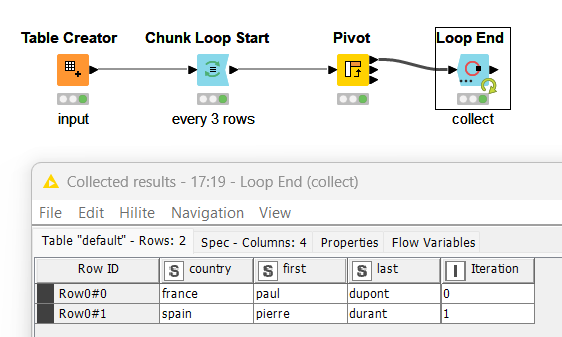
Hello, I have a dataset with categories in one column and values in another column. Each occurrence is listed one after the other. For example:
Last Name; DUPONT
First Name; PAUL
Country: France
Last Name; DURAND
First Name; PIERRE
Country: SPAIN
I want to place the category as the header and each value on a separate line. I used the Rule Engine node to define the case, and I performed a pivoting node. As a result, I have my categories as headers, but all the values are in the same row, separated by commas. How can I put each occurrence on a separate line?
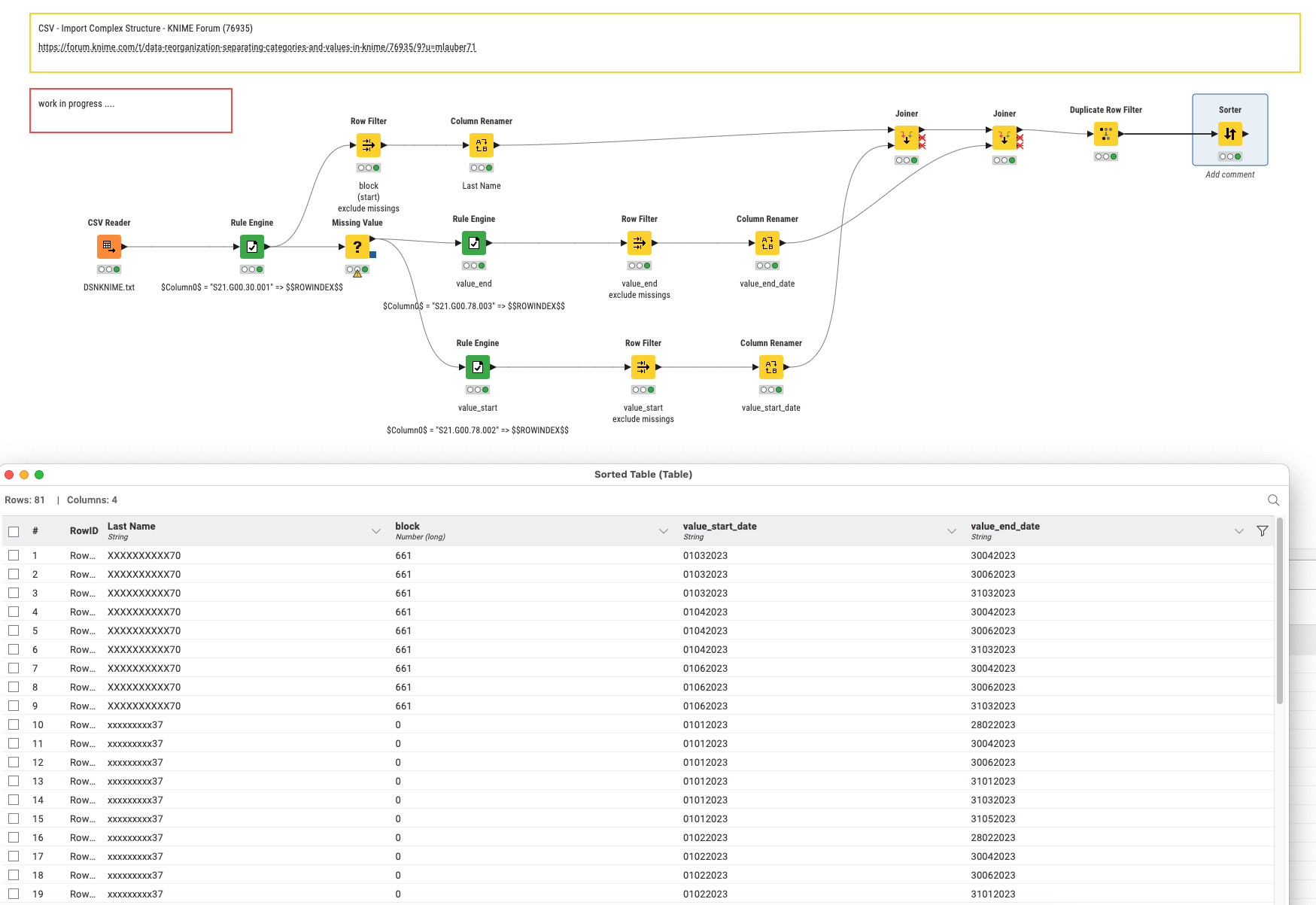
I have anonymized my file. The section codes start with ‘S’, and the values are in the following column. Therefore, I want the section codes as headers. For the rows, each change of person occurs as soon as we find the section code S21.G00.30.001, which is their identifier. All the information about the person follows until reaching the next person with the same code. What is important to me are the codes S21.G00.78.002 start date of the period and the code S21.G00.78.003 end date of the period. I need as many lines per person as there are periods that concern them. Ideally, it would be necessary to make a line for each section that differs by person and group them afterwards. DSNKNIME.txt (20.4 KB)
@aurelienchauvin I tried to take a look but was not able to make sense of your data. So the fist step would be to clearly define what data you have and what task should be done and provide an example that fits this description and where you can explain which outcome you would expect.