ich würde gerne mehrere CSV-Dateien wie folgt auswerten:
Ich würde gerne die ersten 5 Zeilen sowohl als auch die Spalten B und D rauslöschen.
Ich habe pro CSV-Datei um die 10.000 Zeilen die ich nach einer bestimmten Vorlage trennen und dann in Spalten umwandeln möchte. Sprich z.B. Zeile 1-20 wiederholt sich immer alle 25 Zeilen, ich will die die immer gleich bleiben in Spalten umwandeln. Und die Produktnummer die jeweils immer am Anfang der 20 Zeilen steht soll als Zeile bleiben und die jeweiligen Ergebnisse sollen dann in die zugehörigen Spalten eingetragen werden.
Am Ende würde ich dann gerne alle CSV-Dateien untereinander in eine Excel-Tabelle umwandeln. Dabei wäre es aber wichtig am Anfang noch den Namen der CSV-Datei in die Tabelle einzutragen.
Hat jemand schon damit Erfahrung und könnte mir helfen?
Vielen Dank im Voraus!
I would like to evaluate several CSV files like this:
I would like to delete the first 5 rows as well as the columns B and D.
I have around 10,000 rows per CSV file that I want to separate according to a specific template and then convert into columns. For example, lines 1-20 are repeated every 25 lines, I want to convert those that always remain the same into columns. And the product number, which is always at the beginning of the 20 lines, should remain as a line and the respective results should then be entered in the associated columns.
Does anyone have experience with this and could help me?
Thank you in advance!
Willkommen an Bord. Geht alles, Du musst es halt in kleine Schritte herunterbrechen.
Erste 5 Zeilen “löschen”: Im CSV-Reader unter “Limit Rows” einfach “Skip first lines” oder “Skip first data rows” verwenden
Spalte B und D “löschen”: Im CSV-Reader unter “Transformation” einfach das Häkchen bei den Spalten entfernen.
Damit hast Du schon beim Einlesen gleich nur die Daten zur Hand, die Du möchtest.
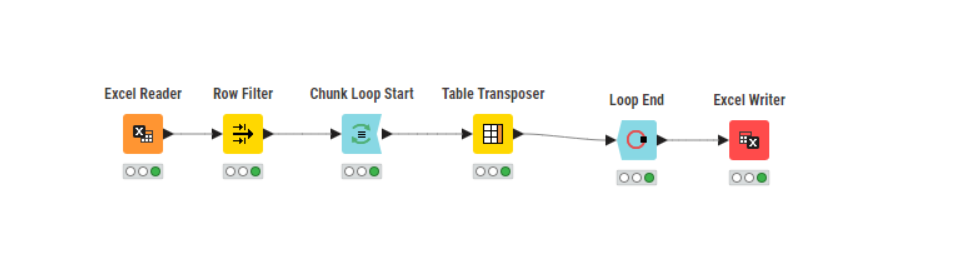
Danach machst nen Chunk-Loop mit Grösse 25, innerhalb des Loops dann ein Transposer oder vermutlich eher sogar ein Pivot. Loop beenden und mittels Excel-Writer ausleiten.
Mit dem Vorgehen sind vermutlich noch nicht alle Anforderungen erfüllt, aber ein Grossteil und ein Grundgerüst für die Details ist da. Für ein genaueres Verständnis müsstest Du aber einen Teil der Ausgangsdaten und des Zielbilds hier zur Verfügung stellen.
I merged your two threads since you were asking essentially the same question in two different languages. We have both English and German speakers here, so no need to post twice
Guten Morgen,
vielen Dank für die hilfreiche Antwort
Bin jetzt etwas weiter gekommen aber funktionieren tut es nicht wirklich.
Ich habe jetzt einen Screenshot von meiner Excel-Tabelle und meinem Workflow hochgeladen.
Habe ich da eventuell was falsch und wie könnte ich das Problem lösen?
@Esma_Oezdemir KNIME verfügt über eine ganze Reihe von Tools um solche Aufgaben in Schleifen und Schritt für Schritt lösen zu können. Es kommt dabei immer zentral auf die Planung an (wie eigentlich immer). Was sind die genauen Abläufe, was soll in jedem Schritt passieren, sind alle Sonderfälle abgedeckt oder werden abgefangen.
Vermutlich gibt es nicht einen schnellen Schritt das zu tun. Hier ein Beispiel für so einen Vorgang - nur um eine Idee zu bekommen wie das aussehen kann
In der Praxis wäre es am besten eine Musterdatei zu bekommen (ohne Geheimnisse zu verraten) und eine genaue Erklärung was passieren soll.
Hm, das sieht mir eher nach Pivoting als nach Transposing aus.
