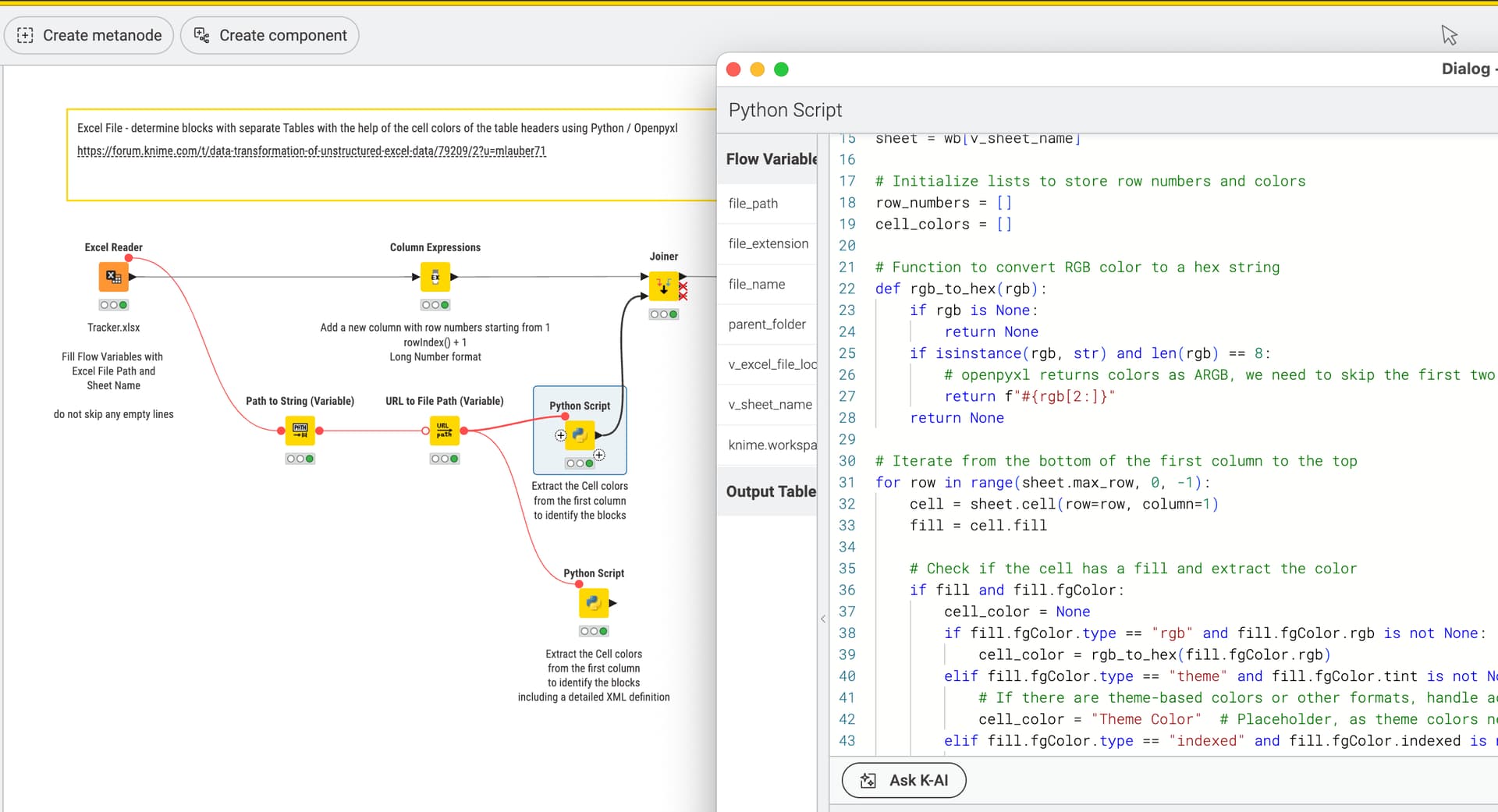
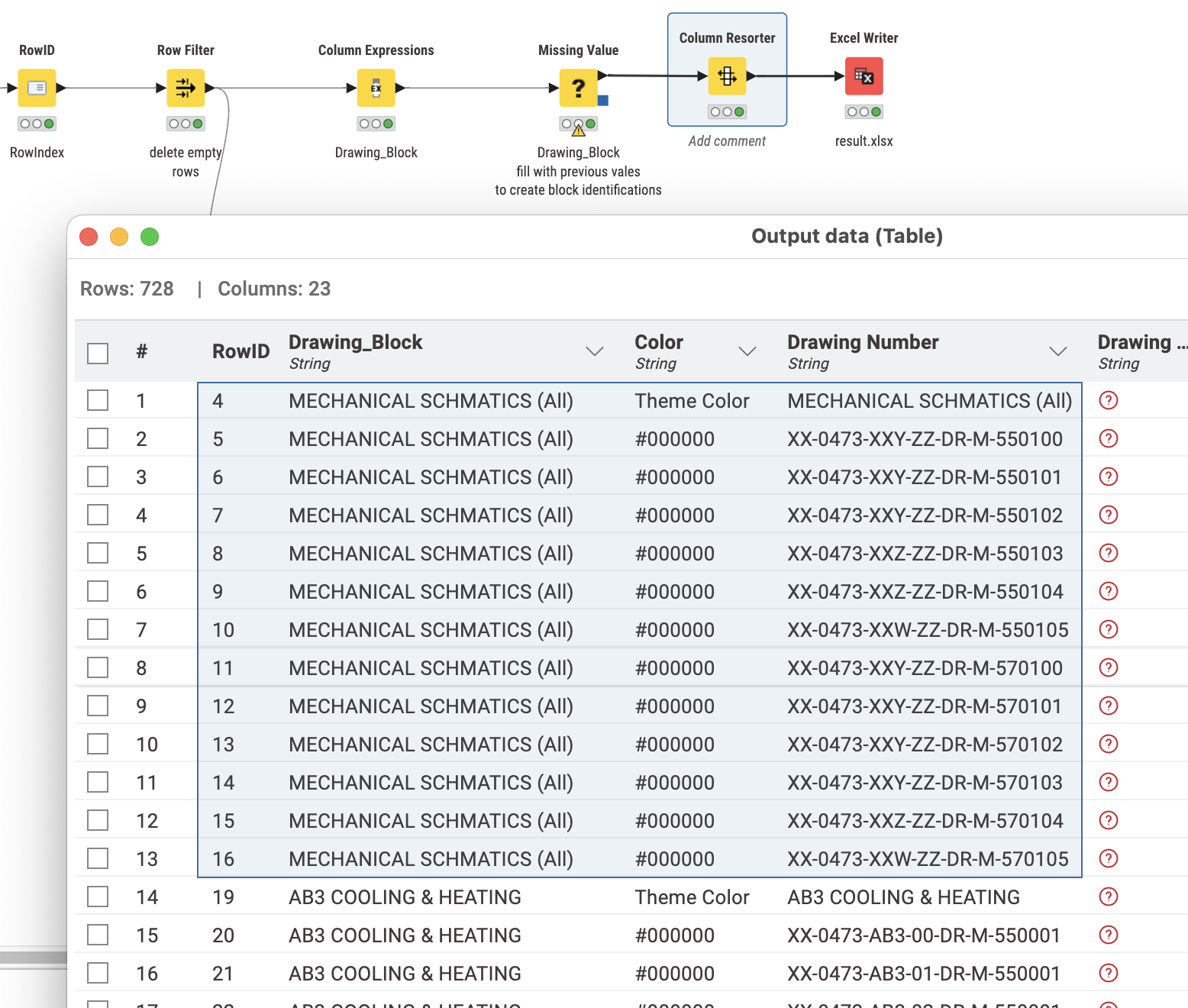
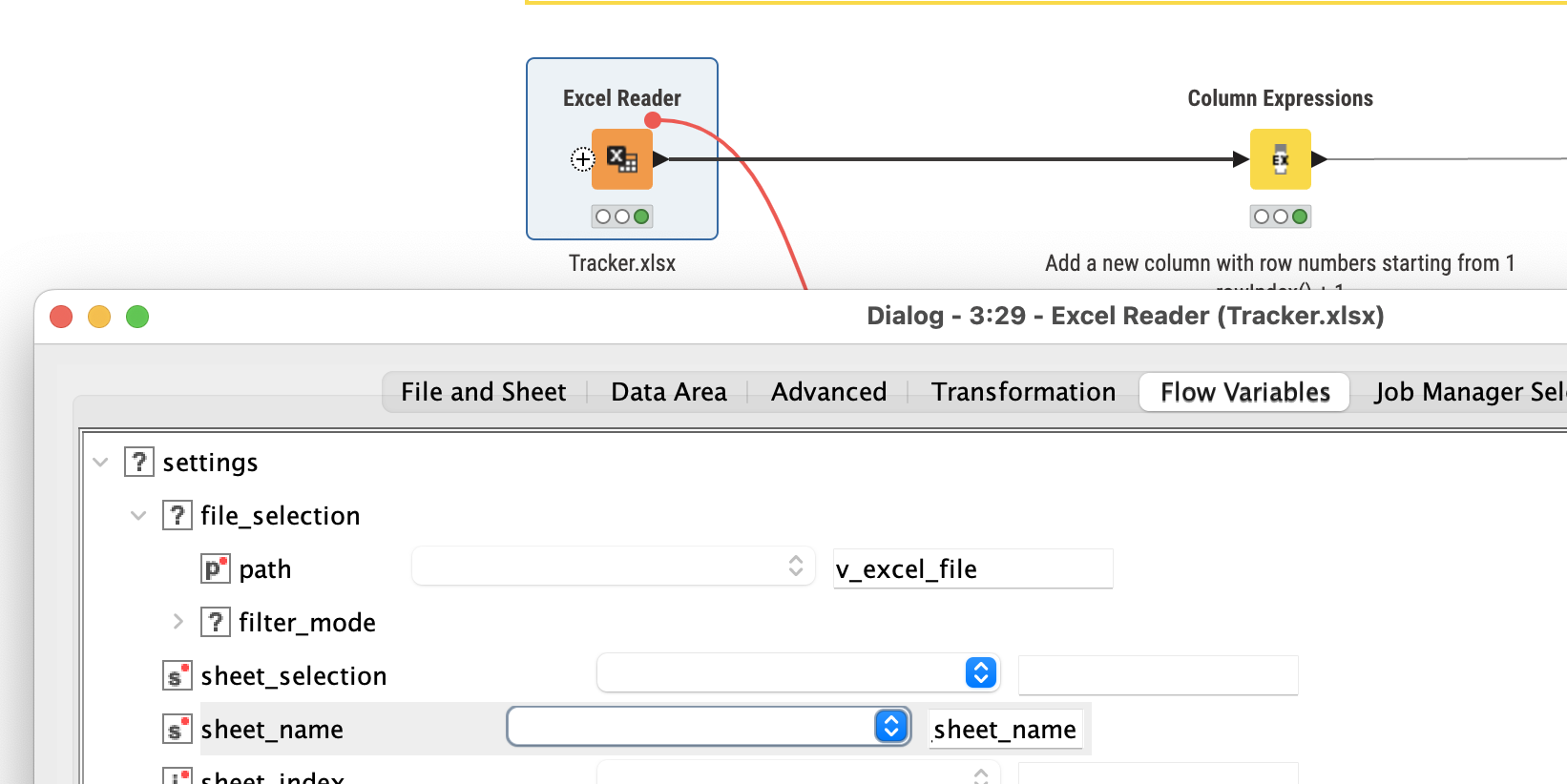
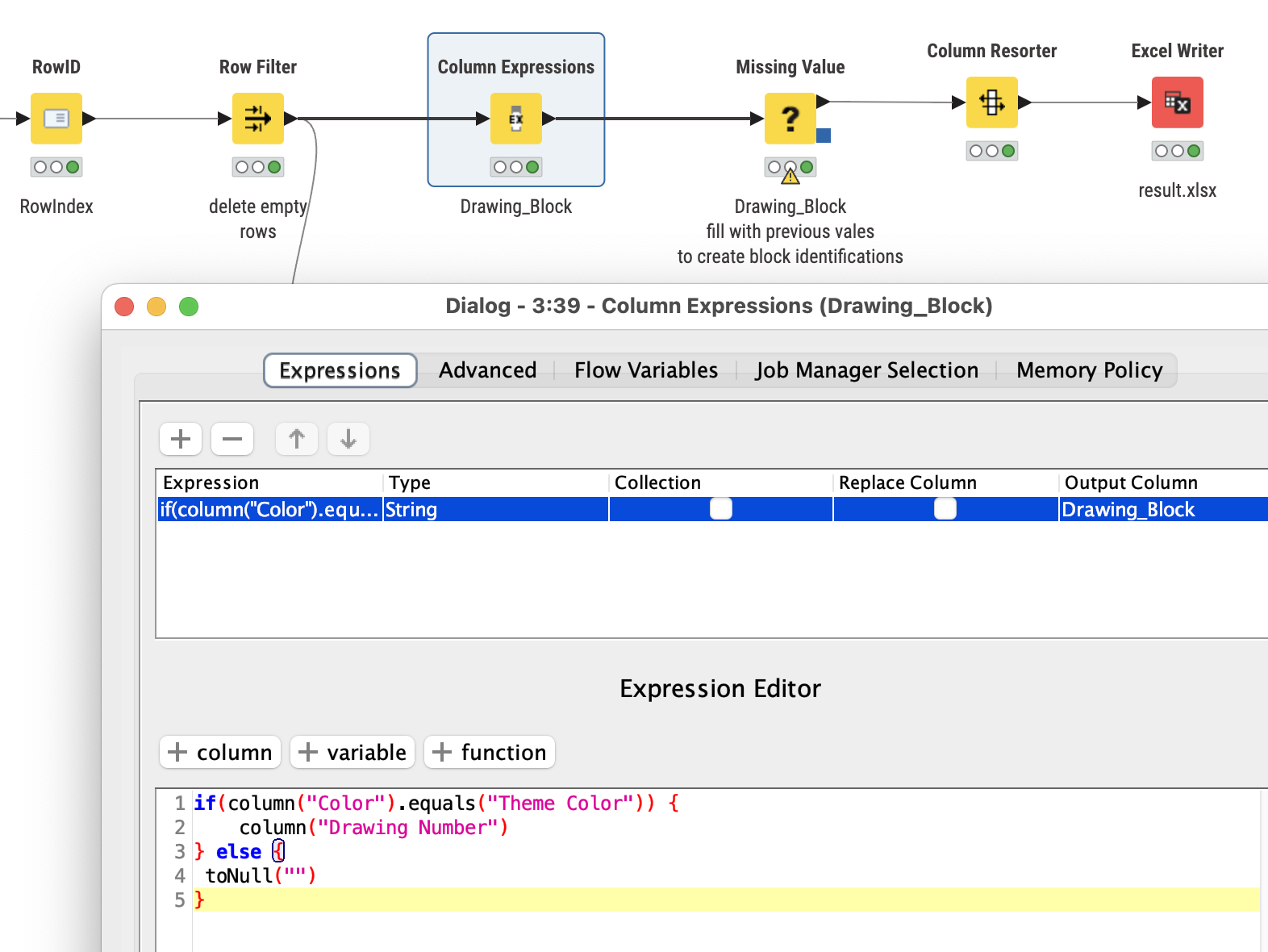
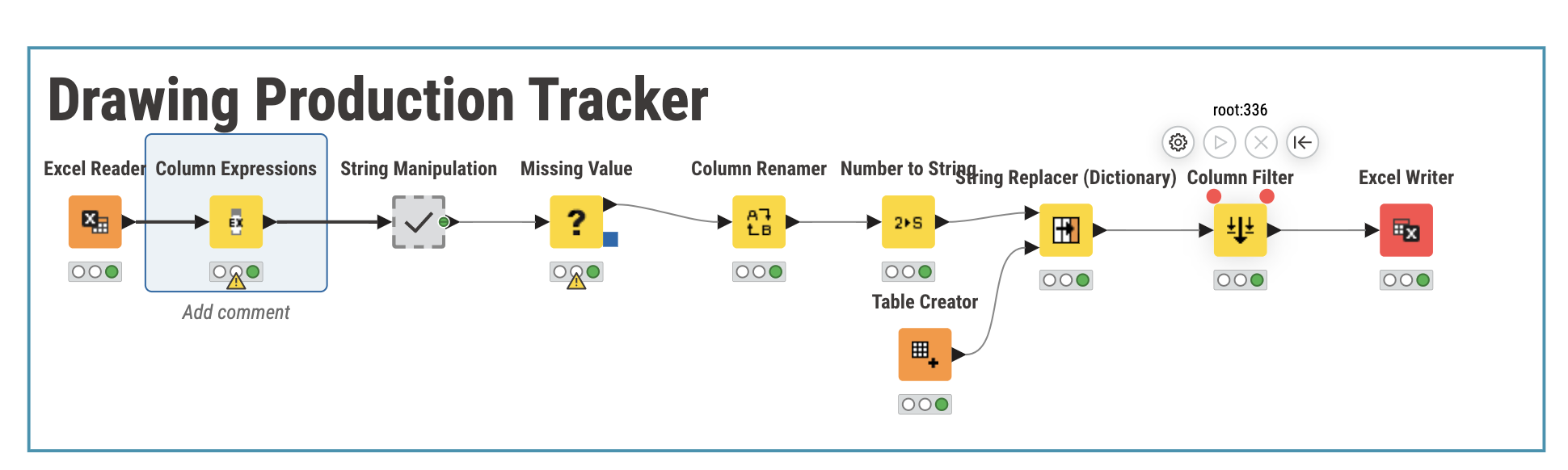
