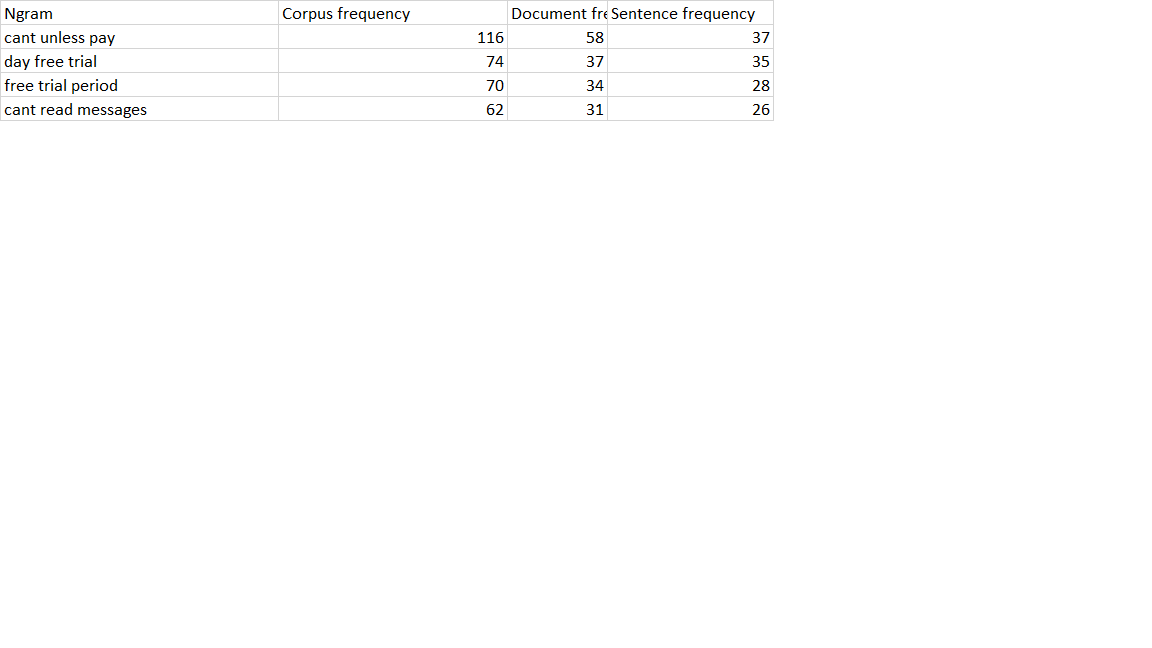Folks - a newbie to text processing and as such have a naive question.
I am using the n-gram creator to pick out ngrams and their frequencies. I am not splitting the sentences/documents into bag of words which I interpret as every record being a unique document.
I assumed that sentence frequency is the # of sentences with the n-gram, document frequency is the # of documents with sentences that have the n-gram and corpus frequency the total number of documents with sentences containing the ngram
Clearly my assumption on the definitions does not seem to be accurate
If that were true then I am trying to wrap my head around why the sentence frequency i.e. total number of sentences would be < document frequency and likewise why document frequency which is total number of documents be lower than the corpus frequency
Attached is a sample output.
Would be very grateful if someone could point me in the right direction
Thanks much MH! The node description is similar to the post from Roland. Clear enough but not able to make the leap in connecting it to my example.
The part that confuses me in my example is why the sentence frequency would be lower than the corpus frequency. Shouldn’t the occurrence of an n-gram assuming it is always part of the sentence generally be greater than document frequency?
I ask because a document could have multiple sentences with the n-gram.
Adding on to the thread to pull it to the top. Hoping for any guidance anyone can share or point me to additional literature besides the node description.
Let me try to explain using your example: The corpus frequency will always be the higher or at least equal to the other counts. That is because it is the total number of times an ngram occurs in the full corpus.
In your case, “cant unless pay” appears a total of 116 times in the whole corpus. On the document level, it appears in 58 different documents (i.e., on average twice per document). It also appears in 37 different sentences. This means that there are some sentences in which the ngram appears multiple times.