Hi Team,
So I’m a bit new to Knime and in the part of the workflow which I am trying to create, I have to map from File B into File A, where the rules are set in file B.
To explain with an example
below is the screenshot of file A with condition
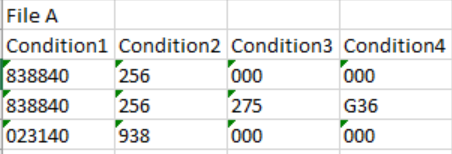
below is the screenshot of file B with mappings for the same condition
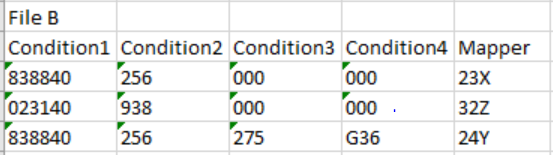
to explain further what file B denotes is
- IF [Condition1]=838840 AND [Condition2]=256 THEN 23X
- IF [Condition1]=023140 AND [Condition2]=938 THEN 32Z
- IF [Condition1]=838840 AND [Condition2]=256 AND [Condition3]=275 AND [Condition4]=G36 THEN
24Y
hence the final output of File A should be
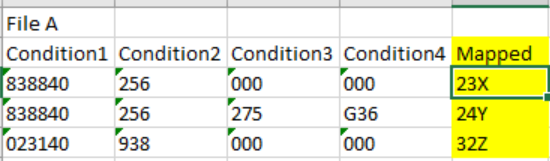
I at first scoured the internet finding for possible solution, but wasn’t able to find any hence created a topic here, any input would be very helpful
Hi @SiddeeqM,
you can simply use the Joiner node with multiple matching columns (Condition1, Condition2, Condition3, Condition4).
You can join with this solution the Mapped field form file B to file A.
Roland
Hi @rolandnemeth
Thankyou for your reply
Agreed! the joiner node should ideally solve the above stated problem but will create a new one.
Say below are the requirements in File A (row 4 is newly added).
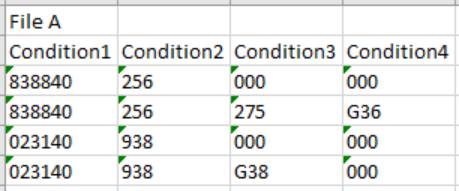
and below is File B with the mappings for the condition (same as before)
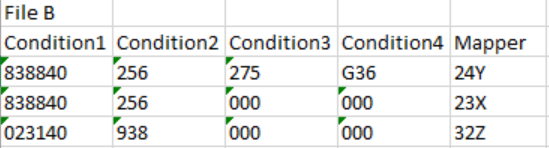
The File B denotes a conditions:-
- IF [Condition1]=838840 AND [Condition2]=256 AND [Condition3]=275 AND [Condition4]=G36 THEN 24Y
- IF [Condition1]=838840 AND [Condition2]=256 THEN 23X
- IF [Condition1]=023140 AND [Condition2]=938 THEN 32Z
And the expected output should be
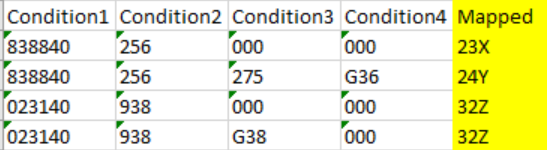
Just to summarize:- In File B rule 3 checks only for condition 1 and 2 and hence completely ignores Condition 3 and Condition 4 and returns the output as 32Z in row 4 of File A. This part will probably return a mismatch by Joiner node
I was meanwhile searching the internet for possible solution. Can Rule Engine(Dictionary) be of help?
Your help is very much appreciated
Siddeeq
Hi @SiddeeqM & welcome to the KNIME community
Just a question before suggesting a solution.
Is any of the conditions never equal to “000”, for instance “condition 1” ?
Best
Ael
Hello Ael
Thankyou for the welcome!
It goes like this.
-
If condition 1 and condition 2 is zero then condition 3 and condition 4 will never be zero
-
And it’s vice versa if condition 3 and condition 4 is zero then condition 1 and condition 2 will never be zero
Regards
Siddeeq
Can you join all condition together in 1 cell for both files,replace the 000 with nothing (string manipulation node) and then use a cell replacer for the lookup?
br
1 Like
Hi @SiddeeqM
You are more than welcome. Thanks for the clarification. It makes it harder than I thought.
