I found myself quite often challenged to pass data from a different corner of a workflow, though multiple components, just to not being required to write and read data but with the trade off to establish many connections.
This causes, when you are dealing with a large workflow to spend lots of time in:
Managing connections
Organizing nodes to prevent a “noodle-salad”
Maintaining documentation
Comprehending where which data is coming from
Hence, I’d like to propose creating a node that literally beams data by:
Writing the data which every node does
Informs the receiving end automatically that new data has arrived or about the incoming node status, setting subsequent nodes in idle status and auto execute after data arrived
It would dramatically reduce connection cluttering, improving workflow management and allow, by cutting down on managing time, to invest more time on building a workflow.
Hi @mwiegand, this is similar to the “wireless connectors” in Alteryx, which I agree does reduce clutter greatly, and it would be great to see this in KNIME. It got raised as an idea quite a while back and in response I created a “prototype” of the kind of idea you have suggested above, using some components. It’s not perfect and is only intended as a proof of concept as it is not really that practical for all data, but you may be interested in this anyway…
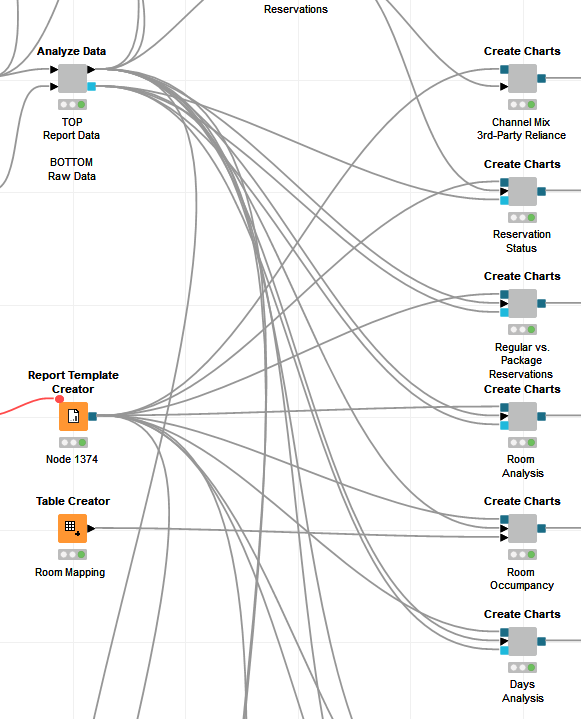
Nice, I upvoted yours to consolidate efforts. I have a similar feature but for color management. One for passing down report template creator is a prime example of port and connection cluttering:
I will add my two cents to that other original post.
@mwiegand , @takbb one of the benefits of KNIME is that you always have a line connecting the nodes. An although it can get crowded and the 5.x is lacking auto layout features I thing overall this forced workflow structure is a plus for documentation and the ability to understand the workflow.
An ‘invisible’ connection is very likely to confuse people from my perspective.
If a workflow gets crowded one will have to think about components or metanodes (they seem to make some sort of comeback) or split this into several workflows. I would be careful to break the concept of nodes and connections.
Generally I agree to having a connection present is essential for lots of reasons. However, if that connection serves no or barely any purpose in understanding the process, like passing color information, the cluttering degrades the initial purpose to such an extend that managing connections and ports easily overshadows the initial intent.
It is more an edge case and sometimes data generated in one corner of a workflow, i.e. when reading and processing an XML file “A”, who’s results must be fully or partially leveraged i.e. to filter data from XML file “B” in a total different workflow corner, decreases the amount of time one proactively works towards a solution.
