Hi @summer_le , 800k records is not a lot, and in fact, if the column that contains these IDs is indexed, then it won’t scan/check the whole table, it will target only these 120k records (hence why I said that the performance can also depend on your WHERE conditions).
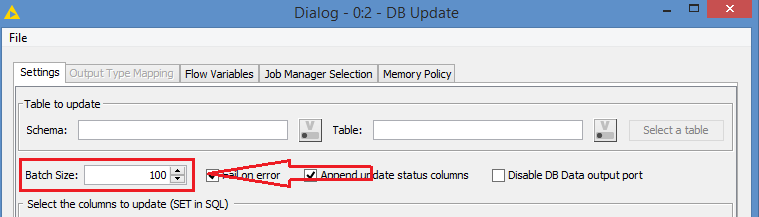
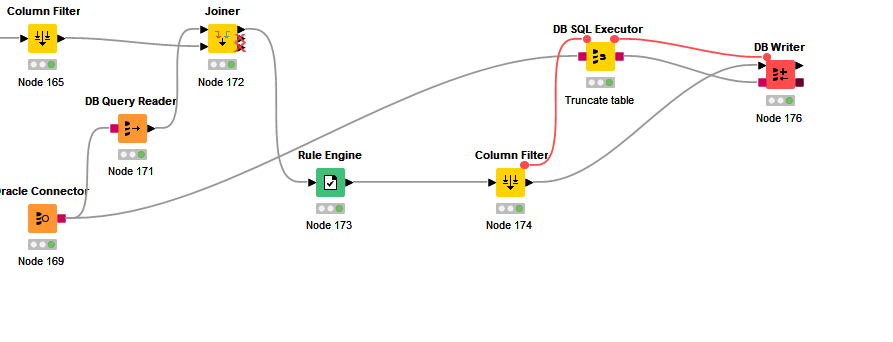
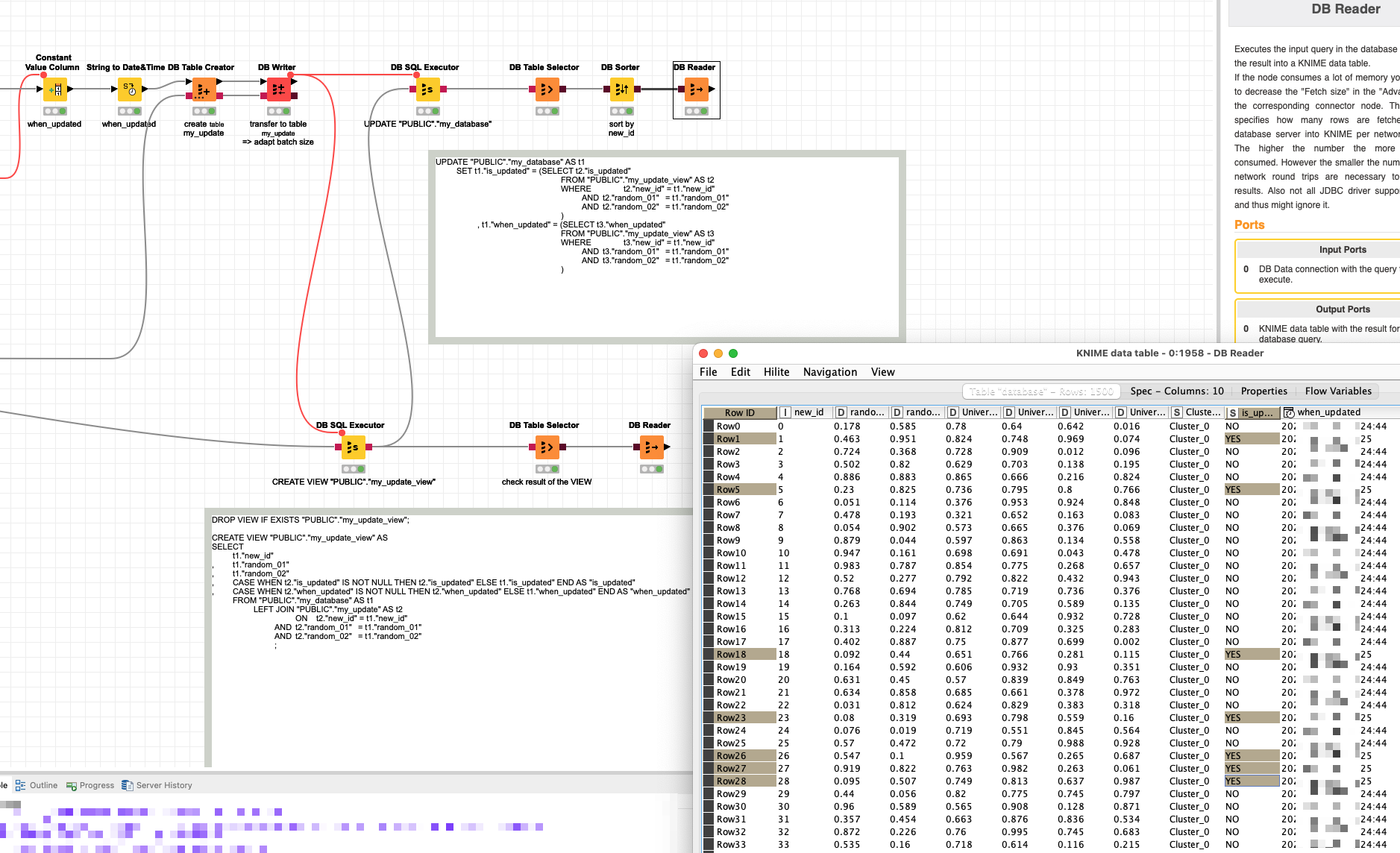
Quite frankly, I have never used the DB Update node. I usually execute an SQL with the DB SQL Executor node, and if I have to do data manipulation beforehand in Knime, I would load the manipulated data into a temporary table on the DB server, and then run the UPDATE from that temporary table.