One more question though, how many rows do you expect to have in Table A and in Table B ?
This is just to evaluate how involved and practical would be the solution I’m thinking of.
Thanks & regards,
Ael
Hi Daniel,
Thankyou for the reply, but, joining all the cells in one cell and then lookup, will it not have the same issue as using the joiner node mentioned in third post above?
Regards,
Siddeeq
Hi Ael
There are more than 700,000 rows in table A and around 1000 rows in table B.
Regards,
Siddeeq.
Hi @SiddeeqM
Good to know it. Would you mind please to upload here a bit of your data from file A and B in Excel or CSV format ? It would help me a lot to more quickly provide you with a solution.
Thanks & regards,
Ael
2 Likes
I do not see this issue because you replace the 000 with “” and do an absolute match like in the excel vlookup formula
1 Like
Good day @Daniel_Weikert
Build the workflow and you will see the issue 
Hi Ael,
Thankyou for putting so much of thought into it, As much as I want to help you with the data, but it’s a bit beyond my capabilities to do so.
Even a hint in the right direction I am pretty sure I’ll manage it.
Meanwhile i was exploring this node, rule engine (dictionary). I think that can be of help here. Let me know if you have any experienced opinion on it
Regards,
Siddeeq
Hi @SiddeeqM , so if I understand correctly, where you have “000” in the File B, it means to ignore (or a wildcard), is that correct? We’re not matching the value “000” in File A, correct? It means do not match this column/condition if it has “000” in it, correct? If that’s the case, “000” could be replaced by a regex wildcard in File B, and then the match would compare against a wildcard, which means any match.
EDIT: Could you share the 1000 rules?
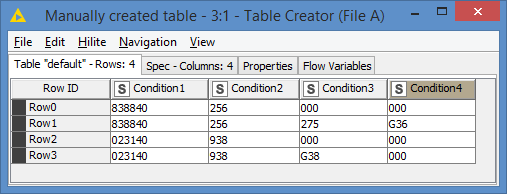
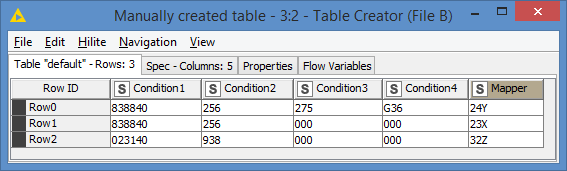
Hi @SiddeeqM
So, does something like this work for you?
File A:
File B:
Results:
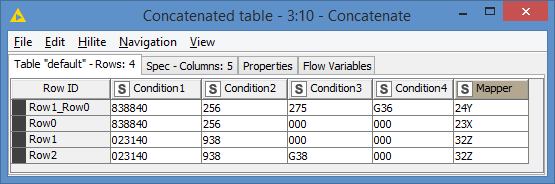
Is that the expected results?
This is how it was done:
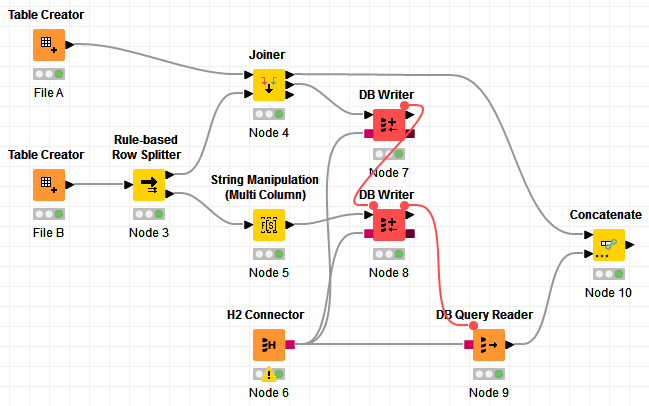
The idea is to first map where there are all conditions, so I separate the rules from File B in 2. Let’s call them:
File B1 = rules where none of the conditions have “000”
File B2 = rules where conditions have “000”
Note: for the sake of the demo, I assumed only Condition 3 and 4 can have “000”. You can adjust this if there are other conditions (hence why I wanted to see the 1000 rules). I also assume that if Condition3 is “000”, then Condition4 is also “000” as per what you stated.
