Hi,
I have 2 Date columns which need to be manipulated based on non-working days. If a date is working day - keep it, else shift the date to next working day.
For example: If Day 1 if Saturday I have to shift it by 2 days to Monday. But if Monday was a bank holiday then shift it by 3 to Tuesday…
I have a main data table and Calendar table which defines if each day is a working day or not.
Any help is greatly appreciated.
Let’s check if I have understood your issue well.
You want to have a column starting from 1 which represent the working day on calendar where the counting halts on non working days?
If yes, how about filtering the holidays first and then using a Counter Generation node?
Then you can join the initial table (top port) with this new table (bottom port) on date and use left join.
This way you have a complete calendar with a column counting working days.
I created a workflow data_manipulation_based_on_non_working_day.knwf (70.9 KB)
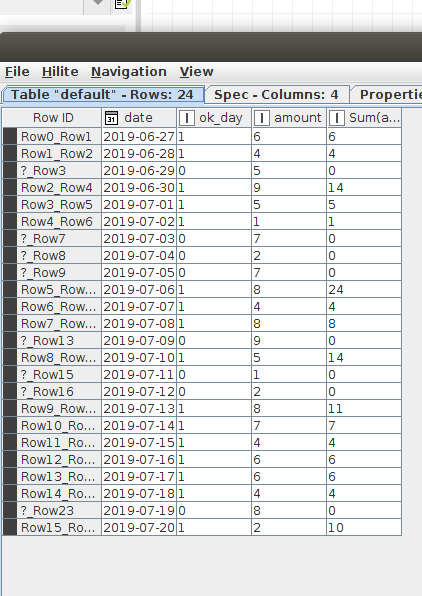
based on the tip from @armingrudd . When you have your calender there is column called ok_day that indicates if (ok_day=0) the “amount” should be shifted to the first ok_day=1. The result will look like this
Thank you both for your replies. I am working on a KPI which looks at Time to initial response and need to find the difference between 2 Date-time columns. But want to take out the duration of non-working days/hours if it falls between the 2 dates.
Apologies for not being clear enough.
Hi,
thank you for your quick response.
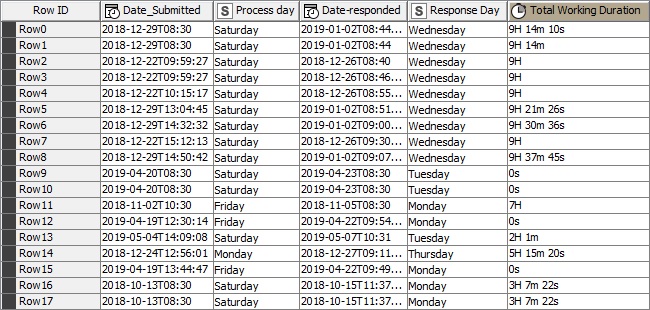
Attaching a sample Excel sheet with 2 examples of what the expected time difference is (Column F).Sample Times-forum.xlsx (11.0 KB)
OR any working day as well.
If a work was submitted 8:30 am Monday and Responded on Tuesday 10:00am, the hours to respond should be 10 hours and 30 minuted - not 25 hours and 30 minutes.
Hi,
Please could you explain why the 1000 as the maximum number of iteration in the Loop end node? I would like to understand the recursive loops better to adapt your workflow to my needs. At the moment the iterations take a bit too long with the sample data.
That’s the max number of iterations of the loop but I used a flow variable to close the loop. Date variable which becomes true when the output table from Row Filter (Node 16) is empty. Take a look at the configurations of the next Table Row to Variable node. It’s better to use a Extract Table Dimension node after Date&Time-based Row Filter (Node 11) and use number of rows plus 1 for max number of iterations.
I wonder if it is possible to run the iterations for Calender dates between Submit Date and Process Date. That would reduce the number of iterations drastically. At the moment the workflow is taking a long time to run as its looking through all of the Dates after the row filter (node 11).
I mean for each row in the main data, if the starting date and end date could be defined when the calendar data is being looped through to get the number of working days.
Example: For Submit Date- 22 -12-2018 and Process Date - 02 -01-2019, The calender looping will run between those 2 dates to count the number of working days between.
The calendar dates are filtered to contain dates from the first submit date to the last process date in the main table AND it is filtered to include just the working days. All before the loop.
The loop then checks the remaining dates from the calendar on the main table to count the working days.
Then how about the rest of the main table?
Anyway you have to loop all the dates between your first submit date and the last process date in the main tabel.
Sorry to break into your discussion but @armingrudd invited me in his post above Date manipulation based on Non-working day to do any suggestions for optimization. Well it was not so easy , instead of a recursive loop I used a chunk loop and that makes this workflow much faster (but needed more nodes). d_m_based_on_non_working_day.knwf (70.0 KB)
It just came to my mind that if the main dataset is larger then your solution takes more time since it loops over the main table instances and if the we have fewer records then it does the task much faster.
Still in both cases my solution is slower because of the Column Expressions.
Here I have a suggestion for you @HansS:
You take my workflow and follow the same approach I have used and just optimize it to reduce the execution time and I take yours to do some modification keeping the same approach you have used.
Then we can create a master workflow which uses any solution that fits better to the case.



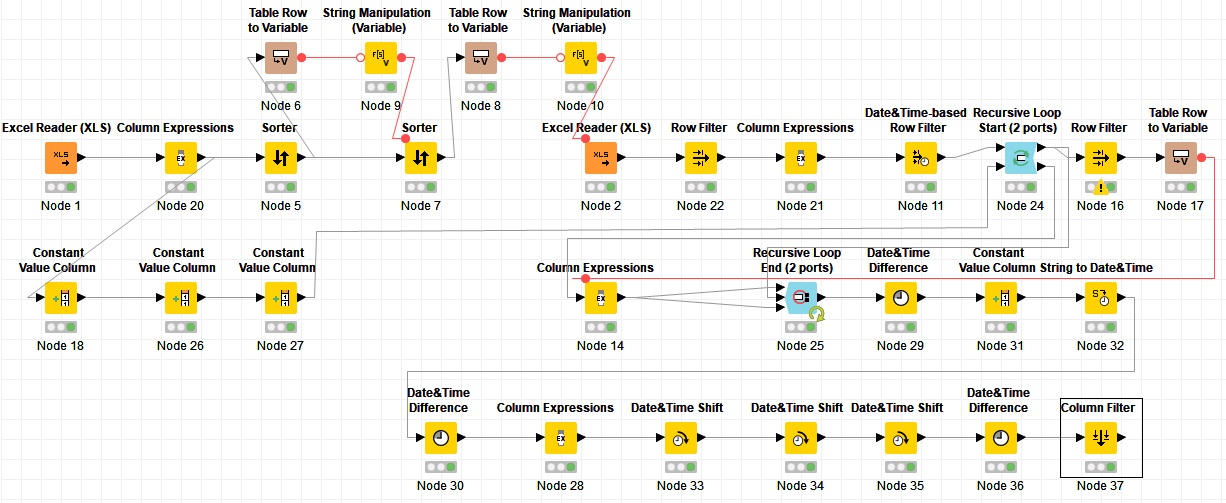


 , instead of a recursive loop I used a chunk loop and that makes this workflow much faster (but needed more nodes).
, instead of a recursive loop I used a chunk loop and that makes this workflow much faster (but needed more nodes).