I’m relatively new with data transformations and KNIME and was wondering how you’d go about transforming an excel spreadsheet like the attached into a more usable format for power BI.
Each drawing comes under a heading like Mechanical schematics (lines with a blue or green fill). I’d like to obtain information on document status which can be filtered out by discipline, location, is it overdue, whilst keeping the raw information as well if more detail is required on the dashboard. I can’t change the excel trackers format as these are locked by the company and there will be more drawing records attached to this.
I’ve removed sensitive data like company name and location.
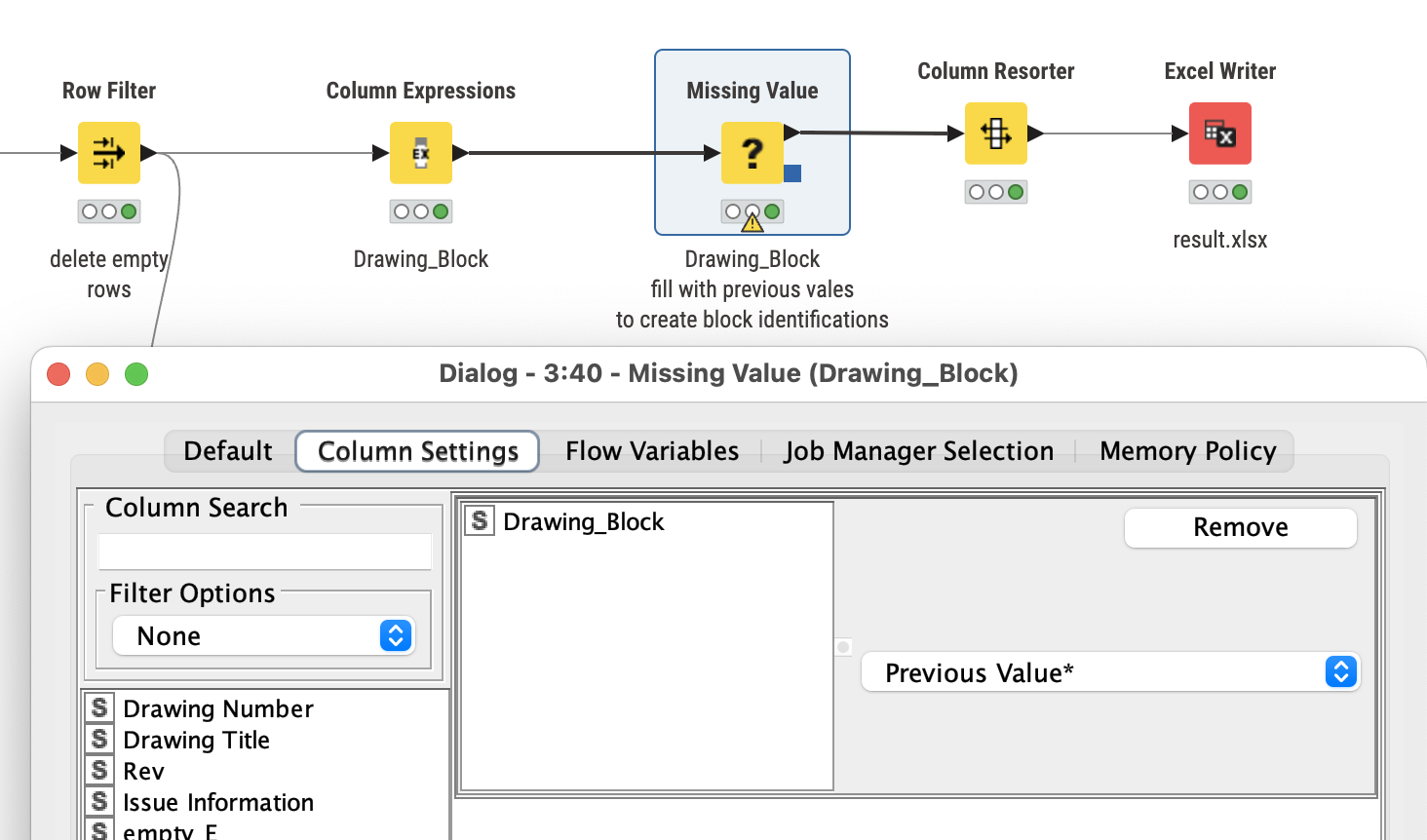
