, you can connect the NGram creator directly to the Concatenate Node without going through the BoW, and you’ll get this result:
@badger101 :That makes sense - thanks for the quick and very helpful reply!
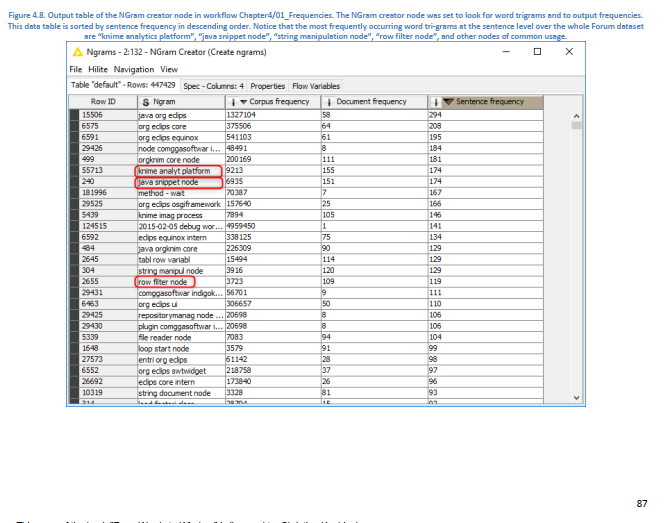
One more note: If I’m not mistaken, the problem that the NGram Creator node is behind the BoW node also exists in the KNIME book “From Words to Wisdom” on page 87 (see screenshot) and in the associated workflow located here.
The corpus frequency there is absurdly high.