Stell Dir doch ganz einfach mal die Frage: Wie mache ich das bisher in Excel? Und das meine ich Schritt für Schritt. Jeder Schritt wird in KNIME dann zu einer Node. Das Pivoting ist dabei weder in Excel noch in KNIME trivial, soviel gleich als Vorwarnung. Darum kann ich Dir hier auch keine pauschale Antwort darauf geben.
Was aber ganz pauschal helfen könnte, ist das kostenlose “Von Excel zu KNIME”-Buch, das Du hier herunterladen kannst: From Excel to KNIME (German) | KNIME
Darin werden eben einzelne Excel-Funktionen wie auch das Pivoting auf KNIME übertragen und nebeneinander verglichen.
Hallo @mlauber71,
vielen lieben Dank für deine Antwort aber ich komme irgendwie nicht weiter damit.
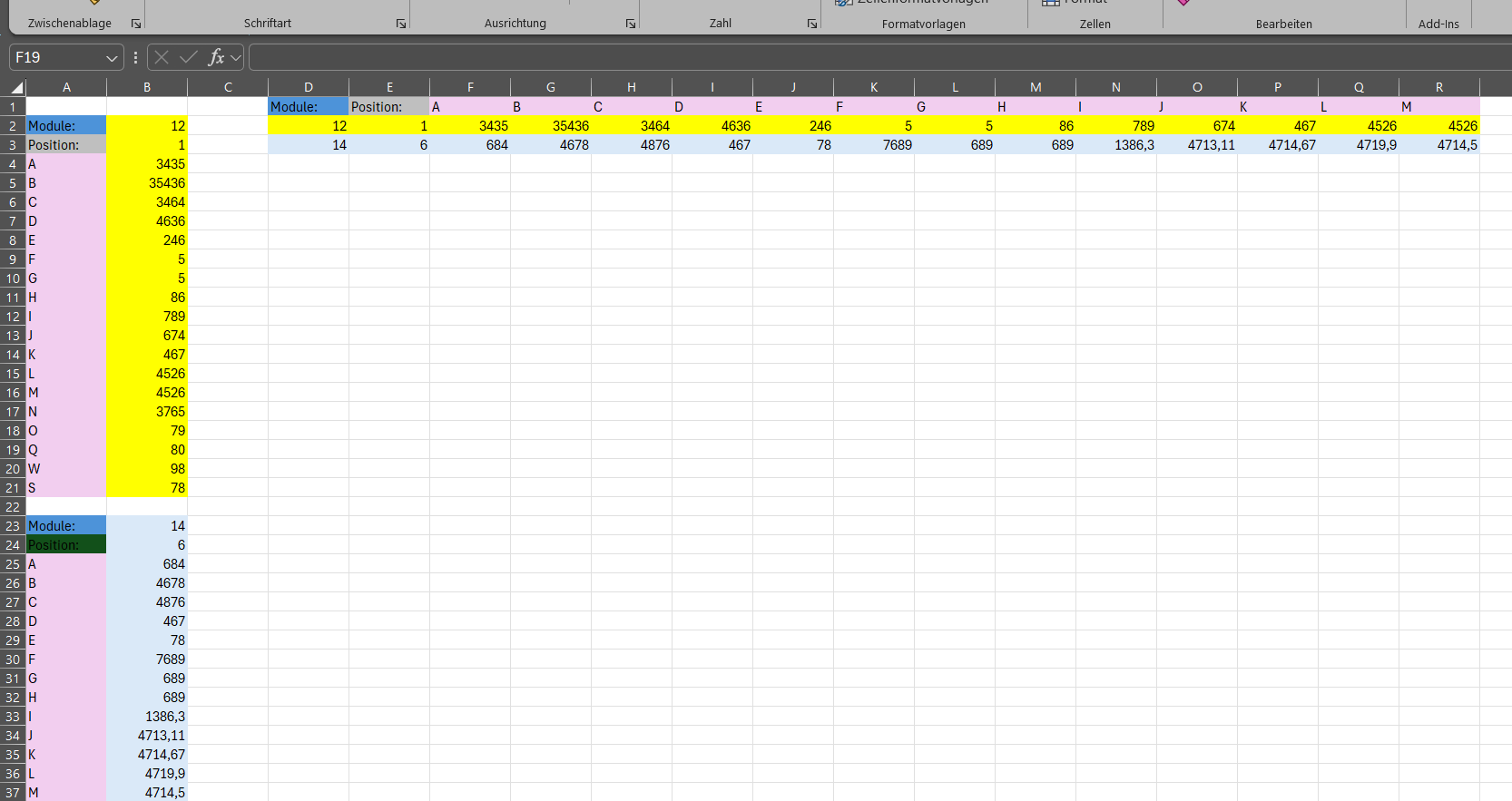
Ich habe jetzt mal eine Beispiel Tabelle erstellt so wie ich es mir vorstelle (In der echten Tabelle sind es rund 5000 Zeilen)
Hoffentlich ist es ein lösbares Problem und vielen Dank im Voraus
@Esma_Oezdemir das sollte machbar sein, Wo steht jeweils die Probennummer (kann es mehrere in einer Datei geben?), wo kommt die her und wie ist die Logik der Transformation der Zeilen zu Spalten. Ist die Spalte B die Nummer der Spalten inn der Transformation?