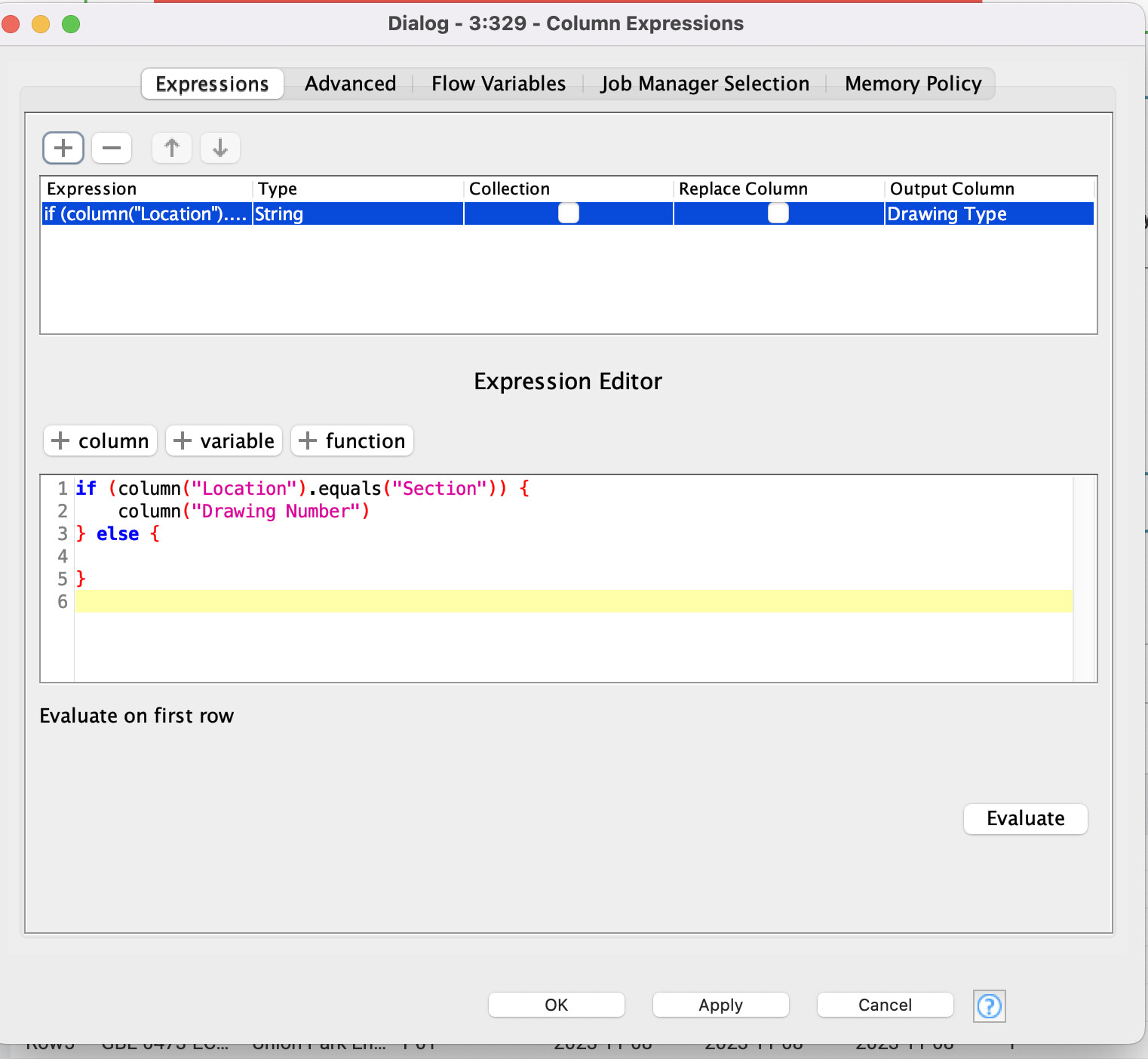
Column Expression node is used to set the Drawing Number when the right (family of) colours is being found. You could also work with a reference table here matching all Drawing Numbers.
