Hi, I would like to use the database query editor node to add a column ‘test’ to a datatable I have connected to, via Hive, in the database. I use the following SQL statement that results an error.
ALTER TABLE #table#
ADD test VARCHAR(25)
Similarly, the simple SQL code ‘SELECT * FROM #table#’ results in an error also, which I seemingly resolved by adding 'SELECT * FROM #table# as temp '…
I have tried adding as temp to the the first statement to no avail.
The error is ‘Execute failed: [Cloudera]HiveJDBCDriver ERROR processing query/statement. Error Code: 40000, SQL state: TStatus(statusCode:ERROR_STATUS, infoMessages:[*org.apache.hive.service.cli.HiveSQLException:Error while compiling statement: FAILED: ParseException line 1:15 cannot recognize input near ‘(’ ‘ALTER’ ‘TABLE’…’
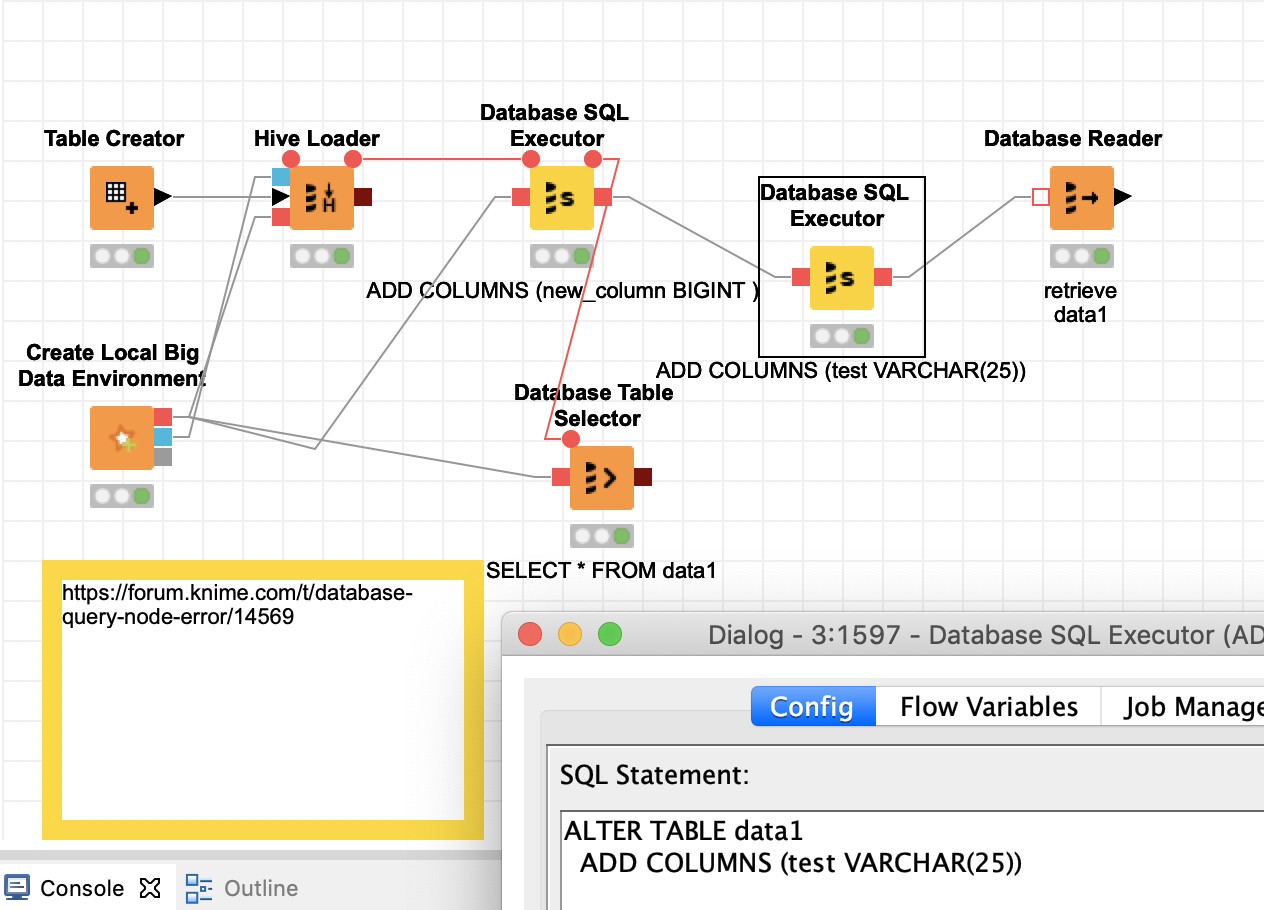
Maybe you could have a look. You could either use the Database Table selector and then do manipulations or just use the SQL executor (my preferred method).
Please note: you might want to think how to handle the ADD variable. I think the structure of Big Data tables is not fond of too much manipulations and adding stuff. It is optimised for effective storage and access, it is not an ORACLE db. Especially if you are dealing with partitions and complicated structures you might want to think if updates and add ons are the right way, especially if you have to populate them later - but that of course depends on you data and business case.