I do a Left Join of File A with File B1. This will give me those that matched, let’s call it Result A1 and also those that did not match, let’s call it Result A2.
Now, it’s about matching Results A2 with File B2. I implement the idea that I suggested, that is to replace the “000” from File B2 with a wildcard. Knime does not allow to join on wildcard, so for this, I take advantage of H2. I convert the “000” from File B2 to H2 DB wildcard, which is ‘%’. I add the modified File B2 (with wildcard) and Results A2 to the HD virtual DB.
I then simply do a Join between the 2 with LIKE conditions:
SELECT a.*, b."Mapper"
FROM "PUBLIC"."file_a" a
JOIN "PUBLIC"."file_b" b
ON a."Condition1" LIKE b."Condition1"
AND a."Condition2" LIKE b."Condition2"
AND a."Condition3" LIKE b."Condition3"
AND a."Condition4" LIKE b."Condition4"
In the end, I concatenate Result A1 with the results of this query, and that’s it.
Here’s the workflow: Get mapper based on rules with wildcards.knwf (29.1 KB)
Hi @SiddeeqM
Thanks a lot for your kind message and for trying to do your best with your explanations.
No problem at all and always happy to help.
@bruno29a has just provided a possible solution based on database nodes. They are more flexible when needing to achieve conditional joins as in your case.
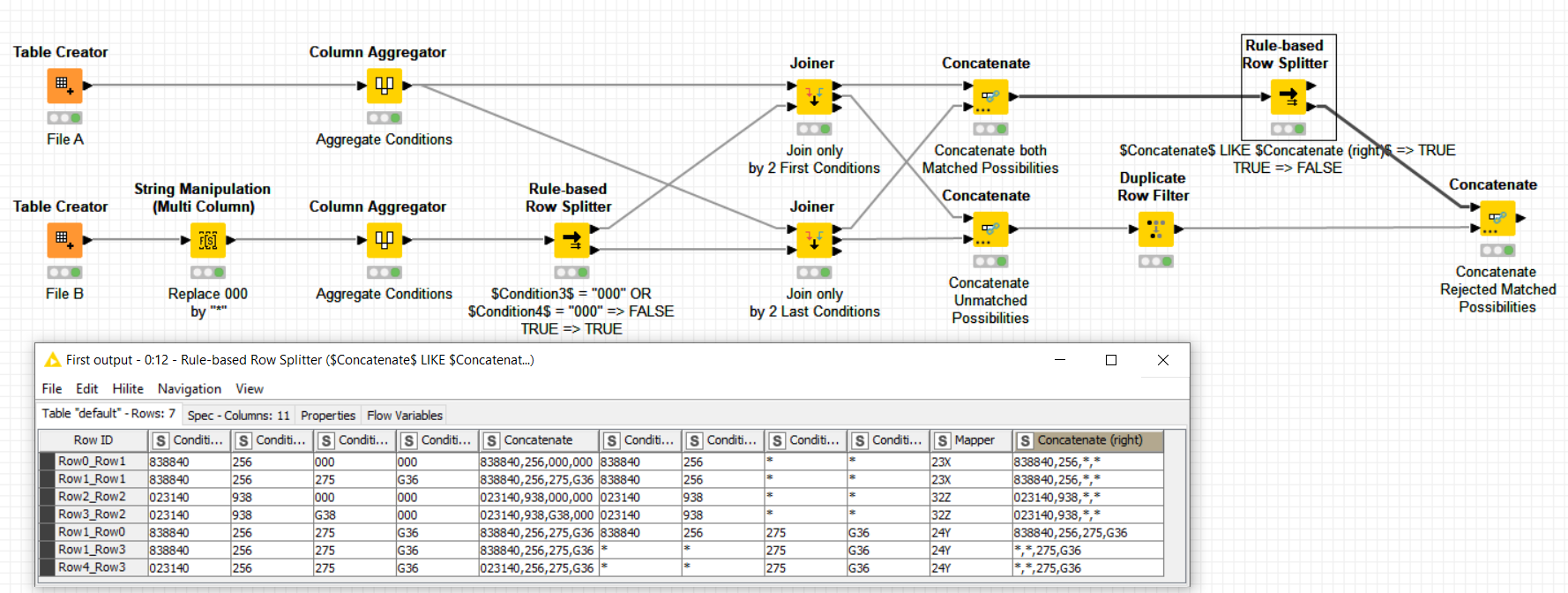
Complementary to @bruno29a solution, I’m suggesting here another solution based on a -Rule-base Splitter- node and the trick of replacing your “000” zero sequence by a wild char “*”. This wild char is interpreted as “anything” in a -Rule-base Splitter- LIKE condition instead.