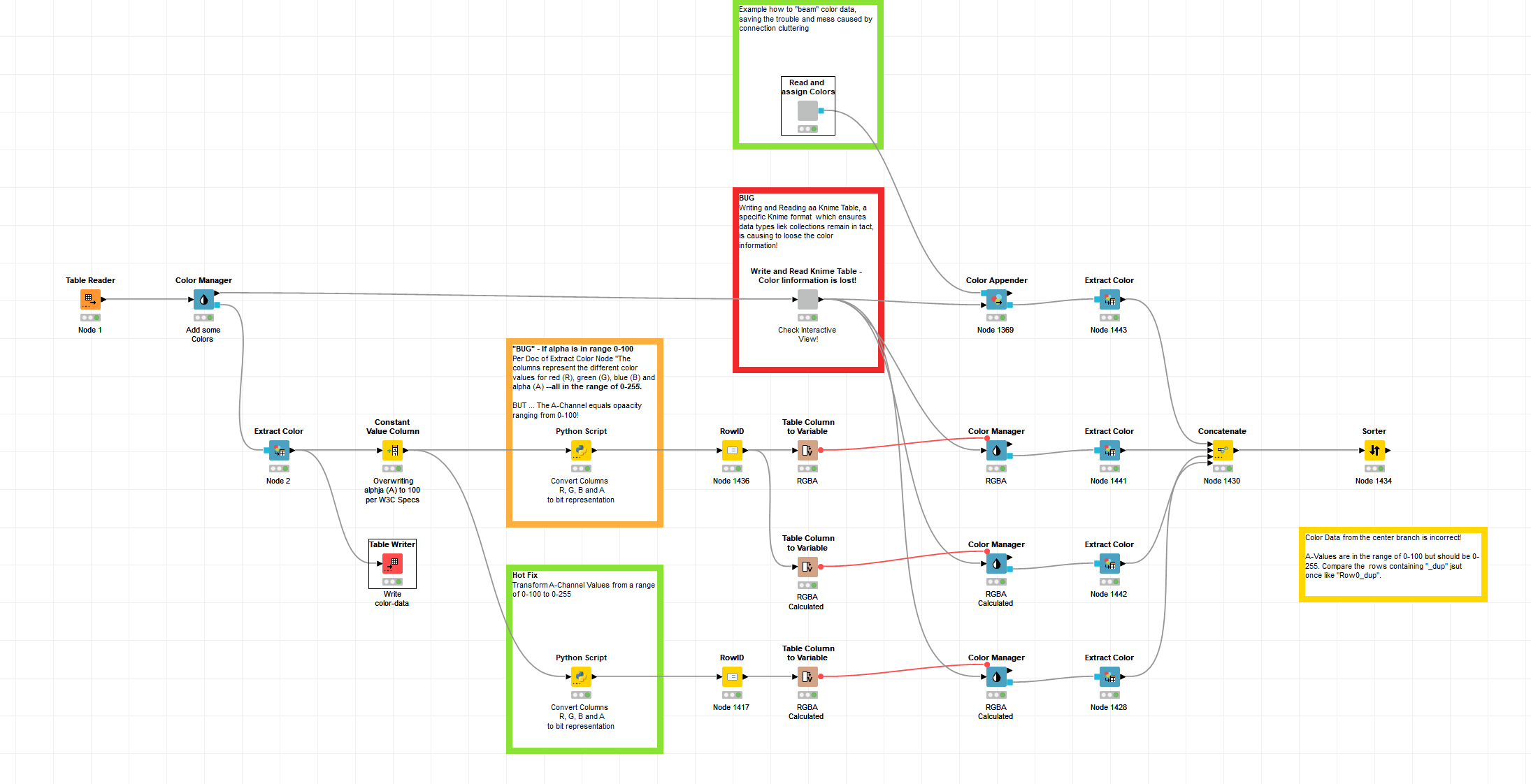
I have updated my color management example workflow to show how color data can be written and read again to spare at least the burden of passing down that data.
@mwiegand I might take a look. Concerning color management I put out this example once converting settings from a KNIME Color Manager to a Python dictionary, Pickle that and then re-use it in Python. Question would be if this could then be re-imported into KNIME.
But I see the point of some edge cases. Maybe color settings could be transferred thru a system like Flow Variables. Or they could support lists (do they?).
Nice solution as always I definitely got to remember what you did leveraging the python dictionary. The color management certainly is in desperate need of some love. Let’s see if it’s going to get some in the near future.