The good thing with KNIME you get a built in Big Data environment where you can test a lot of things and later just connect the real thing.
Thank you for the detailed answer and taking the time to create a clear example workflow.
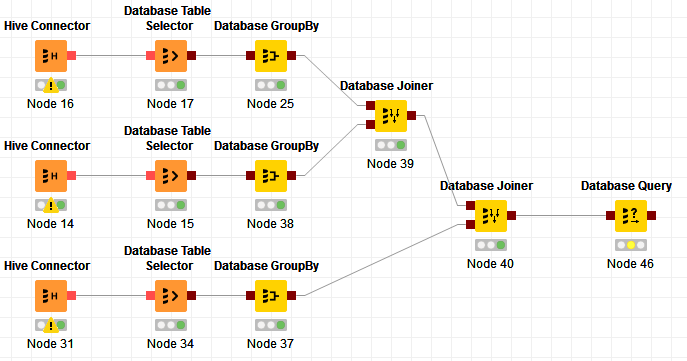
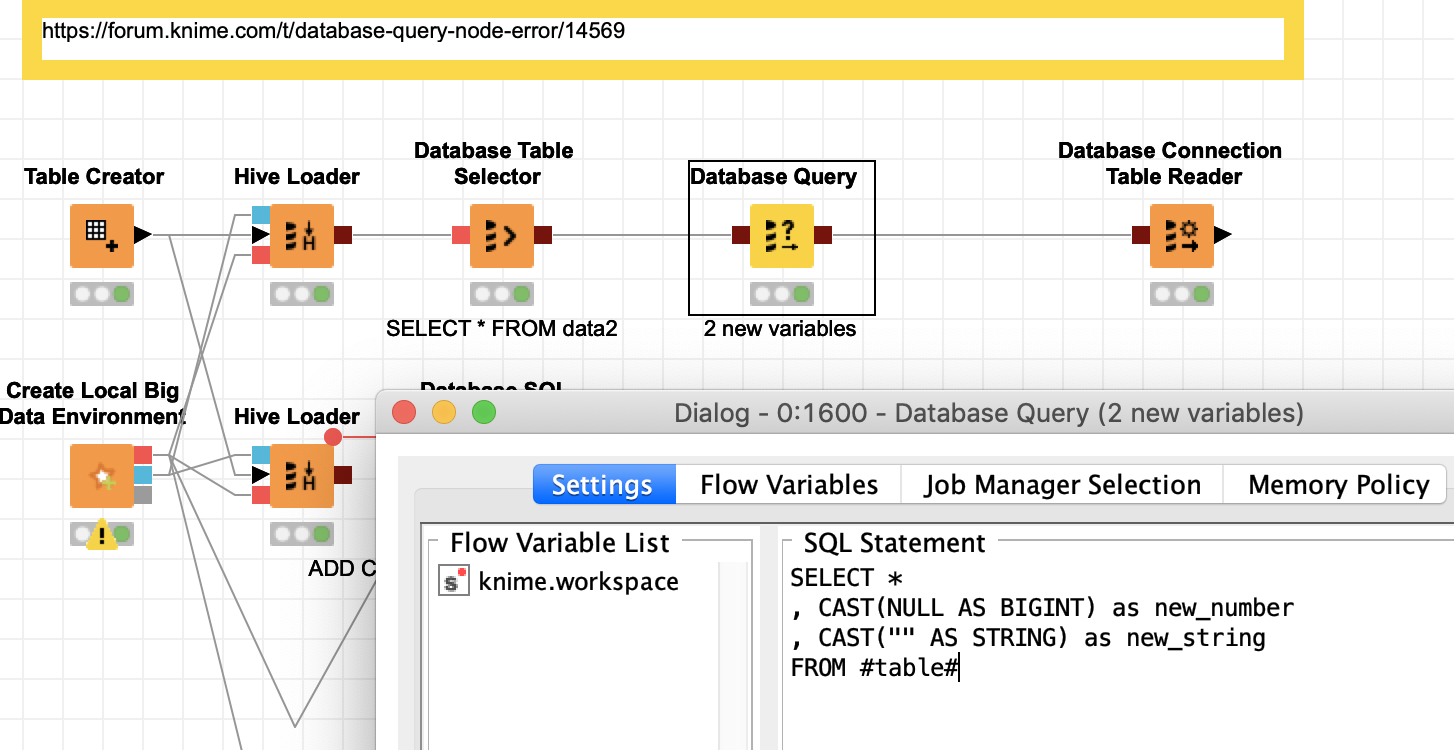
Currently, my workflow looks like this .
I have been using the Database Table selector and then doing the manipulations. This allows me to utilise the available database manipulation nodes (I am quite new to SQL). It doesn’t seem that the Database SQL Executor gives you a preview of the resulting table either. I feel like I have reached a roadblock as the database query after the Database Joiner doesn’t want to run.
