@Esma_Oezdemir hier ist ein Ansatz das zu transformieren. Die Blöcke werden identifiziert (anhand des Begriffs “Module*”) und dann nach und nach abgearbeitet. Die Spalte B dient als Column Header so würde das auch funktionieren wenn das mal mehr als 18 Zeilen sind.
Alles hängt davon ab, dass die Struktur erhalten bleibt. Etwaige Abweichungen müssten berücksichtigt werden. Deswegen ist Präzision in den Angaben so wichtig.
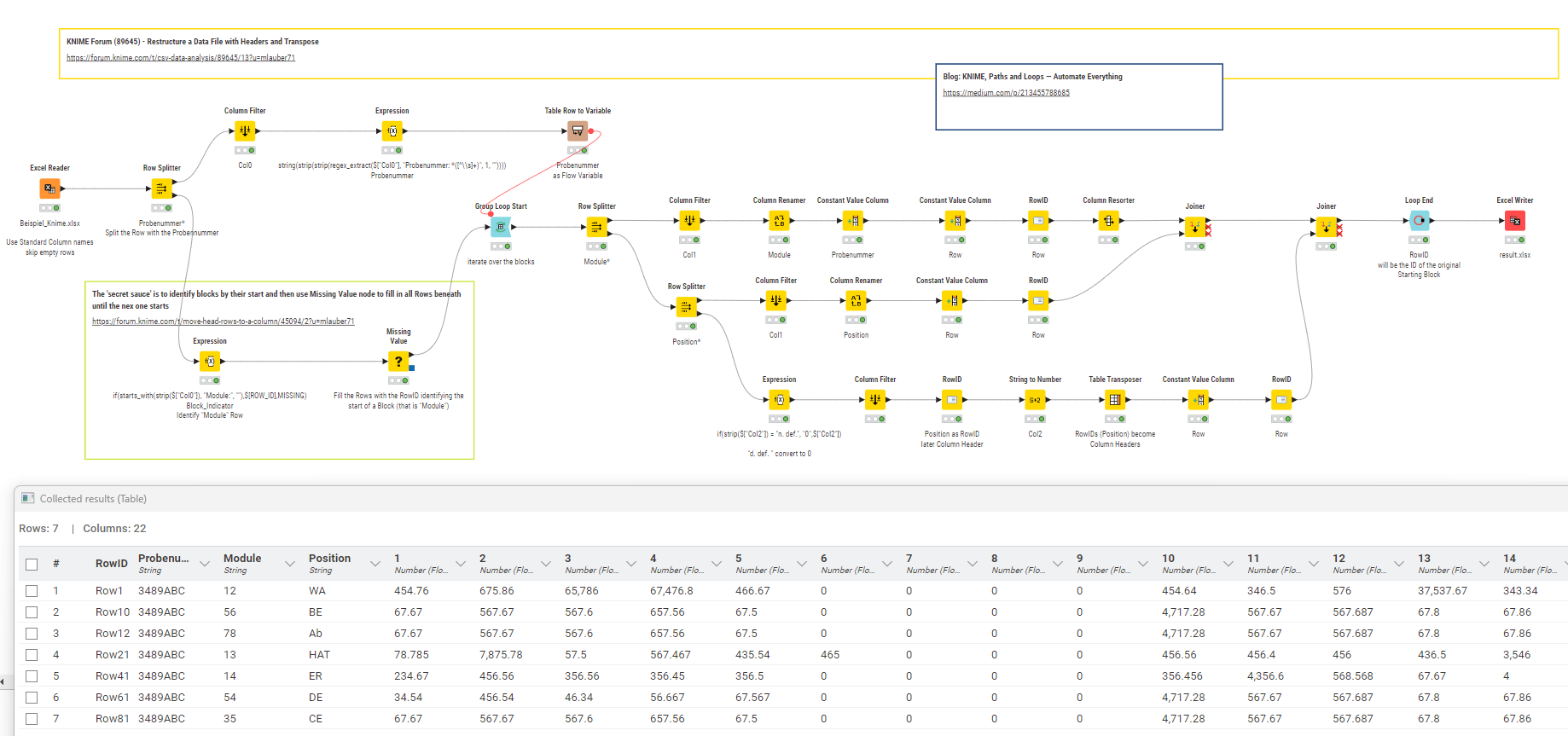
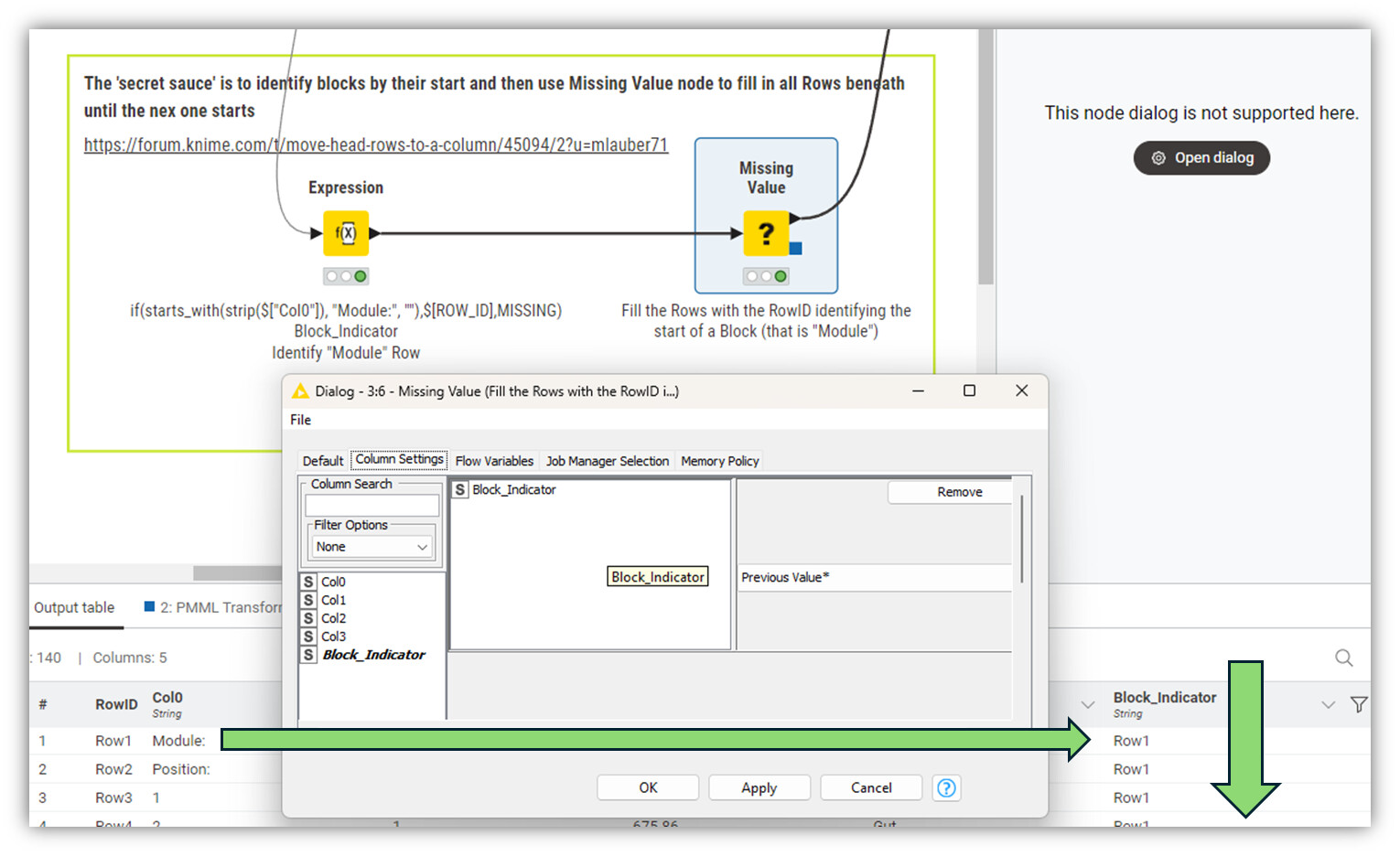
Das ‘Geheimnis’ ist den Start jedes Blocks zu finden und dann mittels des Missing Value Nodes einfach alle zugehörigen Zeilen aufzufüllen bis zum nächsten Block.