Maybe it’s possible already but I’ve not spotted how.
I’ve been trying to optimise some SQL queries that I’m running in the new DB Reader node and would like to be able to get a more responsive update on progress from the DB Reader node.
Would it be possible to every n rows extracted from the ResultSet or written to the output table to update the node progress to indicate the number of results processed? At the moment I only seem to be able to get a status indicating it is running.
We’ve been having some issues since needing to rely on VPN and it would be helpful if a user could get some feel for whether something has gone wrong or if it’s just a slow process. This would help somewhat towards that.
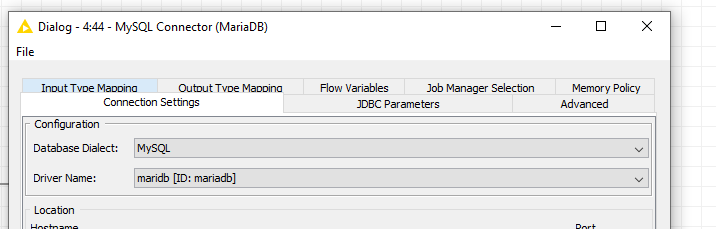
If I do a simple SELECT * FROM schema.table (mariadb using the mysql connection node and fetch size of 1000) I can observe the following behaviour.
Run the DB Reader now:
Monitoring the MariaDB server I see the connection state switch between Sending data and writing to net. While I see a live connection the node reports ‘Executing - Executing query…’
When the DB server shows the query has finished only then do I see some progress reporting the number of rows read
When running my more complex query I only ever see ‘Executing - Executing query…’ as the progress text.
If I follow along in task manager step 1 corresponds with high network traffic and step 2 shows none/minimal.
Seems I’ve been operating under an incorrect assumption on what is happening. I had been thinking I could see progress in a similar way to this trivial demo:
@webstar Yes indeed that would help identify if the connection/session provided by the upstream node is active and helps to check prior to execution. Thisis a good tip for me to pass on to people thank you.
Though what I’m really after is getting as feel for what the node is currently up to. I’ve had a few complaints of ‘this hasn’t finished and it’s been 3 hours’ then later followed up with ‘it’s done now’. It’s hard for a user to tell after starting whether they are in a long processing issue or a the connection actually dropped and the KNIME node shouldn’t actually be trying to process anymore - for this query anyway as we’re not getting the processed rows feedback that some queries are giving.
@ipazin I’m going to be off for a week, if no ones popped in with an answer by the time I’m back I think I’ll have a look at the code and see if I can spot anything. More out of curiosity than a belief there’s something wrong.
when fetching data from the database KNIME is basically doing the same as you in your code example. The problem is that the MySQL/MariaDB driver by default either retrieves all rows into memory before returning the ResultSet or one by one (see ResultSet in the MySQL Connector documentation).
KNIME tries to report as much progress as possible but once the query is send to the database (stat.executeQuery()) all we can do is wait for the ResultSet to return. Let me know if you have a good idea to provide more progress here using the JDBC API.
One other difference is that we do not provide percentage based progress since we do not know in advance how many rows will be send by the database and executing a count on the query first might cause a lot of computational overhead. That is why we show the processed rows only in the tool tip and not via the nodes progress bar.