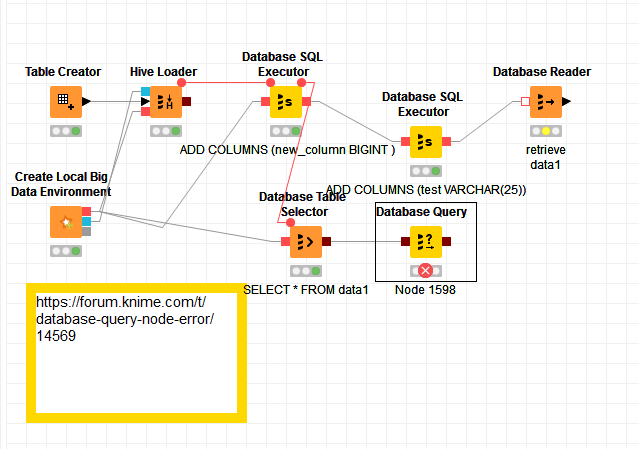
I even attempted to add a column with database query node after the Database Table Selector in the example workflow you kindly created, with the following statement:
ALTER TABLE #table#
ADD COLUMNS (test VARCHAR(25))
but this gave me an error also (although I believe this to be due to a different reason): ‘…mismatched input ‘FROM’ expecting (line 1, pos 9)…’ .
Ideally, I would like to transform the BD datatables without loading the table into Knime and then write the updated datatable back to the BDA.
Apologies if you have answered some of my queries in your reply, I am quickly trying to adopt Knime and SQL.
That was my initial thought. I tried that format with various subtle changes e.g.
ALTER TABLE #table# ADD COLUMNS (test STRING)
ALTER TABLE #table# ADD COLUMNS (test VARCHAR(25))
The odd thing is, I get the same PARSE error with the following statement
SELECT * FROM #table#
which is resolved by adding as temp at the end (as mentioned in my initial post), I am not sure how to do the same with the ALTER TABLE statement however.
The problem is the Data Base Query only uses the code and wraps a SELECT * FROM around it:
SELECT * FROM (<whatever your code is>)
so everything is a SELECT statement, table manipulations command would not work. Question is why you would not use the SQL executor to add the column? Everything will be executed on the cluster just like the Database nodes with the brown connections.
What you could do is just use a CAST command and create an empty variable. Question would again be what you would do with these empty variables, but you could create them
SELECT * , CAST(NULL AS BIGINT) as new_number , CAST("" AS STRING) as new_string FROM #table#
Thank you! The CAST command did the trick. The reason I am adding the empty column is so that I could populate them with a CASE command/IF statement - I will be embedding this into the CASE statement in the database query node.
EDIT: easier to just use a CASE WHEN statement to create new columns based on values of other columns
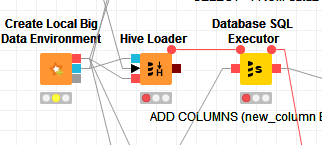
I would like to use the SQL executor but I am not sure what I would attach as an incoming pink connection. I can see in your workflow that you are utilising the variable flow ports and attaching the pink connection from the Create Local Big Data Environment, which I took from your initial reply to be for testing purposes. What would I attach it to when I want to connect to the ‘real thing’ e.g. in my example?
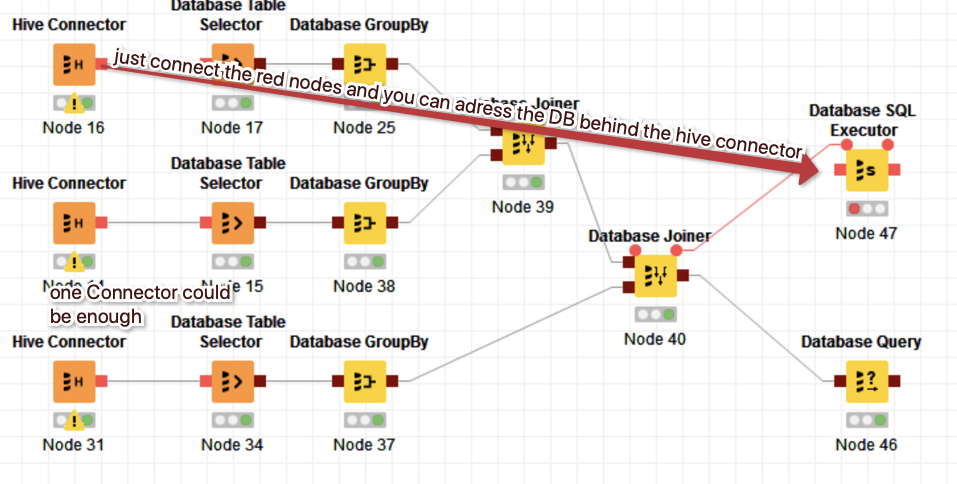
You can just connect the SQL Executor to the Hive Connector. Hive is very much like SQL with a few quirks. The SQL Executor would happily accept Hive Commands. The flow variable lines (the thin red lines with the round connectors) are there to enforce the queue (and transport information of course).

 .
. .
.
 and attaching the pink connection from the Create Local Big Data Environment, which I took from your initial reply to be for testing purposes. What would I attach it to when I want to connect to the ‘real thing’ e.g. in my example?
and attaching the pink connection from the Create Local Big Data Environment, which I took from your initial reply to be for testing purposes. What would I attach it to when I want to connect to the ‘real thing’ e.g. in my example?