Gibt es immer 18 Zeilen mit Daten oder können es auch mal mehr oder weniger sein?
@mlauber71 Es gibt nur eine Probennummer pro Datei die nur in der A1 steht.
Die Spalten B und D enthalten keine wichtigen Informationen und werden deshalb gelöscht und haben mit der Ziel-Tabelle keinen Zusammenhang.
A6 bis A25 sollen zu Spaltennamen werden und die jeweiligen Werte für jede weitere folgende Messung sollen dann darunter eingetragen werden
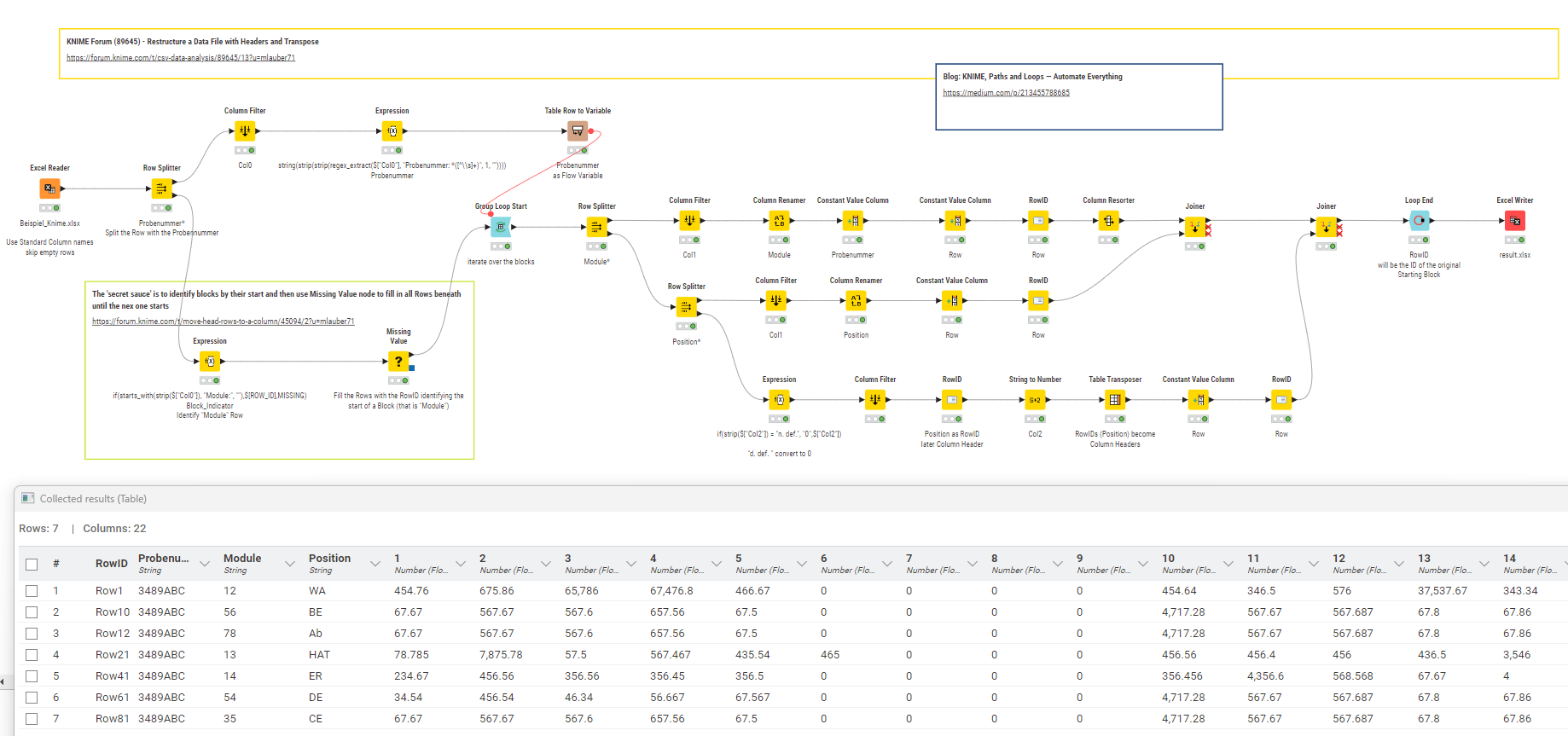
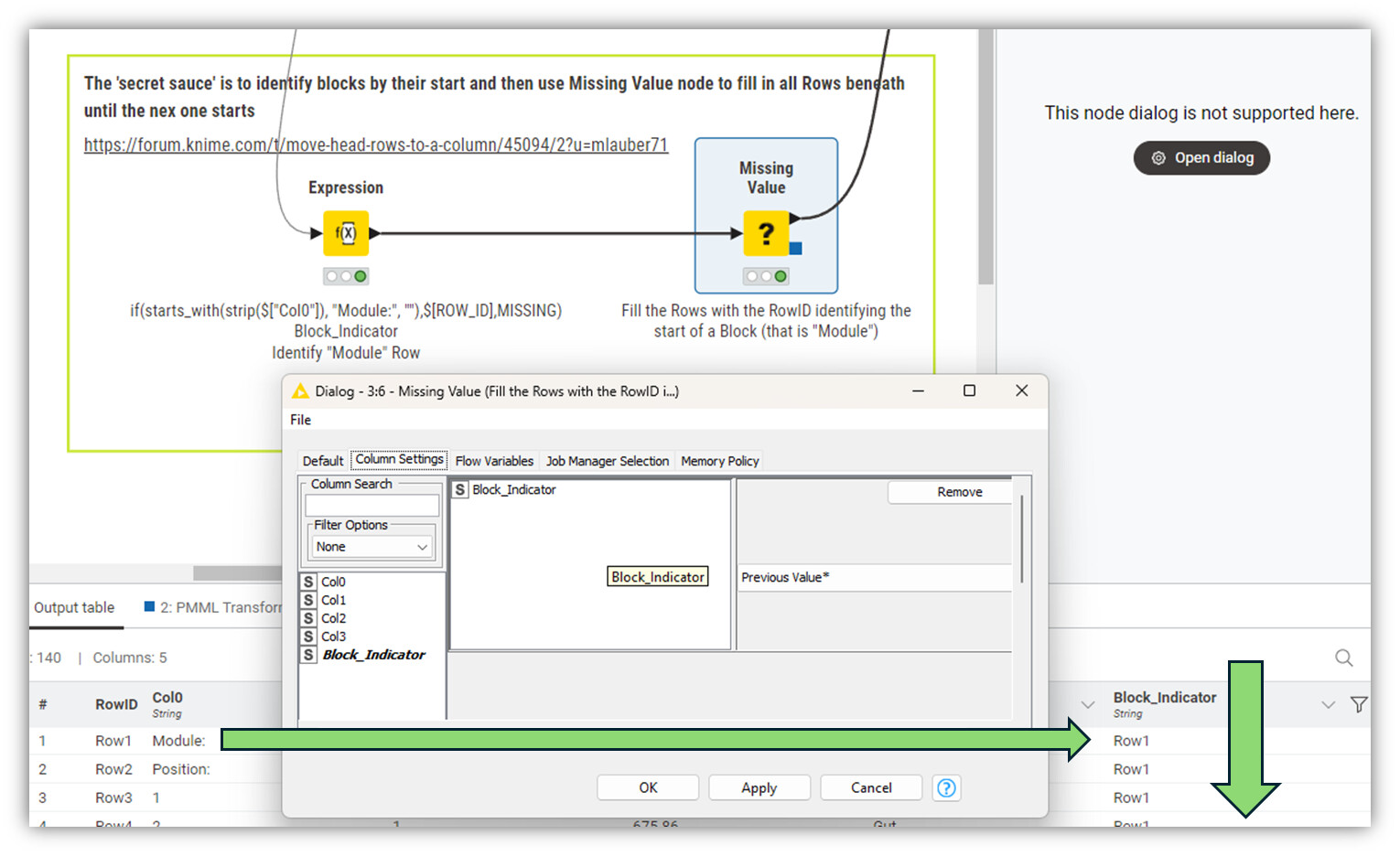
@Esma_Oezdemir hier ist ein Ansatz das zu transformieren. Die Blöcke werden identifiziert (anhand des Begriffs “Module*”) und dann nach und nach abgearbeitet. Die Spalte B dient als Column Header so würde das auch funktionieren wenn das mal mehr als 18 Zeilen sind.
Alles hängt davon ab, dass die Struktur erhalten bleibt. Etwaige Abweichungen müssten berücksichtigt werden. Deswegen ist Präzision in den Angaben so wichtig.
I see the others have answered in German. I will answer in English.
This bit is easy. There is a setting in a csv reader to skip rows and there is the transformation table to remove columns you don’t want.
Sounds like a chunk loop would be perfect for this! You can define a chunk loop to extract chunks of 25 lines and then do the processes you need on each chunk.