So, I’m not entirely sure how the DB Update node behaves in the background. I wonder also if your connection did not expire if the DB Update took so long.
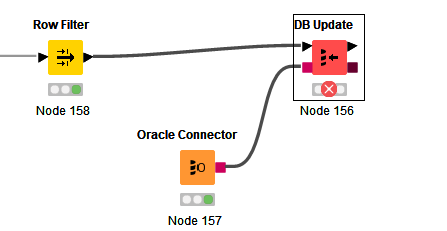
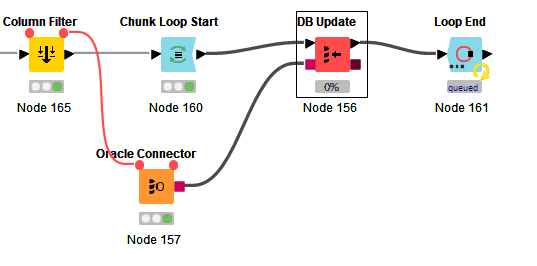
The fact that you were able to run the DB Update with small batch (Row Filter), it’s probably better to keep doing it that way, meaning using the Loop instead of batching inside the DB Update.
With the Loop, it would look something like this:
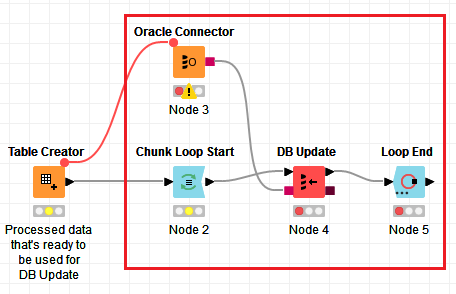
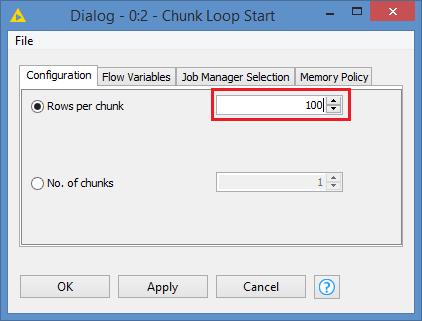
So, instead of the Row Filter, you would use a Chunk Loop.
An additional note is that it’s also better to connect your DB Connector node (Oracle Connector) to the last node of the data processing (basically the node that’s before your Row Filter), that way you are making sure that the DB connection will be initiated as late as possible, which is basically once your data is processed and ready to be used with the DB. If you start your DB connection too early, it will remain idle during the time that Knime is processing your data and can expire if data processing takes too long. There is absolutely no advantage to establish the DB connection early.
Also, in order to optimize the batch, you may first try with the Row Filter as you did, and adjust, may be push from 100 to 200, then to 500, to see if 500 is OK per batch, and once you get that magic number, you can then configure the batch size in the Chunk Loop - with a size of 100, you will be hitting the DB 5 times more than with a size of 500.
Ultimately, if you do have SQL knowledge, it might be better to just load your processed data in a temp table on the DB Server, and then run the UPDATE statement manually via the DB SQL Executor, OR load the processed data to a physical temporary table on the DB Server, and then connect to your DB via the Oracle DB client and run your UPDATE statement there.