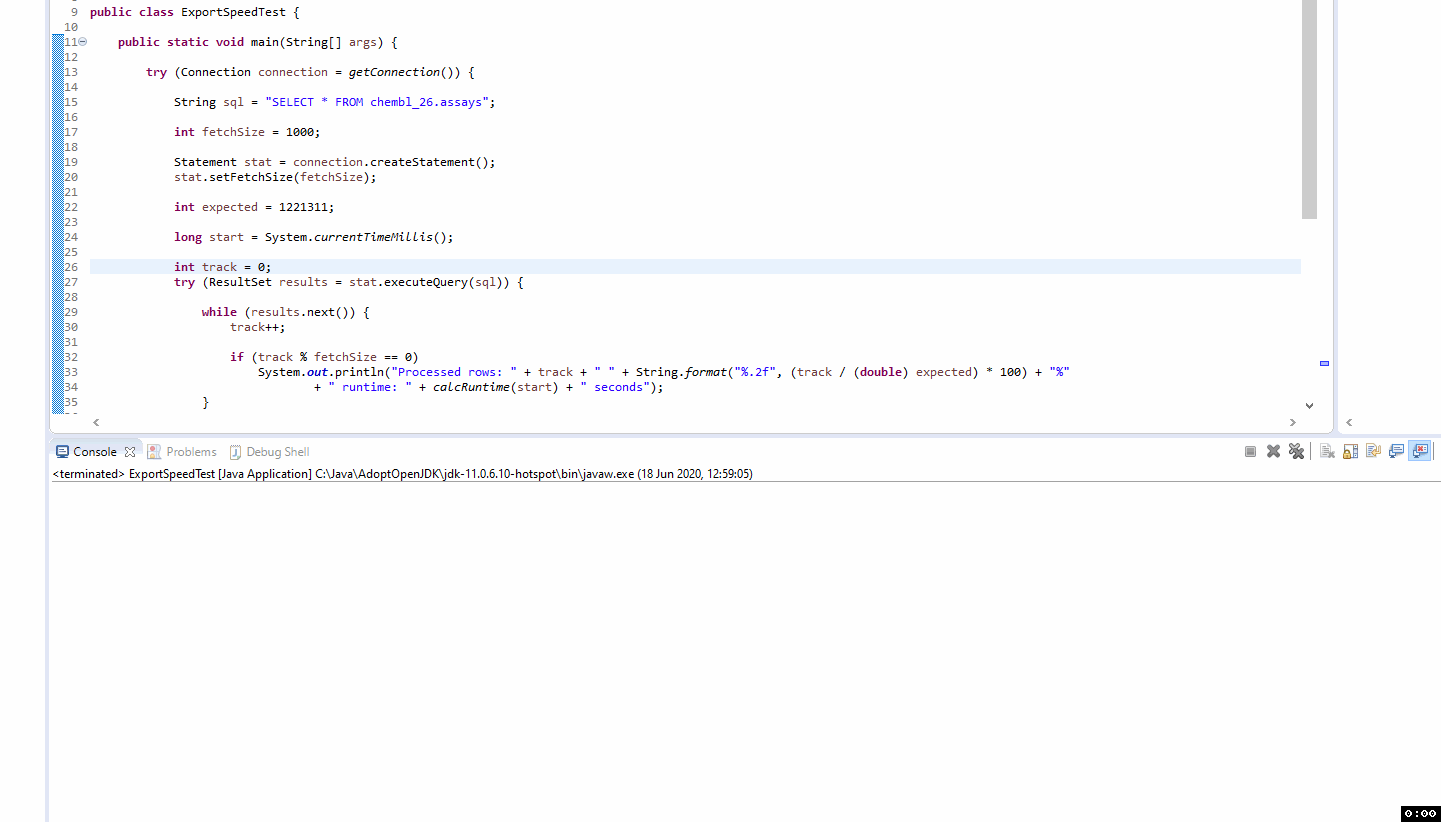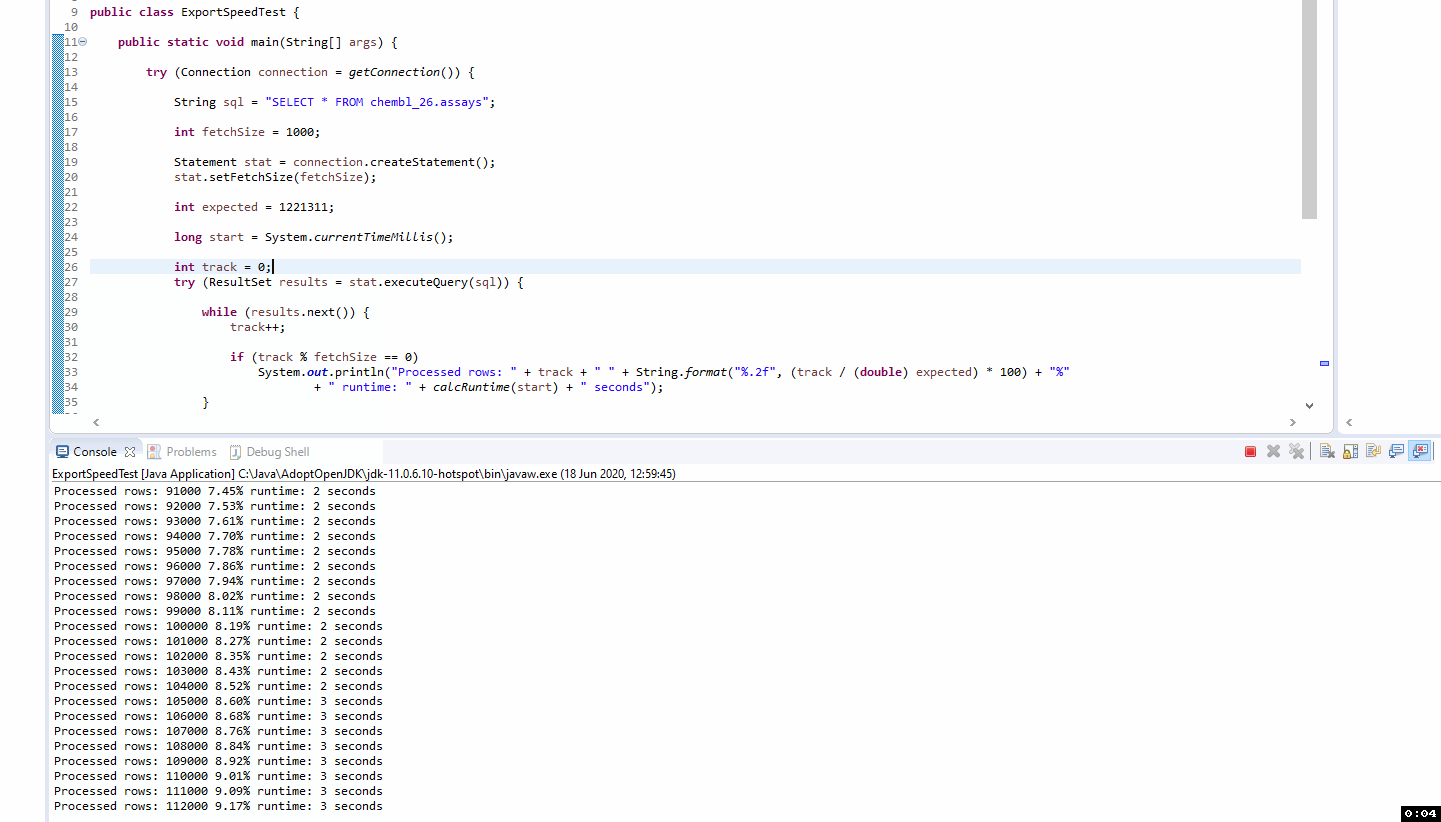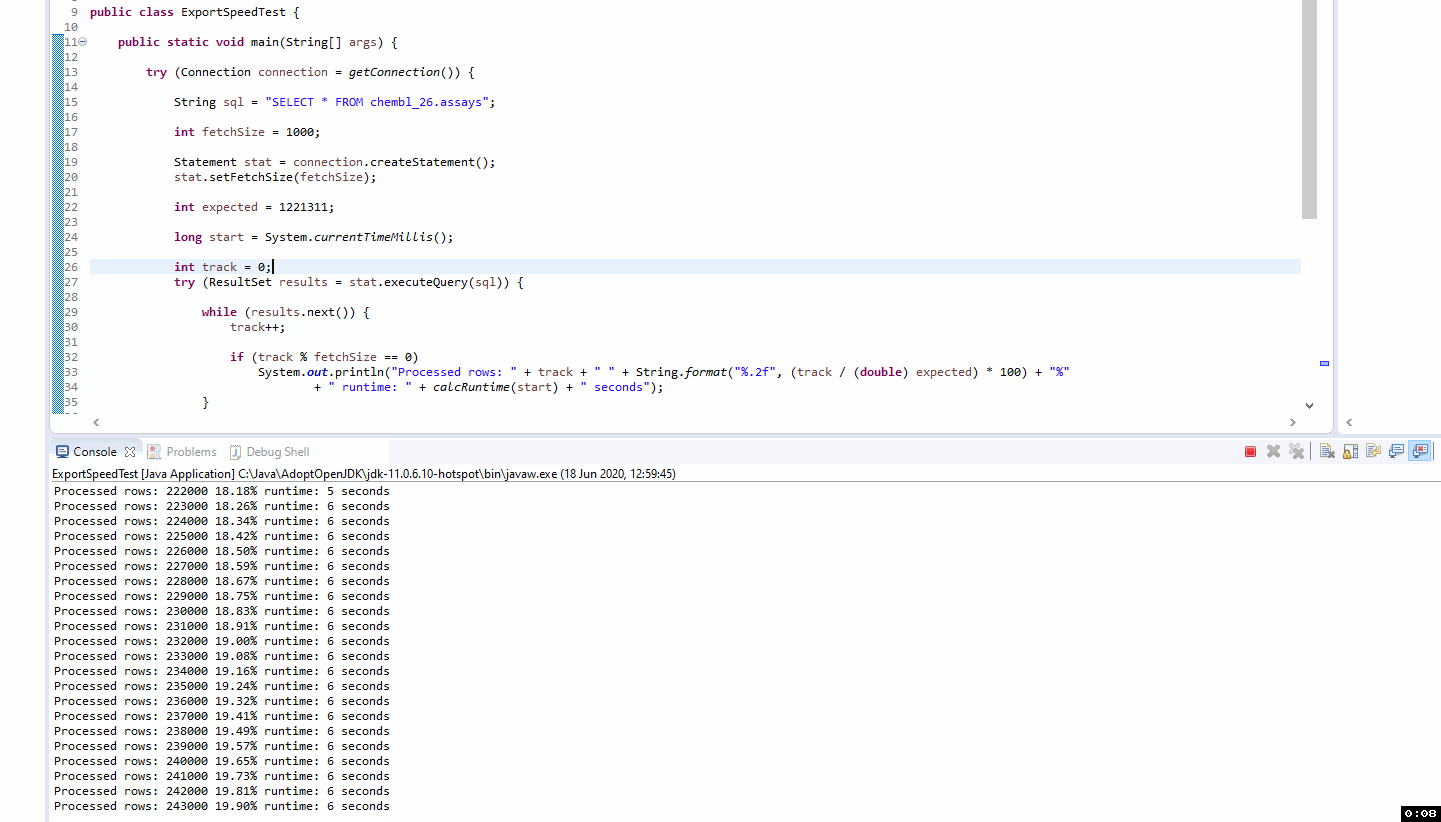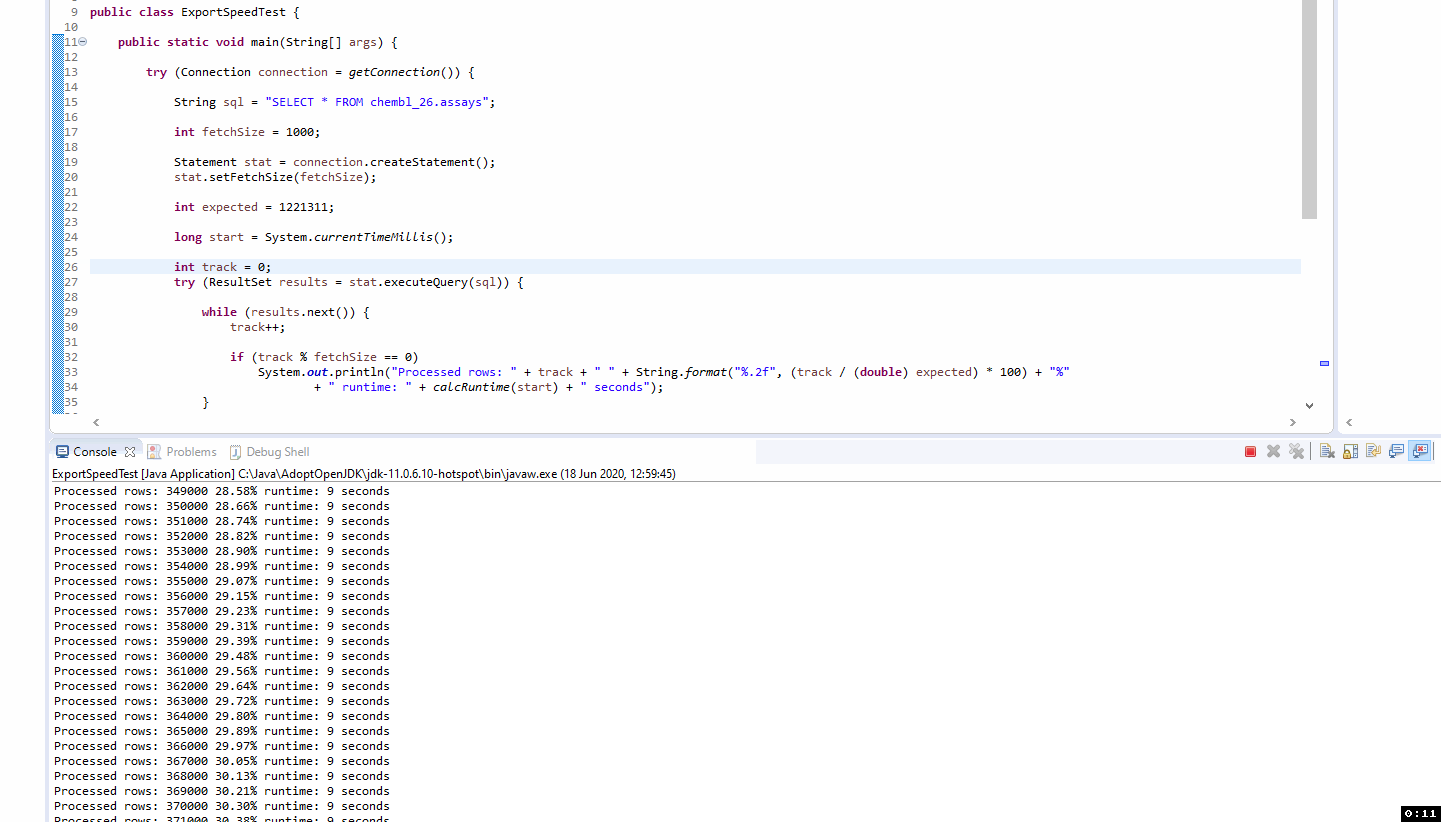
Ah I see that explains the behaviour I’m seeing thanks for the info. I should read up a bit better, I thought the fetch size was going to make it process 1000 then another 1000 rather than retrieve all.
Yes of course w.r.t to the progress, that was only there to help me with debugging a specific query (I wanted to predict runtime based on progress).
If I come up with anything that helps in the situations we’re seeing I’ll feed back what we come up with. Though in this case changing the sql query has resolved the long exefution issue as it now returns within 5 minutes so it less of a concern.
Edit: looking at the docs you listed I also need to use useCursorFetch=true on my connection to batch the results if I want a fetch size greater than 1