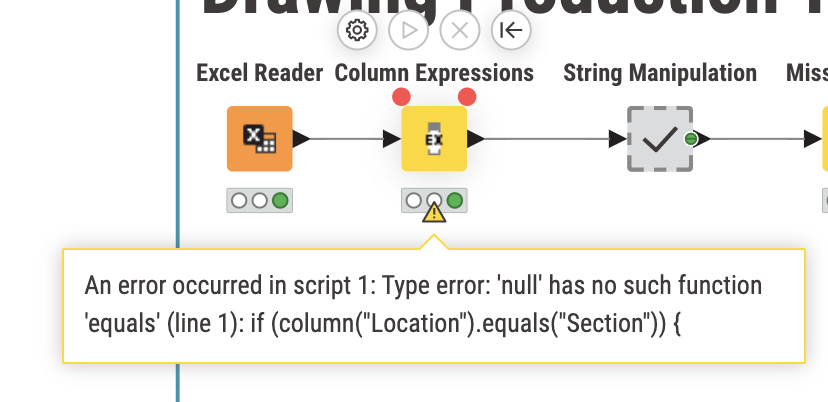
would it be possible to use a column expression node instead? so I use the location column and every time it says section, in a new column return the value in the first column and then use a missing value node to fill the values?
On the tracker I sent, I removed that information as it may be considered sensitive information on the project. The same method could be used for the ‘latest’ ‘discipline’ or ‘service’ column.
