Hi;
After the main link page, the main page’s html data appears when I want to retrieve data from other sub-page URLs. Is there an example workflow on how to solve this problem now?
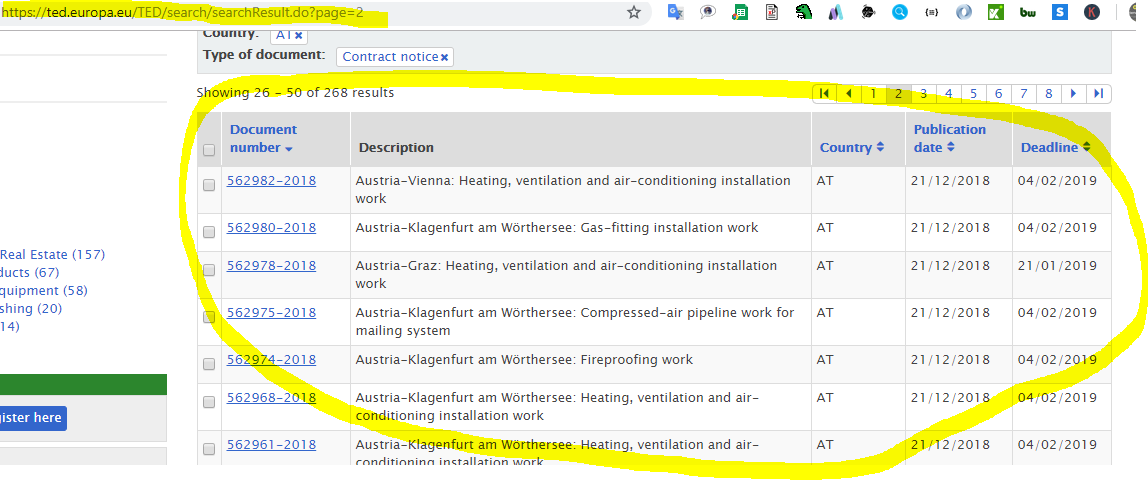
I want to get the data on the pages below. But I did not try different experiments.
I think it’s moving with “cookies” from the home page. when I try this method it brings me the html on the main page.
I couldn’t figure out how to do a workflow on how to get the page data.
I looked at above’s example. As it’s pulling in data via JS/AJAX/XHR, there’s no easy way to to use GET Request or HttpRetriever, instead you’ll need a full browser as provided via the Selenium Nodes. Please see this reply for an explanation:
Simply way to detect this:
Disable JS in your web browser and try loading the page. If the desired content does not show up, you’ll need “real” web browser as provided e.g. via Selenium Nodes.
thanks for the answer. I’m thinking of buying Palladian nodes, but I have a question mark on my head. I think that the process of getting this data will be much extended because it will open a web page which will have to scan multiple pages.
Do you think it is possible to serialize it with palladian nodes when I want to scan too many web pages (opening the browser / working in the background)?
the Palladian nodes are free (for use in free KNIME versions)
the Selenium nodes are paid
In case you’re wondering whether the Selenium Nodes are the right tool for your task, I invite you to give the free 30-day trial a go.
From my experience:
I’ve used the Selenium Nodes several times to crawl high amounts of pages. Of course, there is a larger performance overhead compared to a pure “download page” approach like with Palladian, but you can often optimize/parallelize/etc. Still, your throughput will always be slower with the Selenium Node, as these are using a real Web browser. But often, that’s the only way to access current web pages resp. web apps.
My suggestion: Try out the trial version and see whether it works for your problems. Feel free to get back if you need any advice regarding optimization.