The workflow is as follows:
20220315 Pikairos Create rules engine from another file.knwf (115.2 KB)
The workflow eventually and separately provides what matches and what doesn’t. The algorithm used is explained on the nodes step by step but please reach out if still there are unclear steps.
I guess this alternative workflow is doing what you need too. Otherwise, please reach out as well to tell us which are the required extra or alternative needs.
Hope it helps.
Best
Ael
1 Like
Thanks @aworker.
I will, i am curious. Time is rather short right now  but I will keep that topic in mind. Glad that therer are skilled “KNIMERS” like you and @bruno29a who kindly help and contribute your knowledge to the community here. Kudos
but I will keep that topic in mind. Glad that therer are skilled “KNIMERS” like you and @bruno29a who kindly help and contribute your knowledge to the community here. Kudos
2 Likes
Hi @aworker , I considered your approach, but I was not sure if there were only 4 conditions or if it was just an example, where in reality there are more conditions.
If there are only 4 conditions, with Condition1 and Condition2 being “linked” and Condition 3 and Condition 4 being “linked” (I know @SiddeeqM explained the rule about “000”), then this is fine. Otherwise the workflow is limited to just these 2 pairs of conditions.
That is why I opted to do it the way I did it, as it’s scalable to no matter how many conditions you may have.
That’s why I’m still waiting to see the 1000 rules of File B 
1 Like
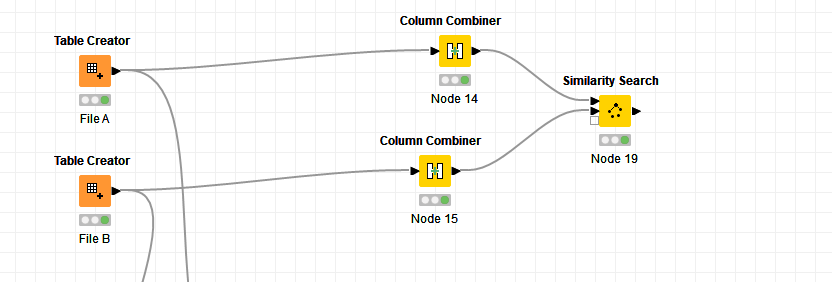
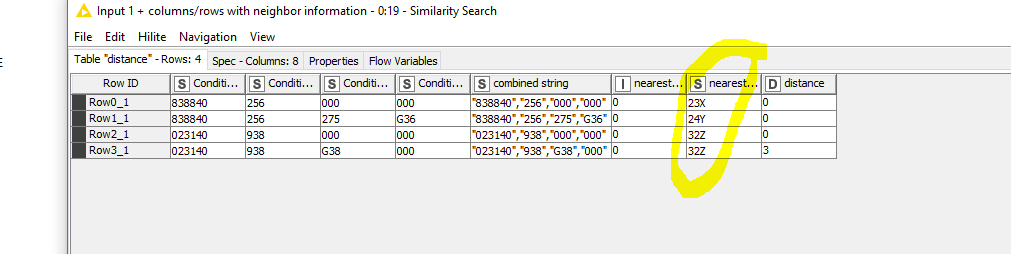
Thanks again for noticing me @aworker. Even if I do not have the time I should at least read the post more carefully. The exact match does not work so I tried another way using my original column combination idea together with string similarity
Of course a test on practise data is required to see whether it always fits the needs. Thanks again for pushing me here to give it a try.
br
2 Likes
Hi @Daniel_Weikert
Very interesting alternative. Could you please upload it ? What “distance metric” did you use ?
Best
Ael
1 Like