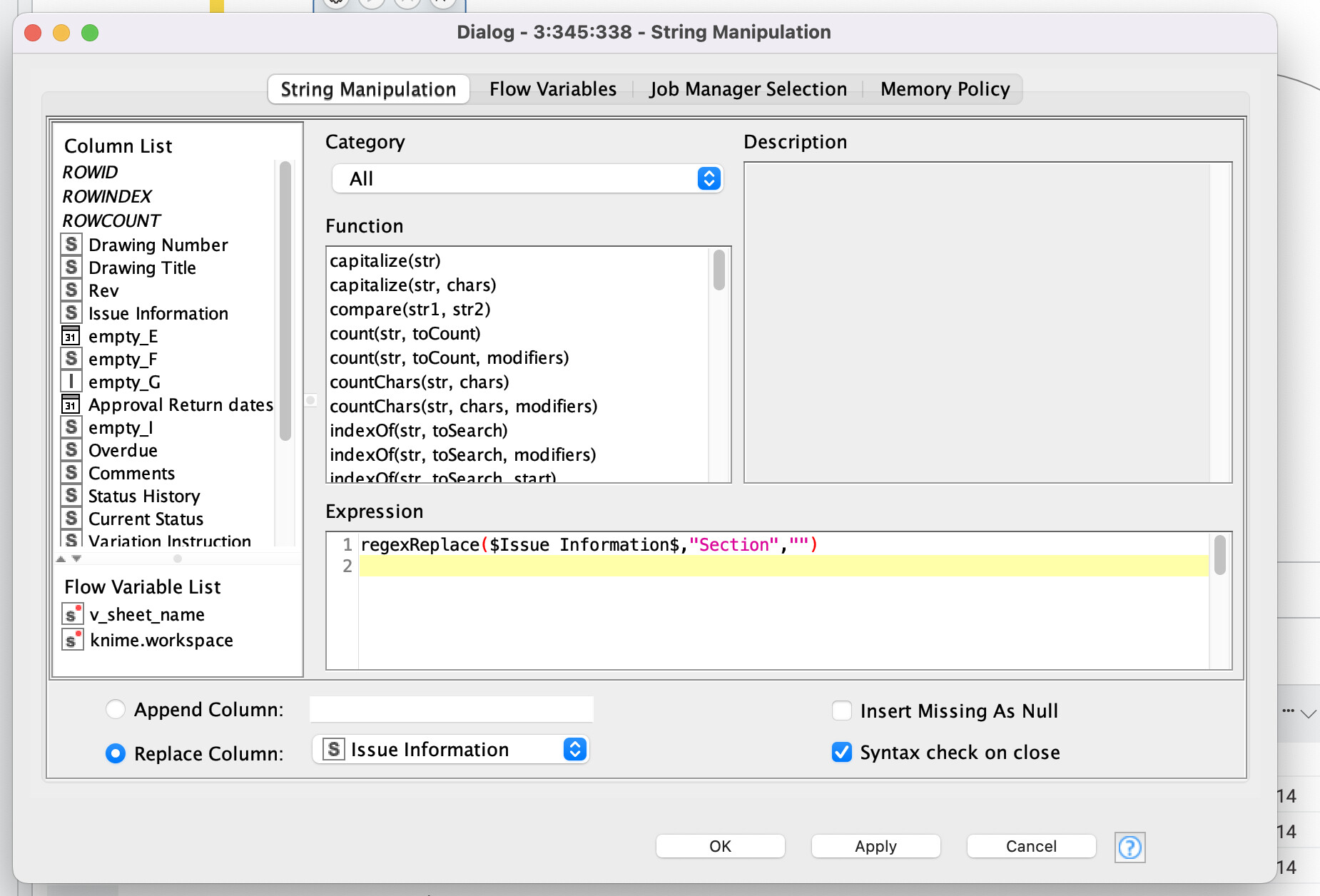
I then used a set of string manipulation nodes to remove the word ‘Section’ as I found the missing value node seemed to copy the word section to other cells that should have dates in it.