You can set the useCursorFetch parameter via the JDBC Parameters tab in the connector node dialog. However I’m not sure if this will then result in more resources being required on the DB site. Haven’t found anything reliable so far but some hints that this results in MySQL creating a temporary table for the result to enable the cursor moving.
Bye
Tobias
So the difference in behaviour between the Java demo and KNIME is down to MySQL vs MariaDB JDBC connectors.
New observations:
useCursorFetch=true makes the query slower (as expected) but does appear to start providing feedback before without reading the whole table into memory
Setting the fetch size to -2147483648 which should enable streaming doesn’t seem to change the behaviour
The MariaDB JDBC driver seems to honour the fetch size and gives immediate feedback
It looks like the MariaDB JDBC driver has some additional implementation around fetch size that isn’t available in the MySQL version. I’ve not been able to find many details on it though. This doesn’t seem to noticeably impact speed on this simple query.
I can get the improvement I was by adding the MariaDB driver in some instances (depends on the query).
Hi Sam,
maybe instead of only shipping the driver we could create a dedicated MariaDB Connector node that comes with the driver but reuses a lot of the MySQL functionality. This way we could address some MariaDB specialties. However I don’t know if there are enough to justify its own connector. Need to look into this a bit more. What do you think?
Thanks a lot for all your feedback. This is very much appreciated and helps us to improve KNIME Analytics Platform.
Bye
Tobias
I think this thread shows I may not be in the best position to comment on that
I suspect you’re right and there’s probably not enough different to justify a separate connector over simply having another option in the drop down for the Driver Name.
Though maybe there’s some settings that have different defaults between MySQL and MariaDB that wouldn’t be obvious if switching? For example when using the MariaDB connector I get a Transaction and JDBC Parameter section in the Advanced tab I don’t see when using MySQL connector. Though I suspect in a lot of cases the Advanced tab isn’t looked at.

 So the difference in behaviour between the Java demo and KNIME is down to MySQL vs MariaDB JDBC connectors.
So the difference in behaviour between the Java demo and KNIME is down to MySQL vs MariaDB JDBC connectors.