Hello, I want to know if this is possible. I have a flow that counts this flow daily, new data is added to it, the procedure that had been carried out until now was to read the new data, concatenate it with the previous ones and run the flow of new
My doubt is that you can make knime identify new values from a folder, that is, read the 19th and the 20th and join them automatically and the second thing is if this can be programmed. So I know the latter is possible with the server, which server is good for me, I am an independent worker.
Hello, it helped me a lot, I was guiding myself with it, however I have two doubts, you know why in the loop end it duplicates the columns for me and if it is possible to program this node every time period, that is, every day at 7 am
Hello @Jalvear
I’m glad to read that you found the workflow useful. About why the loop end duplicates some columns in your data is something that I can’t evaluate with the information you are providing right now. If you can provide some sampled data, mock data or a picture with the details of the issue, we may be see what’s going on.
About your questions regarding KNIME Server and how to automatize the schedule of a workflow run, or
about which server adapts more to your needs; there are some colleagues in the forum that can provide you some more information.
In the meantime, you can check the following post with some info and ideas about the very same topic.
@bruno29a and @morpheus suggest to do it via batch mode…
Then you may be able to schedule the task by using desktop version as well (?)
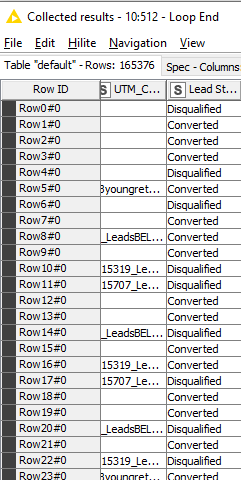
I don’t see what you mean by duplicate…
What I can see here is:
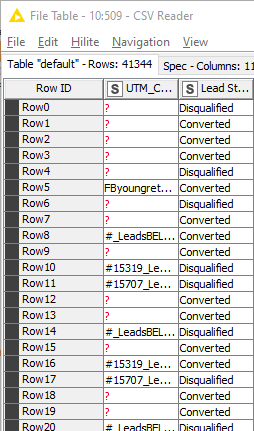
Your upper table is the output of the Loop and it is reading x4 times the file in the lower table (41344 Rows x 4 = 165376 Rows). The RowID tells you the row number read in reference file, the number after the hash is the loop iteration.
This can happen because: A) your ‘file reader’ is receiving 4 times the order to read the same file. B) there are 4 templated files with the same number of rows (?).
What you can inspect and review is:
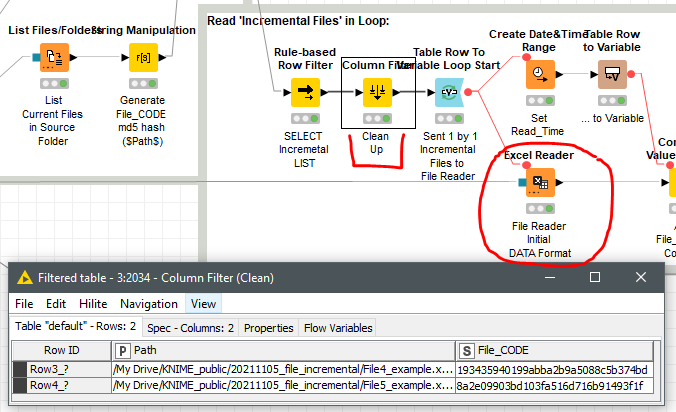
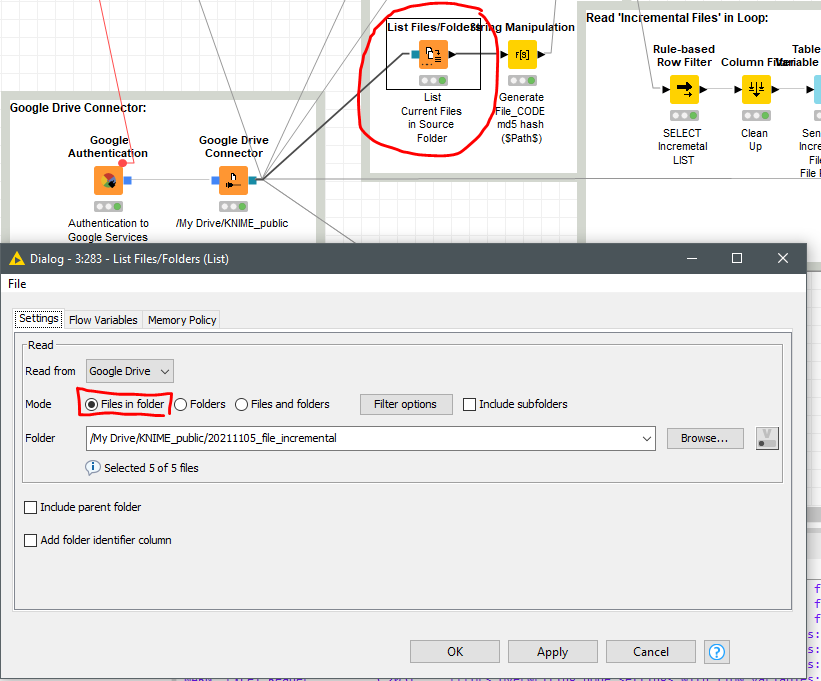
Looking at ‘Incremental workflow’ as reference; the “column filter / clean up” node is the feeder for the ‘file reader’ (see the picture), 2 files are fed in the example.
