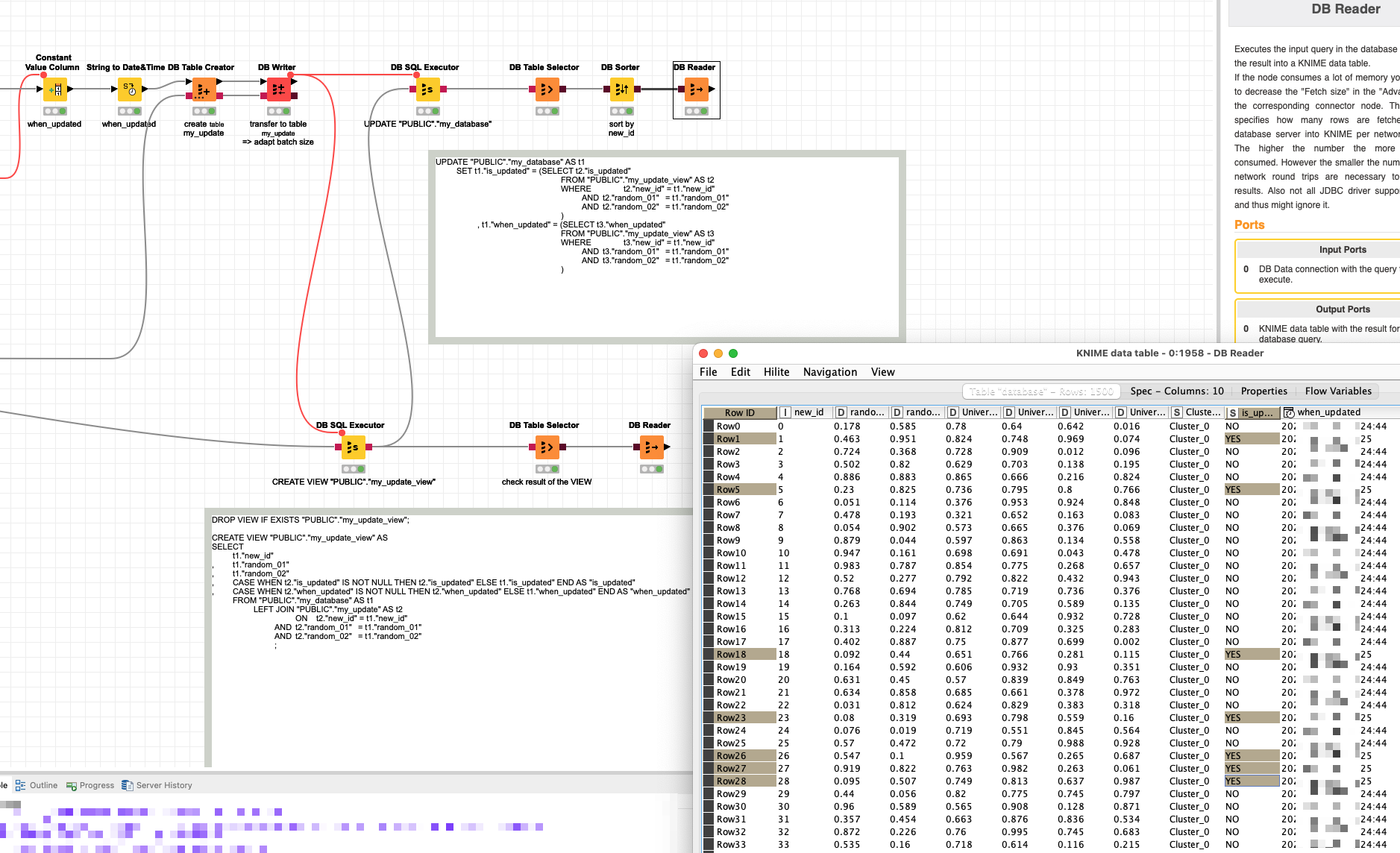
@summer_le I create an example how to UPDATE data within the database. In this case a H2 Db. The exact syntax might differ if you use it on another Db system.
In this case in oder for the UPDATE … SET syntax to work a VIEW is being created that would do a LEFT JOIN between the old and the new data (of course you could just use that also).