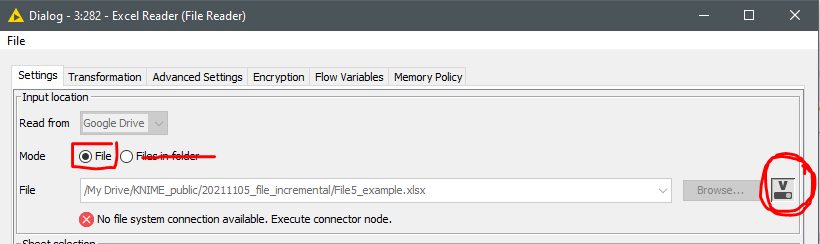
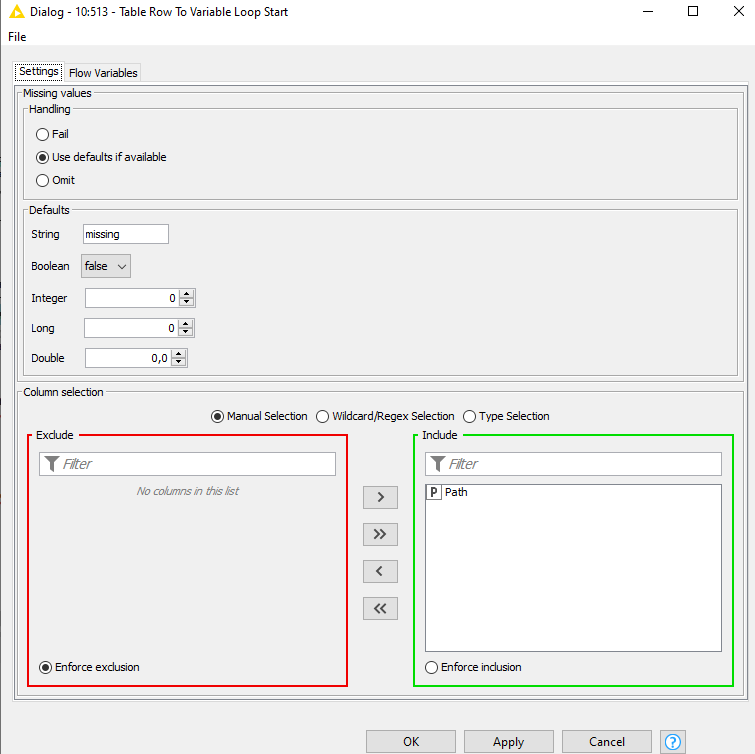
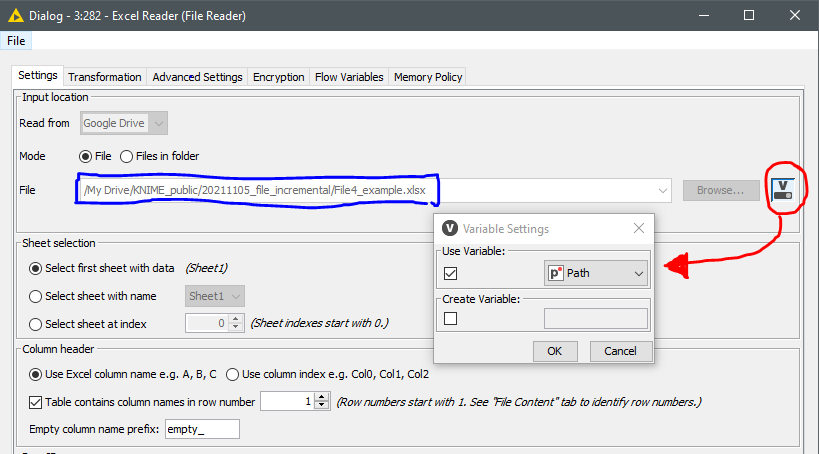
If the previous step looks right what you expect… next step will be to inspect the file reader configuration itself. Check that your excel reader is controlled to read from the variable (the icon rounded in red) , variable “Path” is the option as you are feeding through a ‘Table Row to Variable Loop Start’ node. Check that option ‘File’ is selected as well.
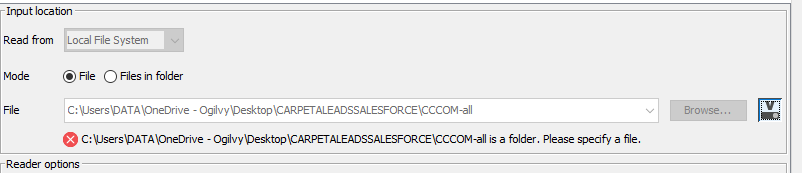
Take a look to your warning… It is not reading a file, it says: "C:\Users […-all] is a folder. Please specify a file. "
Try this: Click on the right icon with a “V” that i circled in red in my picture. It will open a pop up (check in your main screen just in case) to configure the ‘variable-in’ as “Path”